






 本文为大家讲解如何将API 端点请求的响应速度提高50倍的。
本文为大家讲解如何将API 端点请求的响应速度提高50倍的。

 场景
主要涉及到四种记录信息:
场景
主要涉及到四种记录信息:
- users 用户记录;
- subscriptions 订阅关系记录;
- subscriber_lists 订阅信息记录;
- documents 文档记录。
{ "title": "Harry Potter", "author": "JK Rowling" ...}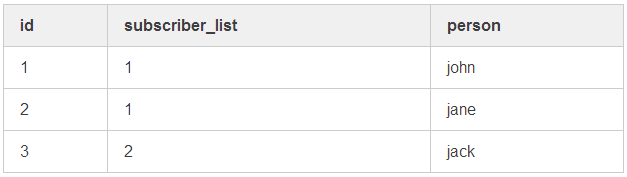
 我们首先要清楚的是,如果订阅信息表中存在用户待订阅的信息,则直接订阅;如果没有,则需要在此表中新建一条记录然后再订阅。
如果文档发生变更,必须找到与之匹配的订阅关系,然后通过邮件通知符合条件的订阅用户。
如果用户希望当标题为《哈利 · 波特》或《暮光之城》的文档更新时能够收到通知,他们就需要在订阅关系表中插入一条订阅信息表(subscriber_list)中 id 为 1 的记录。
因为我们不想让订阅信息列表存在重复的记录,我们就需要找到一个与用户想要订阅的属性完全匹配的订阅信息。
输入:
我们首先要清楚的是,如果订阅信息表中存在用户待订阅的信息,则直接订阅;如果没有,则需要在此表中新建一条记录然后再订阅。
如果文档发生变更,必须找到与之匹配的订阅关系,然后通过邮件通知符合条件的订阅用户。
如果用户希望当标题为《哈利 · 波特》或《暮光之城》的文档更新时能够收到通知,他们就需要在订阅关系表中插入一条订阅信息表(subscriber_list)中 id 为 1 的记录。
因为我们不想让订阅信息列表存在重复的记录,我们就需要找到一个与用户想要订阅的属性完全匹配的订阅信息。
输入:
{"title":["Harry Potter","Twilight"]}{ subscriber_list: 1 } 现有的解决方案
看看下面的 ruby (rails) 代码:
现有的解决方案
看看下面的 ruby (rails) 代码:
def find_subscriber_list(query) return [] unless query.present? subscriber_lists = SubscriberList.where("ARRAY(SELECT json_object_keys(attributes)) = Array[:keys]", keys: query.keys) subscriber_lists.select do |subscriber_list| subscriber_list.attributes.all? do |key, attributes| query_values = query[key] list_values = attributes[key] query_values.sort == list_values.sort end endend 事情悄悄发生了改变
因为数据量较小,所以在这个阶段代码优化意义不大。
目前阶段只有几百个订阅信息记录,他们的属性差异较大,因此大多数工作都可以让 postgres 完成,ruby 代码要执行的操作很少。
此时查询正常,请求的响应也比较迅速。
然而,随着很多新的订阅记录列表不断创建,如果多个查询条件都使用一个键:
事情悄悄发生了改变
因为数据量较小,所以在这个阶段代码优化意义不大。
目前阶段只有几百个订阅信息记录,他们的属性差异较大,因此大多数工作都可以让 postgres 完成,ruby 代码要执行的操作很少。
此时查询正常,请求的响应也比较迅速。
然而,随着很多新的订阅记录列表不断创建,如果多个查询条件都使用一个键:
{ "tag": ["a12", "c32", "b521", "b212", "d230", "z291", ...] } 本可以有更简单的解决方案
在某些场景下,提升这种查询的性能更容易些。
类似 Mongodb 这种非关系数据库,postgres 高版本也开始支持 jsonb 数据类型,这些都为在数据库内部实现这种查询提供了方便,而且查询速度还更快。
想了解在 postgres db 中使用 jsonb 数据类型代替 json 的查询性能差异,请参见这篇文章的
性能部分
(https://coussej.github.io/2016/01/14/Replacing-EAV-with-JSONB-in-PostgreSQL/)。
然而,正如上文提到的那样,我们大概有 6 个月不能升级数据库的版本,而且此时查询变得越来越慢。
我本应该学习更多数据库和查询优化方面的知识,但我却知之甚少,这就更是雪上加霜。
本可以有更简单的解决方案
在某些场景下,提升这种查询的性能更容易些。
类似 Mongodb 这种非关系数据库,postgres 高版本也开始支持 jsonb 数据类型,这些都为在数据库内部实现这种查询提供了方便,而且查询速度还更快。
想了解在 postgres db 中使用 jsonb 数据类型代替 json 的查询性能差异,请参见这篇文章的
性能部分
(https://coussej.github.io/2016/01/14/Replacing-EAV-with-JSONB-in-PostgreSQL/)。
然而,正如上文提到的那样,我们大概有 6 个月不能升级数据库的版本,而且此时查询变得越来越慢。
我本应该学习更多数据库和查询优化方面的知识,但我却知之甚少,这就更是雪上加霜。
 提速 50 倍
接下来我将分享我的黑科技。
我们优化的目标是将查询任务转移到 postgres 中,从而提高性能。
我想到的解决方式是生成订阅信息列表属性( attributes)的摘要,然后查询时匹配摘要即可。
我在订阅信息列表的表中新增一列属性摘要(attributes_digest)。
该字段包含订阅信息列表 attributes 列的散列值:
提速 50 倍
接下来我将分享我的黑科技。
我们优化的目标是将查询任务转移到 postgres 中,从而提高性能。
我想到的解决方式是生成订阅信息列表属性( attributes)的摘要,然后查询时匹配摘要即可。
我在订阅信息列表的表中新增一列属性摘要(attributes_digest)。
该字段包含订阅信息列表 attributes 列的散列值:
class AddAttributesDigestToSubscriberLists def change add_column :subscriber_lists, :attributes_digest, :string endendclass AddIndexesToSubscriberListDigest ActiveRecord::Migration[5.2]disable_ddl_transaction!def changeadd_index :subscriber_lists,
:attributes_digest,algorithm: :concurrentlyendendDigest::SHA256.hexdigest(normalize_hash(hash))# in SubscriberList classbefore_save do self.attributes_digest = HashDigest.new(attributes).generateend# migrationclass AddDigestToExistingSubscriberLists disable_ddl_transaction! def change SubscriberList.where("attributes_digest IS NULL").find_each do |list| list.attributes_digest = HashDigest.new(list.attributes).generate list.save! end endenddef find_subscriber_list(query) digest = HashDigest.new(query).generate SubscriberList.find_by_attributes_digest(digest)end 验证效果
我通过一个基准测试来验证性能改进的效果。
优化之前,99% 的请求在 3161ms 完成,而优化之后查询耗时降到了 66ms,快了近50倍。
我本地创建了2万五千多条订阅者记录,并使用基础测试工具
ab
对优化前后的查询进行测试。
验证效果
我通过一个基准测试来验证性能改进的效果。
优化之前,99% 的请求在 3161ms 完成,而优化之后查询耗时降到了 66ms,快了近50倍。
我本地创建了2万五千多条订阅者记录,并使用基础测试工具
ab
对优化前后的查询进行测试。
ab -t 10 -r -c 5 /endpoint?tag[]=a12,b23,c34,d45...
基准测试结果
优化之前的查询的性能非常差:完成 18 次请求 .请求的比例和耗时(单位:毫秒)50% 251866% 254975% 274480% 287390% 313895% 316198% 316199% 3161100% 3161 (慢请求的耗时)完成 1167 次请求.请求的比例和耗时(单位:毫秒)50% 4166% 4575% 4780% 4990% 5395% 5798% 6399% 66100% 598 (慢请求的耗时) 总结
感谢 Kevin,他是一个高级开发人员,帮我审查代码和制定上线计划。
这可能不是解决这个问题的最正统的办法,但是如果你也遇到了类似的情况,希望本文可以帮助到你。
另外,我也很想知道其他人是否有解决类似问题的不同方案。
原文:https://bilbof.com/2019/09/18/improving-api-endpoint-performance.html
作者:作者叫 Bill Franklin,是一名来自伦敦软件工程师。他最初在一家网络安全组织工作,该组织也是世界上最大的出版商,然后去了 ChartMogul 工作,从 2018 年就开始在 Government Digital Service(GDS) 工作。作者在业余时间在牛津大学学习软件工程。
译者:明明如月,知名互联网公司 Java 高级开发工程师,CSDN 博客专家。
总结
感谢 Kevin,他是一个高级开发人员,帮我审查代码和制定上线计划。
这可能不是解决这个问题的最正统的办法,但是如果你也遇到了类似的情况,希望本文可以帮助到你。
另外,我也很想知道其他人是否有解决类似问题的不同方案。
原文:https://bilbof.com/2019/09/18/improving-api-endpoint-performance.html
作者:作者叫 Bill Franklin,是一名来自伦敦软件工程师。他最初在一家网络安全组织工作,该组织也是世界上最大的出版商,然后去了 ChartMogul 工作,从 2018 年就开始在 Government Digital Service(GDS) 工作。作者在业余时间在牛津大学学习软件工程。
译者:明明如月,知名互联网公司 Java 高级开发工程师,CSDN 博客专家。

热 文 推 荐
☞对话阿里云叔同: 释放云价值,让容器成为“普适”技术 ☞HTML + CSS 为何得不到编程界的认可? ☞“弃用 Google AMP! ” ☞20行 Python 代码爬取王者荣耀全英雄皮肤 | 原力计划 ☞ 操作系统兴衰史 ☞ 我在华为做外包的真实经历☞搞定面试算法系列 | 分治算法三步走

 你点的每个“在看”,我都认真当成了喜欢
你点的每个“在看”,我都认真当成了喜欢















 2517
2517











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









