





旗鼓相当的对手,吗?

新建Excel文件
之所以讲这个功能,是因为有时候我们学习新知识时,想自己动手实验一下,但却苦于手头没有现成的数据。
如果靠纯手动新建一个Excel,再填充内容,会显得比较麻烦,所以可使用如下方式新建一份数据。
import pandas as pdimport numpy as npdf = pd.DataFrame({'姓名': ['鸣人', '佐助', '小樱', '鹿丸', '丁次', '井野'], '语文': np.random.randint(60, 100, 6), '数学': np.random.randint(50, 100, 6), '英语': np.random.randint(50, 100, 6), '物理': np.random.randint(60, 100, 6), '化学': np.random.randint(60, 100, 6)})df = df.set_index('姓名')df.to_excel('./新建文件.xlsx')运行上面代码后,结果如下:
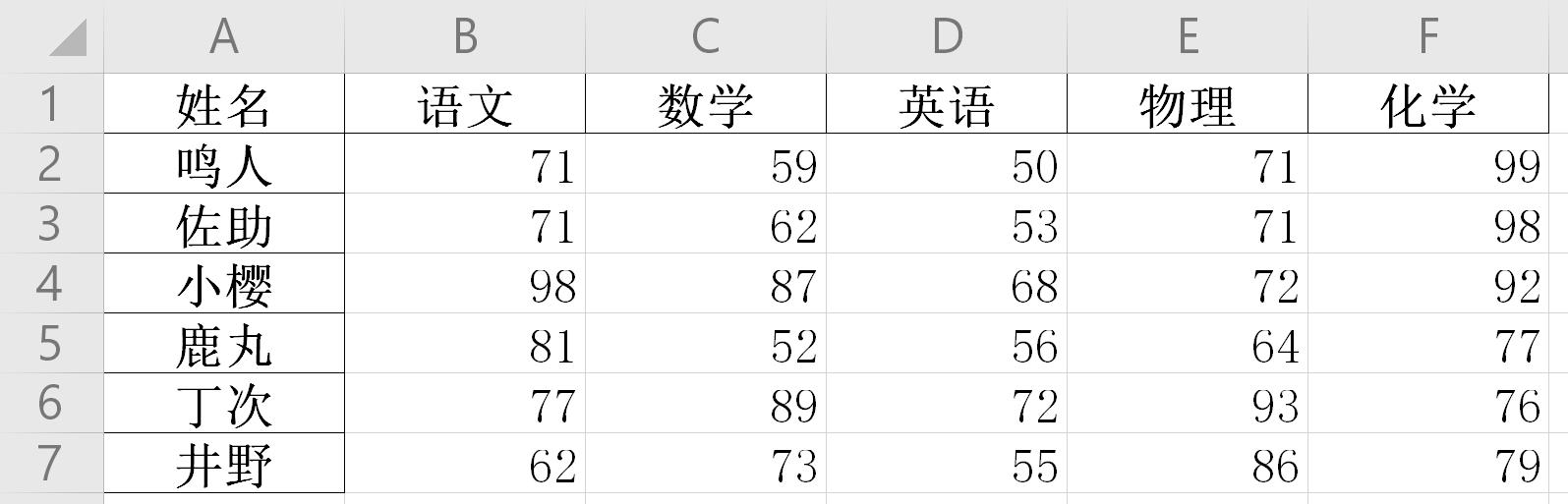
新建文件.xlsx
用pandas生成的Excel文件,表头和索引会自动加粗。
普通排序
将下面数据,按成绩从高往低排序:
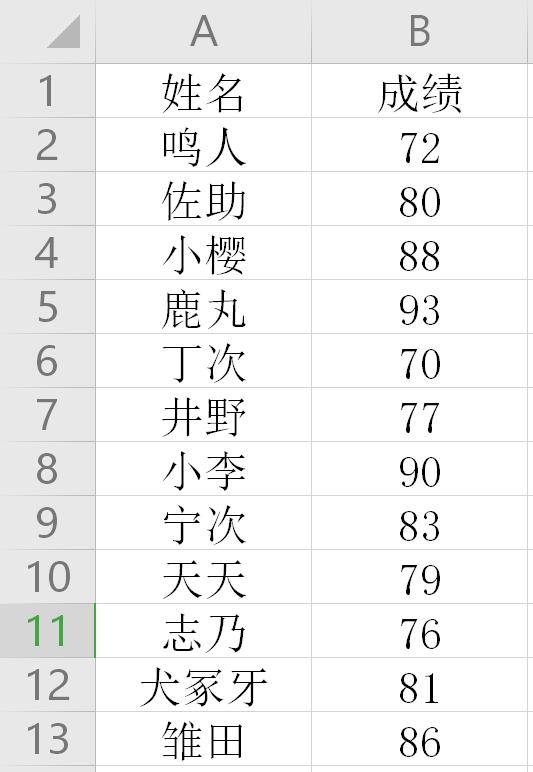
学生成绩.xlsx
Excel操作:
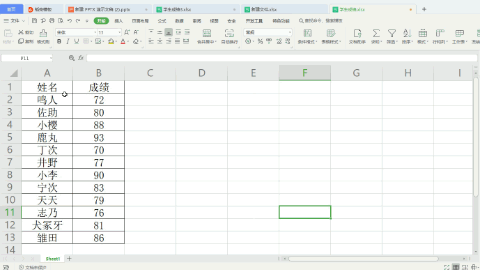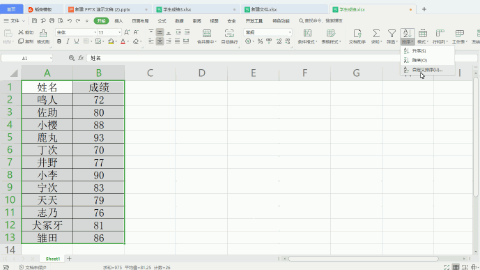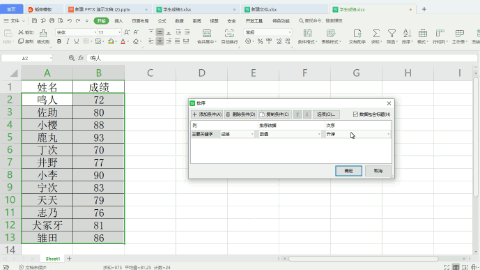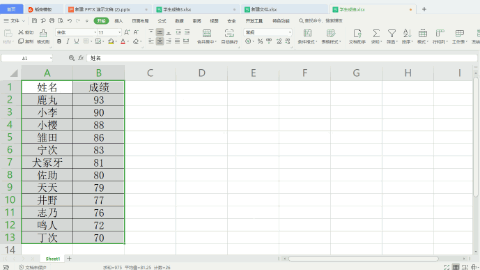
Python操作:
import pandas as pddf = pd.read_excel('./学生成绩.xlsx', index_col='姓名')df.sort_values(by='成绩', ascending=False, inplace=True)print(df)参数解释:
- by:根据哪一列进行排序
- ascending:True表示升序,False表示降序,默认为True
- inplace:True表示在原DataFrame上修改,False表示返回一个新的DataFrame,默认为False
运行上述代码后,结果如下:
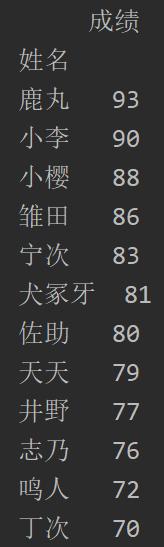
忽略表头的不对齐,Pycharm默认显示就这样。
多重排序
现在数据如下,并要把男女生成绩分开排序,即先按男女生排序,再按成绩排序。
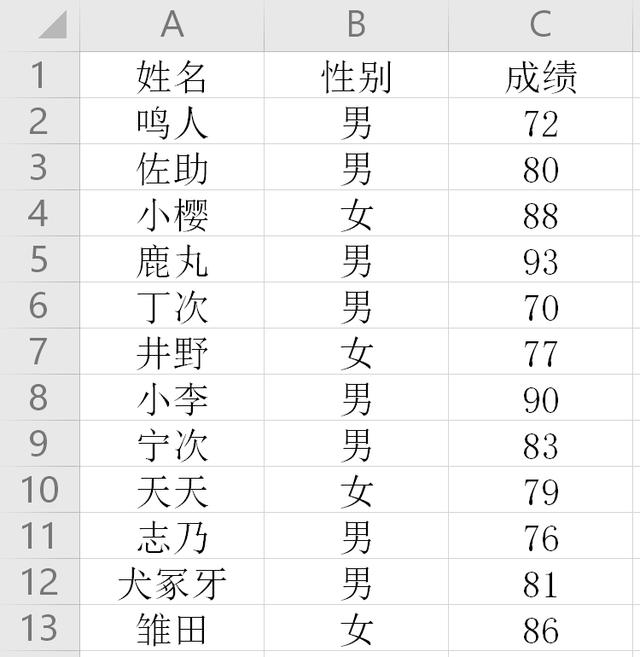
学生成绩2.xlsx
Excel操作:
Python操作:
import pandas as pddf = pd.read_excel('./学生成绩2.xlsx', index_col='姓名')df.sort_values(by=['性别', '成绩'], ascending=[False, False], inplace=True)print(df)与普通排序的区别在于,将“性别”和“成绩”作为两个元素,组成一个列表传给参数by,其对应的排序方式,也组成一个列表传给参数ascending,如果排序方式一样,可以只传False,但为了看上去好理解,我这里就写两个False组成一个列表。
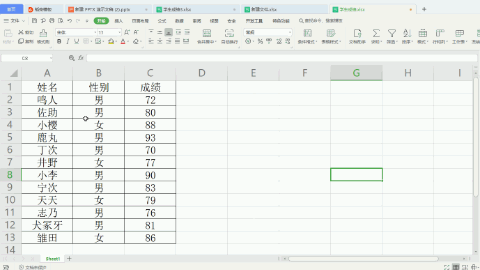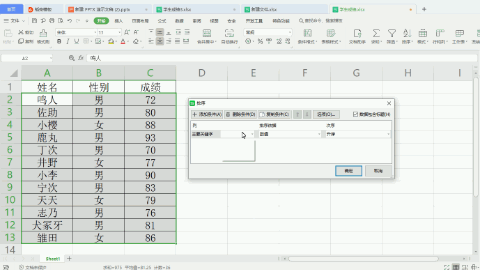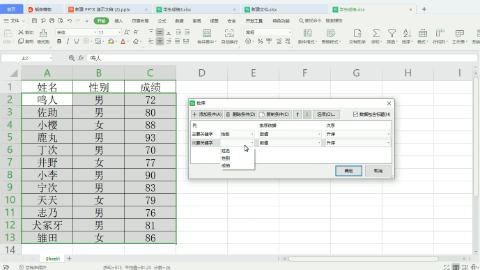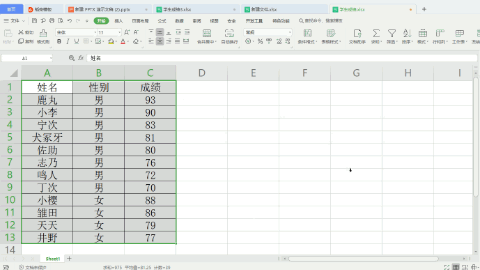
运行上面代码后,结果如下:
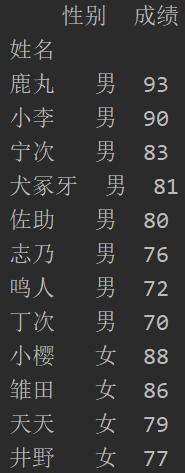
另外需要注意的是,在Excel中对字符进行排序时,是按照拼音来的,所以想要男在女前,应选择升序。而在Python3却使用了降序,是因为根据字符的Unicode值进行排序的,可用内置函数ord()查看:
print(ord('男')) # 30007print(ord('女')) # 22899数据筛选
从下面的数据中,筛选出语文成绩在60到70之间(不包括70),但数学成绩在60以下(不包括60)的学生。
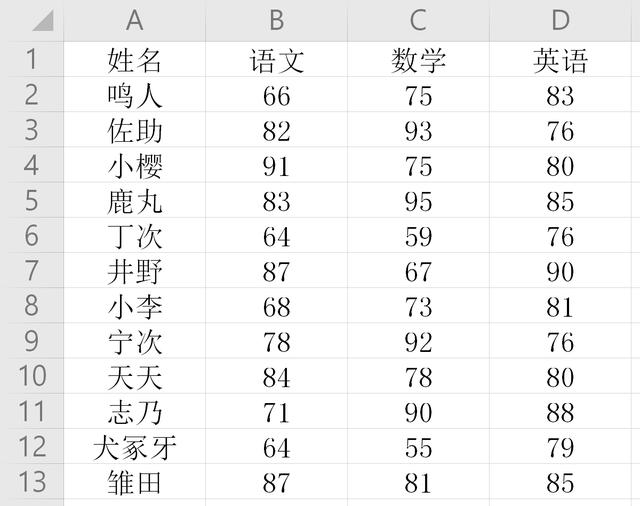
学生成绩3.xlsx
Excel操作:
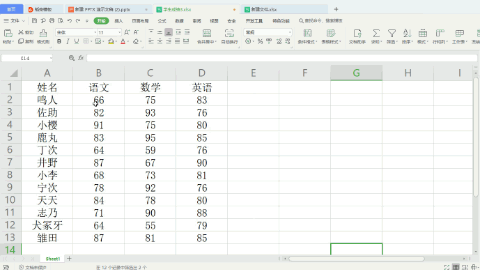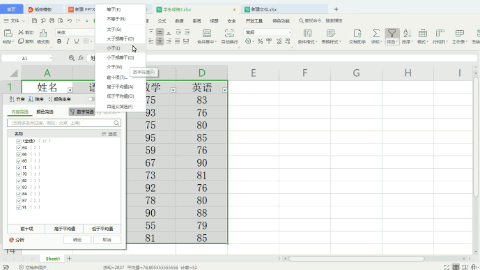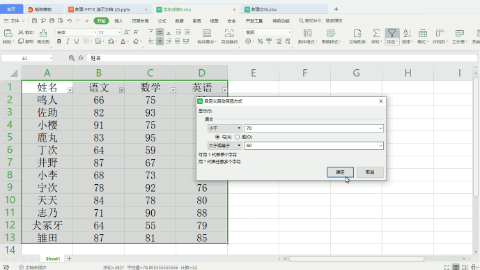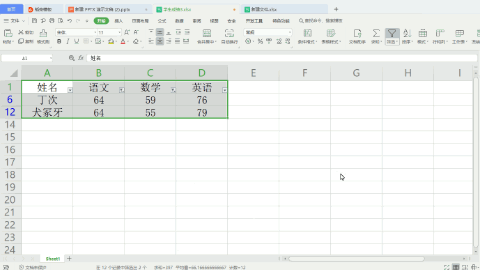
Python操作:
import pandas as pddef condition1(x): return 60<=x<70def condition2(x): return x<60df = pd.read_excel('./学生成绩3.xlsx', index_col='姓名')df = df.loc[df.语文.apply(condition1)].loc[df.数学.apply(condition2)]print(df)先定义两个函数,用来实现相应的筛选功能。然后再用df.语文(也可写df['语文'])取出语文这一列数据(Series类型),再调用apply方法,将事先定义好的函数作为参数传入,完成语文成绩的筛选,然后同样的方法,再对数学成绩进行筛选。
运行上面代码后,结果如下:
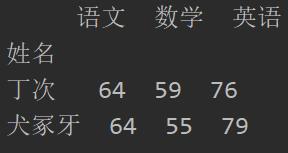
最后我猜,肯定会有人认为,使用Python不见得比使用Excel方便。主要原因是,从视觉效果上来看,有时间敲这些代码,还不如直接使用Excel操作,但其实并不是这样,虽然代码看上去似乎有点多,但如果熟练的话,几乎就是打每个单词的前几个字母,然后按Tab键自动补全即可, 实际敲的代码并不多。
还有一点就是,使用Python有点一劳永逸的味道,因为一旦写好了针对某个功能的代码,如果后面需要再次使用,只需要改一两个关键值即可,比如将最后一个例子中的数学成绩改成小于70,就只需将60改成70即可,如果使用Excel操作的话,还需要再点点点好几下,冗余操作比较多。当然,如果想要实现更复杂操作的话,Python的优势会更加明显,这个以后再另起一篇文章说。
关注微信公众号“Python小镇”,发现更多干货知识!















 153
153











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









