







druid
特点
Apache Druid是一个高性能的实时分析型数据库
云原生、流原生的分析型数据库
Druid专为需要快速数据查询与摄入的工作流程而设计,在即时数据可见性、即席查询、运营分析以及高并发等方面表现非常出色。在实际中众多场景下数据仓库解决方案中,可以考虑将Druid当做一种开源的替代解决方案。
可轻松与现有的数据管道进行集成
Druid原生支持从Kafka、Amazon Kinesis等消息总线中流式的消费数据,也同时支持从HDFS、Amazon S3等存储服务中批量的加载数据文件。
较传统方案提升近百倍的效率
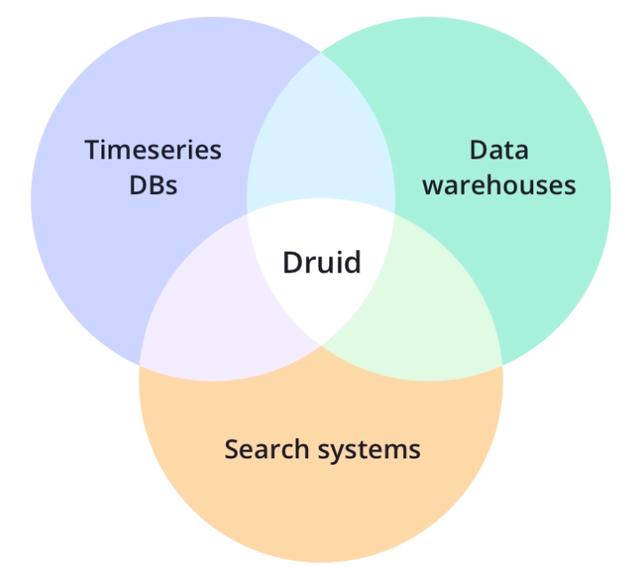
Druid创新地在架构设计上吸收和结合了数据仓库、时序数据库以及检索系统)的优势,在已经完成的基准测试中展现出来的性能远远超过数据摄入与查询的传统解决方案。
解锁了一种新型的工作流程
Druid为点击流、APM、供应链、网络监测、市场营销以及其他事件驱动类型的数据分析解锁了一种新型的查询与工作流程,它专为实时和历史数据高效快速的即席查询而设计。
可部署在AWS/GCP/Azure,混合云,Kubernetes, 以及裸机上
无论在云上还是本地,Druid可以轻松的部署在商用硬件上的任何*NIX环境。部署Druid也是非常简单的,包括集群的扩容或者下线都也同样很简单。
使用场景
Druid通常应用于以下场景:
· 点击流分析(Web端和移动端)
· 网络监测分析(网络性能监控)
· 服务指标存储
· 供应链分析(制造类指标)
· 应用性能指标分析
· 数字广告分析
· 商务智能 / OLAP
核心架构
druid
Druid的核心架构吸收和结合了数据仓库、时序数据库以及检索系统)的优势,其主要特征如下:
· 列式存储,Druid使用列式存储,这意味着在一个特定的数据查询中它只需要查询特定的列,这样极地提高了部分列查询场景的性能。另外,每一列数据都针对特定数据类型做了优化存储,从而支持快速的扫描和聚合。
· 可扩展的分布式系统,Druid通常部署在数十到数百台服务器的集群中,并且可以提供每秒数百万条记录的接收速率,数万亿条记录的保留存储以及亚秒级到几秒的查询延迟。
· 大规模并行处理,Druid可以在整个集群中并行处理查询。
· 实时或批量摄取,Druid可以实时(已经被摄取的数据可立即用于查询)或批量摄取数据。
· 自修复、自平衡、易于操作,作为集群运维操作人员,要伸缩集群只需添加或删除服务,集群就会在后台自动重新平衡自身,而不会造成任何停机。如果任何一台Druid服务器发生故障,系统将自动绕过损坏。 Druid设计为7*24全天候运行,无需出于任何原因而导致计划内停机,包括配置更改和软件更新。
· 不会丢失数据的云原生容错架构,一旦Druid摄取了数据,副本就安全地存储在深度存储介质(通常是云存储,HDFS或共享文件系统)中。即使某个Druid服务发生故障,也可以从深度存储中恢复您的数据。对于仅影响少数Druid服务的有限故障,副本可确保在系统恢复时仍然可以进行查询。
· 用于快速过滤的索引,Druid使用CONCISE或Roaring压缩的位图索引来创建索引,以支持快速过滤和跨多列搜索。
· 基于时间的分区,Druid首先按时间对数据进行分区,另外同时可以根据其他字段进行分区。这意味着基于时间的查询将仅访问与查询时间范围匹配的分区,这将大大提高基于时间的数据的性能。
· 近似算法,Druid应用了近似count-distinct,近似排序以及近似直方图和分位数计算的算法。这些算法占用有限的内存使用量,通常比精确计算要快得多。对于精度要求比速度更重要的场景,Druid还提供了精确count-distinct和精确排序。
· 摄取时自动汇总聚合,Druid支持在数据摄取阶段可选地进行数据汇总,这种汇总会部分预先聚合您的数据,并可以节省大量成本并提高性能。
场景
如果您的使用场景符合以下的几个特征,那么Druid是一个非常不错的选择:
· 数据插入频率比较高,但较少更新数据
· 大多数查询场景为聚合查询和分组查询(GroupBy),同时还有一定得检索与扫描查询
· 将数据查询延迟目标定位100毫秒到几秒钟之间
· 数据具有时间属性(Druid针对时间做了优化和设计)
· 在多表场景下,每次查询仅命中一个大的分布式表,查询有可能命中多个较小的lookup表
· 场景中包含高基维度数据列(例如URL,用户ID等),并且需要对其进行快速计数和排序
· 需要从Kafka、HDFS、对象存储(如Amazon S3)中加载数据
如果您的使用场景符合以下特征,那么使用Druid可能是一个不好的选择:
· 根据主键对现有数据进行低延迟更新操作。Druid支持流式插入,但不支持流式更新(更新操作是通过后台批处理作业完成)
· 延迟不重要的离线数据系统
· 场景中包括大连接(将一个大事实表连接到另一个大事实表),并且可以接受花费很长时间来完成这些查询
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









