








导读:近日,arXiv 将 170 万+ 篇的论文,打包成数据集,放在了 kaggle 平台,以后访问和下载论文,就更方便了。该数据集目前大小 1.1 TB 左右,而且之后还会随着每周的更新持续增长。
作者 | 神经小兮
来源 | HyperAI超神经(ID: HyperAI)
170 万+ 篇学术论文,1.1 TB 大小,这是 arXix 最近在 kaggle 开放的一套数据集,网友问讯惊呼:太酷了!
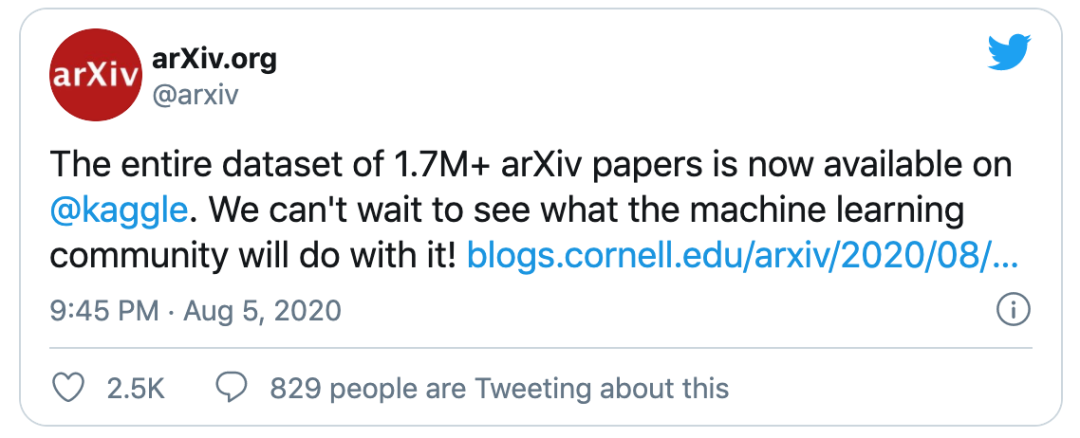
网友评论区纷纷捧场:太棒了!
数据集整理团队表示,希望能以此激发相关研究者,探索更丰富的机器学习技术,提出更多的发现和创新。

开放数据集,让论文搜索更简单
近 30 年来,arXiv 为公众和研究团队提供学术文章的开放访问渠道,这些学术论文涵盖的领域极为广泛,从物理学的庞大分支,到计算机科学的众多分支,再到数学、统计学、电子工程、定量生物学和经济学等所有学科。
这些 arXiv 上大量的研究论文,虽然很多人从中获益,但也经常有人反映,它存在浏览、搜索和排序不方便等缺点。甚至有人还专门找到一些在 arXiv 上搜论文的技巧分享出来。
于是,为了让 arXiv 更加易于访问,康奈尔大学现在在 Kaggle 上提供了一个免费、开放的 arXiv 数据集。
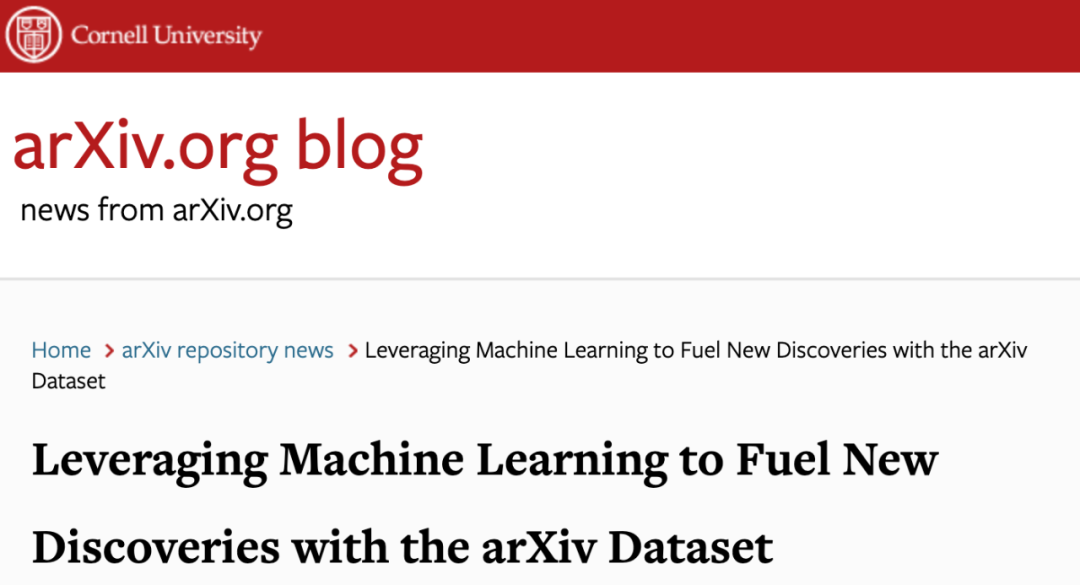
该数据集包含了 170 万篇学术论文,还包含了论文相关的元素(features),例如文章标题、作者、类别、摘要以及全文 PDF 等。
arXiv 执行董事 Eleonora Presani 介绍说:「在 Kaggle 上拥有整个 arXiv 语料库,极大地增加了 arXiv 论文的潜力。通过在 Kaggle 上提供数据集,我们不再只是让大家通过阅读这些文章学到知识,更重要的是,将 arXiv 背后的数据和信息,以机器可读的格式提供给公众。」
 Eleonora Presani 是 arXiv 的第一任执行董事
Presani 还说:「arXiv 不仅仅是一个论文库,它还是一个知识共享的平台。这要求我们在展示和解释可用知识的方式上,不断创新。而 Kaggle 用户可以帮助突破这一创新的极限,它成为了我们进行社区协作的新渠道。」
Eleonora Presani 是 arXiv 的第一任执行董事
Presani 还说:「arXiv 不仅仅是一个论文库,它还是一个知识共享的平台。这要求我们在展示和解释可用知识的方式上,不断创新。而 Kaggle 用户可以帮助突破这一创新的极限,它成为了我们进行社区协作的新渠道。」
 arXiv 数据集都有什么?
arXiv 数据集基本信息如下:
arXiv 数据集都有什么?
arXiv 数据集基本信息如下:
arXiv Dataset
发布人员: Paul Ginsparg,Moonshot Factory,Jack Hidary
包含数量:170 万+ 篇学术论文
数据格式:json
数据大小:1.1 TB
发布时间:2020 年 8 月
下载地址:https://www.kaggle.com/Cornell-University/arxiv
目前,arXiv 数据集提供了 json 格式的元数据文件,它包含每篇论文的相关条目,具体如下:- id:论文访问地址,可用于访问论文;
- submitter:论文提交者;
- authors:论文作者;
- title:论文标题;
- comments:论文页数和图表等其它信息;
- journal-ref:论文发表的期刊信息;
- doi:数字对象标识符;
- abstract:论文摘要;
- categories:论文在 arXiv 所属类别或标签;
- versions:论文版本。
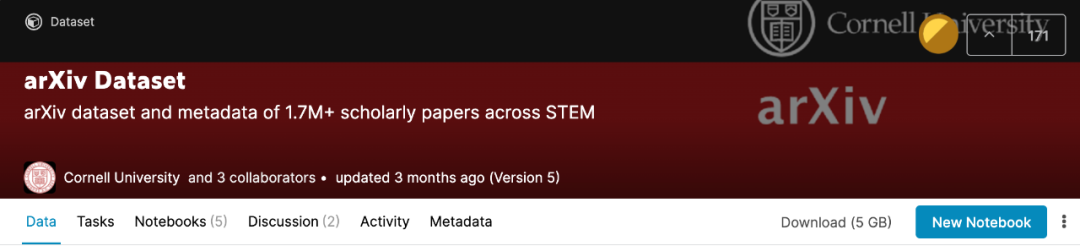 数据集目前已更新了 5 个版本
此外,用户还可以通过以下两个链接直接在 arXiv 上访问每篇论文:
数据集目前已更新了 5 个版本
此外,用户还可以通过以下两个链接直接在 arXiv 上访问每篇论文:
- https://arxiv.org/abs/{id}:论文页面,包括摘要和其他链接;
- https://arxiv.org/pdf/{id}:论文 PDF 下载页面。
tarpdfs/arXiv_pdf_1001_001.tar.gz (gs://arxiv-dataset/tarpdfs/arXiv_pdf_1001_001.tar.gz)tarpdfs/arXiv_pdf_1001_002.tar.gz (gs://arxiv-dataset/tarpdfs/arXiv_pdf_1001_002.tar.gz)tarpdfs/arXiv_pdf_1001_003.tar.gz (gs://arxiv-dataset/tarpdfs/arXiv_pdf_1001_003.tar.gz) 数据集中的元数据示例
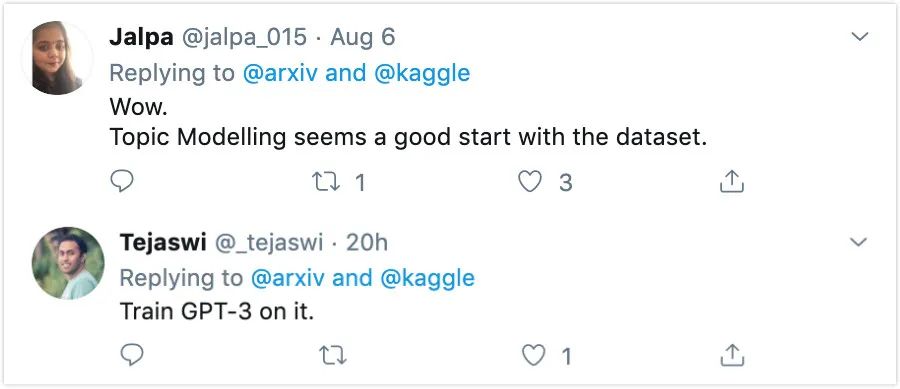
不过,这个数据集具体有哪些使用场景呢?很多网友已经有了想法,比如主题建模、用该数据训练 GPT-3 等。
数据集中的元数据示例
不过,这个数据集具体有哪些使用场景呢?很多网友已经有了想法,比如主题建模、用该数据训练 GPT-3 等。
 arXiv:巨大的学术论文资源库
科研学术圈的同学,对 arXiv 一定都不陌生。
它是一个收集物理学、数学、计算机科学与生物学论文预印本的网站,不仅为广大科研人员提供了一个 idea「占坑」的平台,也是大家搜索、阅读论文的巨大资源库。
截至 2008 年 10 月,arXiv.org 已收集超过 50 万篇预印本;至 2014 年底,其藏量达到 100 万篇;截至 2016 年 10 月,arXiv 提交量每月已经超过 10000 篇。
arXiv:巨大的学术论文资源库
科研学术圈的同学,对 arXiv 一定都不陌生。
它是一个收集物理学、数学、计算机科学与生物学论文预印本的网站,不仅为广大科研人员提供了一个 idea「占坑」的平台,也是大家搜索、阅读论文的巨大资源库。
截至 2008 年 10 月,arXiv.org 已收集超过 50 万篇预印本;至 2014 年底,其藏量达到 100 万篇;截至 2016 年 10 月,arXiv 提交量每月已经超过 10000 篇。
 目前 arXiv 上的学术论文已经有约 174.46 万篇
arXiv 最早是由物理学家保罗·金斯巴格,在 1991 年建立的网站,本意是收集物理学的论文预印本,随后括及天文、数学等其它领域。
arXiv 原先挂在洛斯阿拉莫斯国家实验室(LANL),因此早期被称为「LANL预印本数据库」。目前 arXiv 落脚于康奈尔大学,并在全球各地设有镜像站点。网站在 1999 年改名为 arXiv.org。
现在,用通俗的话来说,arXiv 就是一个用来「占坑」的网站,研究者们为了防止自己的 idea 在论文被收录之前被别人剽窃,就会将预稿先发表在 arXiv 上,以证明自己的原创性。
参考资料:
https://blogs.cornell.edu/arxiv/2020/08/05/leveraging-machine-learning-to-fuel-new-discoveries-with-the-arxiv-dataset/
https://www.kaggle.com/Cornell-University/arxiv?select=arxiv-metadata-oai-snapshot.json
https://zh.wikipedia.org/wiki/ArXiv
目前 arXiv 上的学术论文已经有约 174.46 万篇
arXiv 最早是由物理学家保罗·金斯巴格,在 1991 年建立的网站,本意是收集物理学的论文预印本,随后括及天文、数学等其它领域。
arXiv 原先挂在洛斯阿拉莫斯国家实验室(LANL),因此早期被称为「LANL预印本数据库」。目前 arXiv 落脚于康奈尔大学,并在全球各地设有镜像站点。网站在 1999 年改名为 arXiv.org。
现在,用通俗的话来说,arXiv 就是一个用来「占坑」的网站,研究者们为了防止自己的 idea 在论文被收录之前被别人剽窃,就会将预稿先发表在 arXiv 上,以证明自己的原创性。
参考资料:
https://blogs.cornell.edu/arxiv/2020/08/05/leveraging-machine-learning-to-fuel-new-discoveries-with-the-arxiv-dataset/
https://www.kaggle.com/Cornell-University/arxiv?select=arxiv-metadata-oai-snapshot.json
https://zh.wikipedia.org/wiki/ArXiv
推荐阅读- 美国禁止与字节跳动及微信交易,腾讯股价暴跌,字节跳动回应了
- 我还没考试,算法就说我的物理一定挂科
- 华为首秀 AI 全栈软件平台!
- Python再夺冠,上古语言COBOL大流行,IEEE Spectrum 2020年度编程语言排行榜出炉!
- 中台架构详解(上) | 大咖说中台


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









