





一、Kafka Manager(开发人员爆款)
(1)如何搭建
- 环境要求
a、jdk1.8
b、kafka集群10.96.101.194:9092,10.96.84.247:9092,10.96.92.223:9092(测试用的是CDH,CDH离线安装请移至CDH 测试环境使用文档,在线安装https://www.jianshu.com/p/d2c524ec0d1b)
c、系统:Linux spark-master 3.10.0-514.16.1.el7.x86_64 #1 SMP Wed Apr 12 15:04:24 UTC 2017 x86_64 x86_64 x86_64 GNU/Linux - 下载kafka manager
a、Git地址:https://github.com/yahoo/kafka-manager
b、如果下载的是源码,需要进行编译,比较懒的可以从下面地址直接下载编译好的kafka-manager-1.3.3.7.zip
https://pan.baidu.com/s/1qYifoa4 密码:el4o - 解压(略过)
- 修改配置文件:conf/application.properties
#kafka-manager.zkhosts="localhost:2181" ##注释这一行,下面添加一行
kafka-manager.zkhosts="10.96.101.194:2181,10.96.84.247:2181,10.96.92.223:2181" - 启动
./bin/kafka-manager -Dconfig.file=conf/application.conf -Dhttp.port=9001 ##默认端口是9000 - 界面配置Kafka集群 http://10.96.98.4:9001/
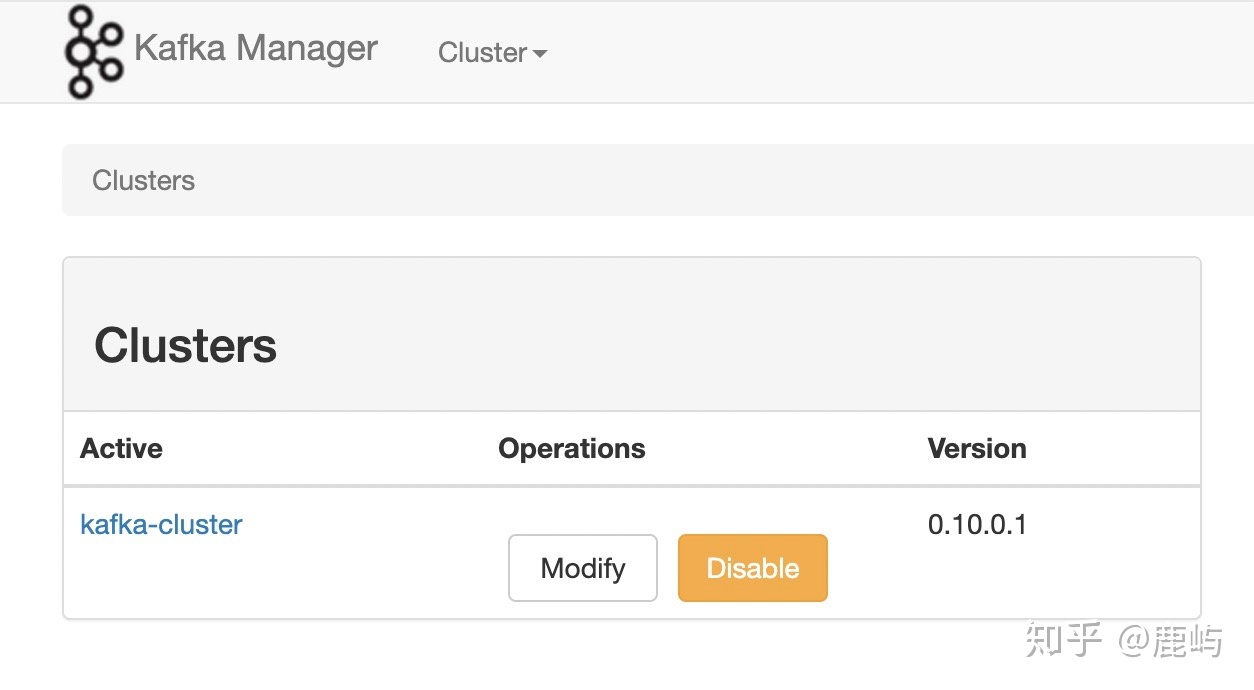
(2)它能做什么
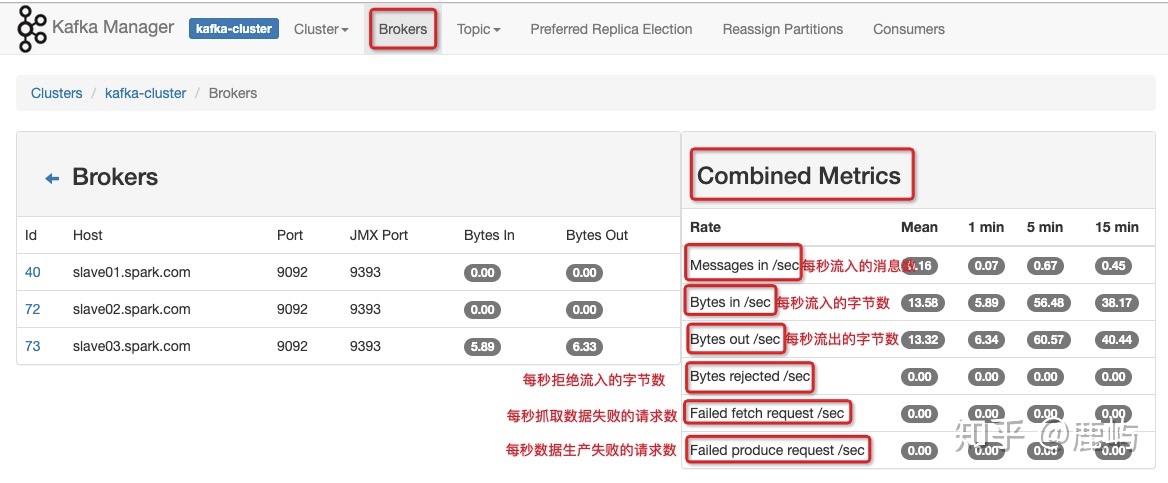
- 监控(对于部分kafka broker和topic监控指标的获取,需要开启JMX轮训)
- 开启JMX(上图中的三个红色框框)
- 对消息监控
a、Enable JMX Polling 影响如下指标的查看
- 对消息监控
- 开启JMX(上图中的三个红色框框)
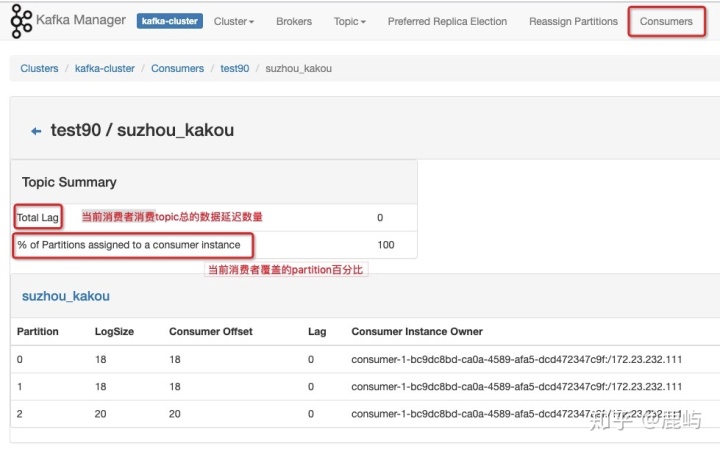
b、Poll consumer informatein影响在消费者页面和topic页面查看消费信息

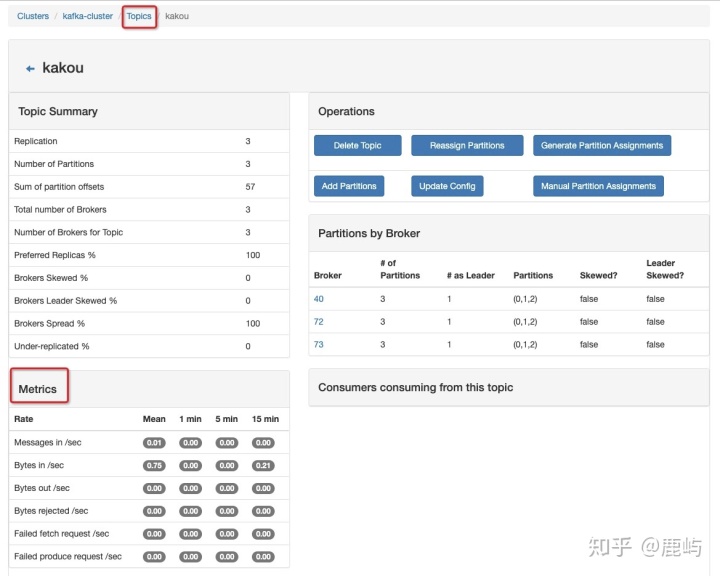
c、topic层面的监控、统计,包括每个topic分区数、占用的broker、broker覆盖率、副本数、broker倾斜率等
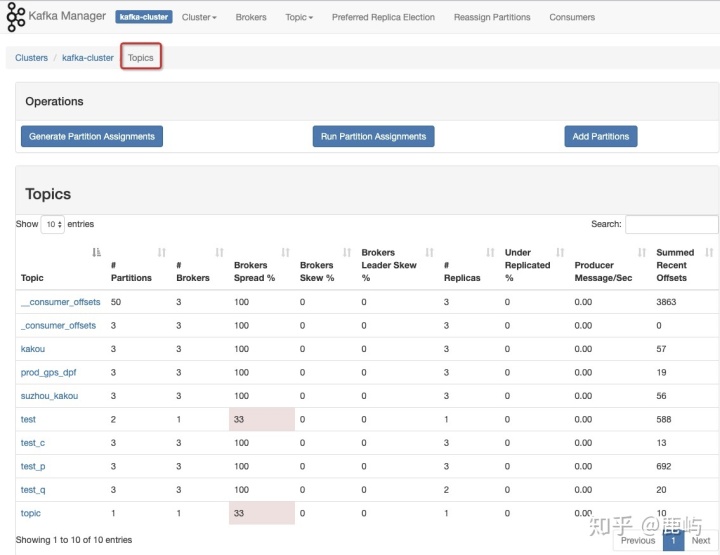
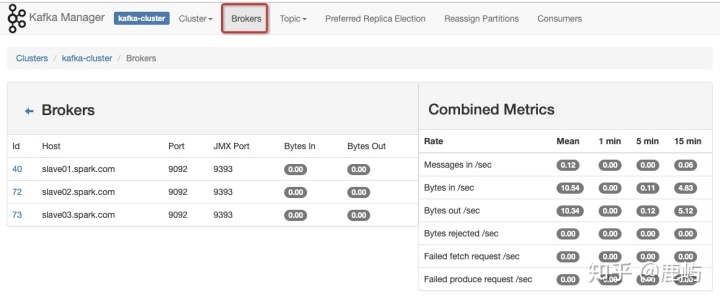
d、brokers层面的的监控、统计,包括每个broker包含的topics、partitions、messages
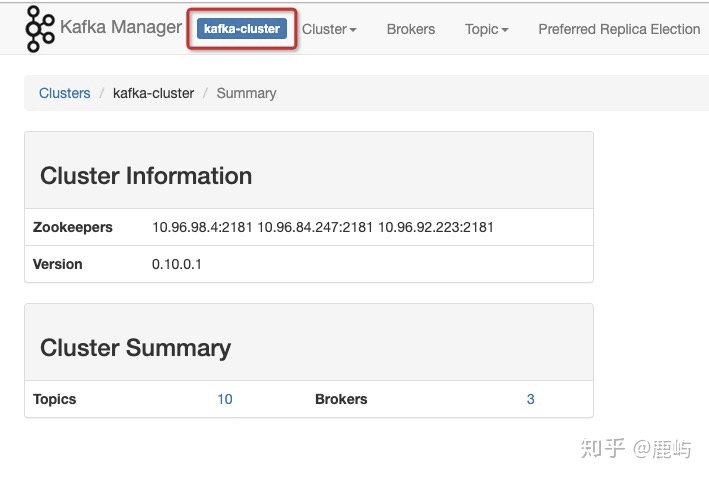
e、cluster层面的监控、统计
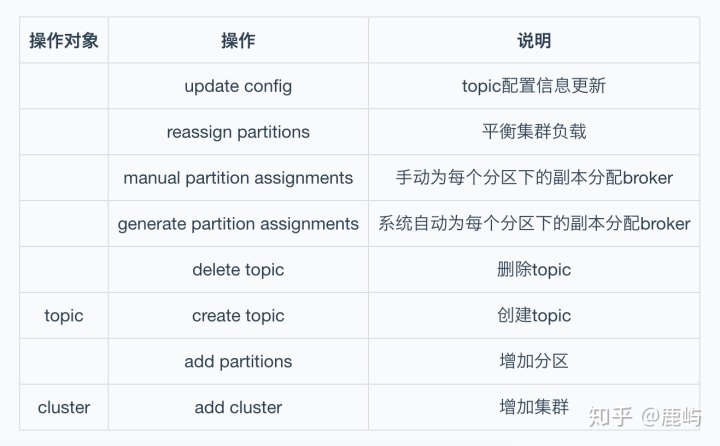
- 操作(主要是针对topic)
(3)谈谈一些参数
- Brokers Skew% (broker 倾斜率):该topic占有的broker中,拥有超过该topic平均分区数的broker所占的比重
比如:我们有3个分区,3个副本的topic,该topic一共有3*3=9个分区,
分布在3个broker上,平均每一个broker应该拥有3个分区。
3个broker并没有哪个拥有超过平均分区数,所以Brokers Skew%为0 
- Brokers Leader Skew% (broker leader 分区倾斜率):该topic占有的broker中,拥有超过该topic平均leader分区数的broker所占的比例
比如:我们有3个分区,3个副本的topic,该topic一共有3个Leader分区,
分布在3个broker上,平均每一个broker应该拥有1个Leader分区。
3个broker并没有哪个拥有超过平均Leader分区数,所以Brokers Leader Skew%为0 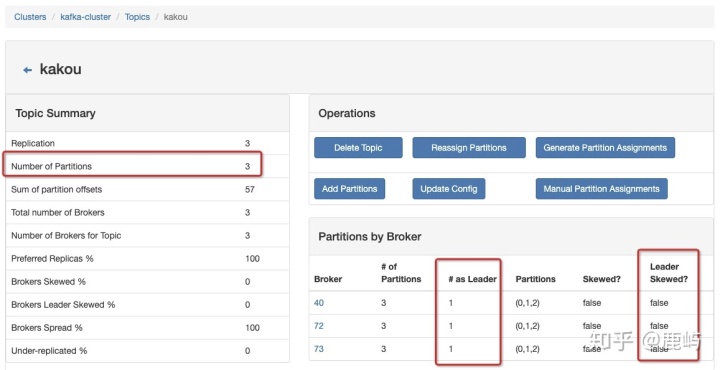
- Under Replicated%:该topic下副本处于失效或者失败的比率
- 失效或者失败是指副本不处于ISR队列中(如果一个follower在replica.log.max.ms时间内没有发送fetch或者消费leader日志到结束的offser,leader将从ISR中移除这个folloer,并认为这个follower已经挂掉)
- 小结
- Broker Skew: 反映broker的I/O压力。如果该指标过高,说明 topic 的分区均不不好,topic 的稳定性弱
- Broker Leader Skew:数据的生产和消费进程都只于Leader分区打交道。该指标过高,说明 topic 的分流做的不够好
- Under Replicated: 该指标过高时,表明 topic 的数据容易丢失,数据没有复制到足够的 broker 上
二、KafkaOffsetMonitor(部署方便、主要是对消费情况的监控)
(1)如何搭建
- 由于官网上的jar所引用的js,css是国外的地址,由于国内网络环境的问题,可能会访问不了,导致KafkaOffsetMonitor页面没有任何数据显示。需要把jar里的js,css替换成本地的。下载地址:
- https://download.csdn.net/download/guang564610/10371172
- https://pan.baidu.com/s/1A_Ukh6FlvOYkUws7kUPAqg
- 下载完之后直接运行命令
nohup java -cp KafkaOffsetMonitor-assembly-0.4.6-SNAPSHOT.jar com.quantifind.kafka.offsetapp.OffsetGetterWeb --offsetStorage kafka --kafkaBrokers 10.96.101.194:9092,10.96.84.247:9092,10.96.92.223:9092 --kafkaSecurityProtocol PLAINTEXT --zk 10.96.98.4:2181,10.96.84.247:2181,10.96.92.223:2181 --port 8089 --refresh 10.seconds --retain 1.days --dbName offsetapp_kafka & (2)界面
- cluster

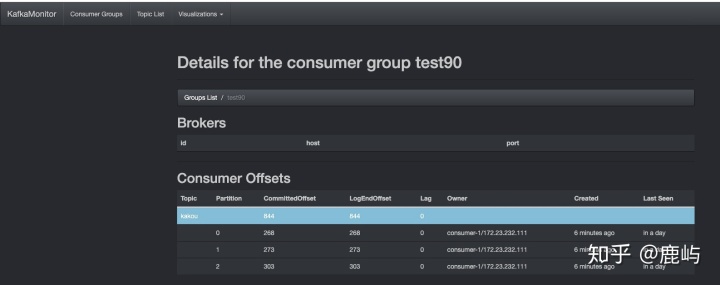
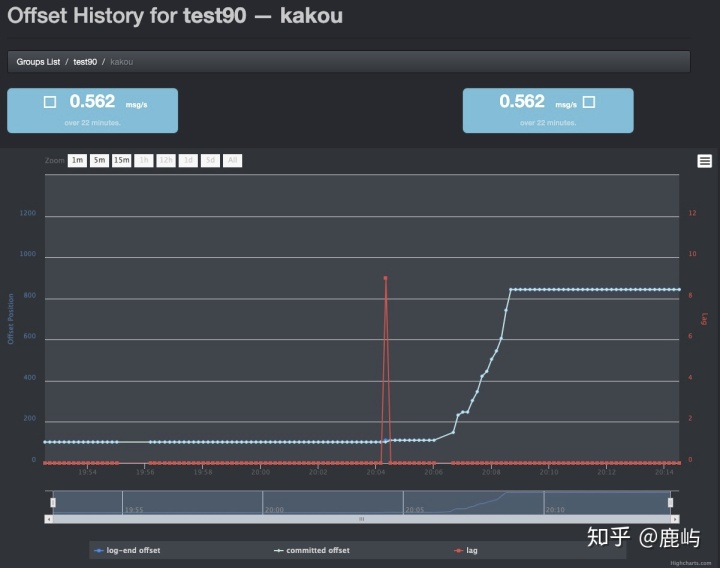
- 消费组消费情况
(2)小结
- KafkaOffsetMonitor0.2及之前的版本已经没人维护更新了,之后的版本由于国内网络环境的问题需要替换jar包里的js和css,也是有点坑~
- 只支持监控,功能不够全,界面酷炫还算凑合部署搭建是真的方便,运行一个jar包即可
三、JMXtrans+InfluxDB+Grafana实现性能指标监控(监控神器、定制化、混合风~)
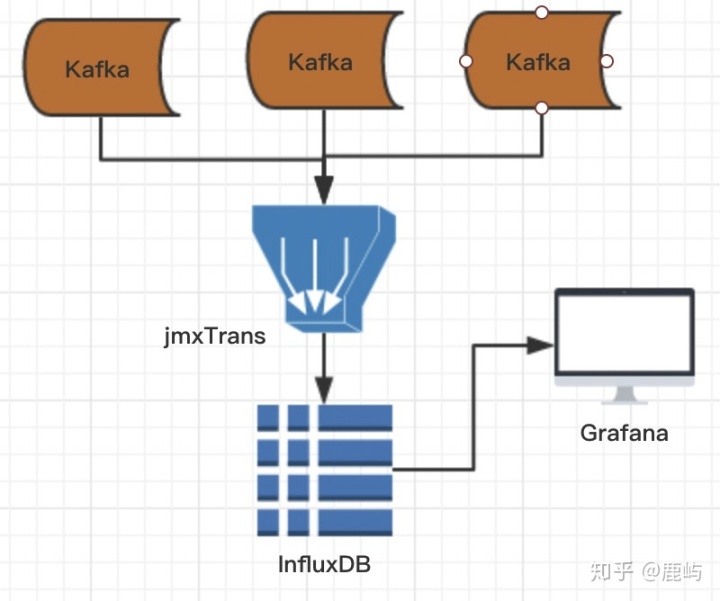
(1)架构图(居然还有架构图…)
- jmxtrans通过jxm收集kafka的监控指标(所以kafka不要忘记开启jmx,参考https://www.jianshu.com/p/de4b4cbb0f3c)写到InfluxDb,Grafana读取InfluxDb绘图并做展示
(2)如何搭建
- 环境要求
a、influxdb-1.5.3:时间序列数据库,内置HTTP API,适合实时响应查询
b、jmxtrans-266:自动获取jmx对外暴露的jvm内部的一些指标,并按照某种格式输出到其他应用程序(比如influxdb)
c、grafana-5.4.2-1:灵活丰富的可视化面板,支持Graphite、zabbix、InfluxDB、Prometheus和OpenTSDB作为数据源(都没听过...)
d、kafka集群10.96.101.194:9092,10.96.84.247:9092,10.96.92.223:9092(测试用的是CDH,CDH离线安装请移至CDH 测试环境使用文档,在线安装https://www.jianshu.com/p/d2c524ec0d1b)
c、系统:Linux spark-master 3.10.0-514.16.1.el7.x86_64 #1 SMP Wed Apr 12 15:04:24 UTC 2017 x86_64 x86_64 x86_64 GNU/Linux
- 那就开始安装吧
安装influxDb
wget https://dl.influxdata.com/influxdb/releases/influxdb-1.5.3.x86_64.rpm ## 获取下rmp包
yum localinstall influxdb-1.5.3.x86_64.rpm ## 安装 -
- 安装jmxtrans
wget http://central.maven.org/maven2/org/jmxtrans/jmxtrans/266/jmxtrans-266.rpm ## 获取下rmp包
rpm -ivh jmxtrans-266.rpm ## 安装 - 安装grafana(grafana安装官网https://grafana.com/grafana/download/4.6.3提供了很多安装方式,看自己喜好)
wget https://s3-us-west-2.amazonaws.com/grafana-releases/release/grafana-5.0.3-1.x86_64.rpm ## 获取下rmp包 yum localinstall grafana-5.0.3-1.x86_64.rpm ## 安装 - 安装完了那就开始启动吧
- 启动influxDb
// 第一种启动方式
/etc/init.d/influxdb start
//第二种启动方式
service influxdb start
//这两种启动方式都FAILED...查了半天
Starting influxdb...
could not open session
influxdb process was unable to start [ FAILED ]
!!!!!!正确的启动姿势(官网说启动的时候不用指定配置文件的额 !!!!!!
influxd -config /etc/influxdb/influxdb.conf -
- 启动jmxtrans
//启动
/etc/init.d/jmxtrans start
//jmxtrans启动成功之后会默认会去读取/var/lib/jmxtrans下的配置文件然后去采集
//启动之后查看/var/log/jmxtrans/jmxtrans.log日志:Error parsing json
//好吧,查看/var/lib/jmxtrans 发现有几个空的json文件(空文件也会解析失败),删了重启ok
/etc/init.d/jmxtrans restart -
- 启动grafana
//启动
service grafana-server start
/etc/rc.d/init.d/grafana-server start
//这两种启动方式都FAILED(又来...),而且没有任何日志输出,面向谷歌编程也没查到任何信息(主要没有日志,不知道怎么查...绝望)
// 被逼无奈 只能在/etc/init.d/grafana-server启动文件中echo日志排查
//发现在执行action $"Starting $DESC: ..." su -s /bin/sh -c "nohup ${DAEMON} ${DAEMON_OPTS} >> /dev/null 3>&1 &" $GRAFANA_USER 2> /dev/null后就退出了
// 单独执行下${DAEMON} ${DAEMON_OPTS}即/usr/sbin/grafana-server --pidfile=/var/run/grafana-server.pid --config=/etc/grafana/grafana.ini
--packaging=rpm cfg:default.paths.provisioning=/etc/grafana/provisioning cfg:default.paths.data=/var/lib/grafana
cfg:default.paths.logs=/var/log/grafana cfg:default.paths.plugins=/var/lib/grafana/plugins
//终于报错了!!:Grafana-server Init Failed: Could not find config defaults, make sure homepath command line parameter is set or working directory is homepath
//找不到默认的配置文件??执行命令时所在的目录难道还有要求??
//好吧先cd /usr/share/grafana然后执行/usr/sbin/grafana-server --config=/etc/grafana/grafana.ini
// 启动成功了...哭... - 需要的组件都成功启动了,应该只剩下(1)配置怎么通过jmxtrans把kafka jmx数据以及其他所需要的jmx数据采集到influxDb(2)Grafana配置influxDb数据源进行展示
- kafka/thread/gc等jmx数据==>InfluxDb(jmxtrans登场)
- jmxtrans是默认读取/var/lib/jmxtrans下的配置文件去采集数据的,分为全局指标和topic指标
- 全局指标是指每个kafka节点的指标
- 每秒输入的字节流量
- 全局指标是指每个kafka节点的指标
- jmxtrans是默认读取/var/lib/jmxtrans下的配置文件去采集数据的,分为全局指标和topic指标
- kafka/thread/gc等jmx数据==>InfluxDb(jmxtrans登场)
"obj" : "kafka.server:type=BrokerTopicMetrics,name=BytesInPerSec"
"attr" : [ "Count" ]
"resultAlias":"BytesInPerSec"
"tags" : {"application" : "BytesInPerSec"} -
-
-
-
- 每秒输输出的字节流量
-
-
-
"obj" : "kafka.server:type=BrokerTopicMetrics,name=BytesOutPerSec"
"attr" : [ "Count" ]
"resultAlias":"BytesOutPerSec"
"tags" : {"application" : "BytesOutPerSec"}
-
-
-
-
- 每秒拒绝的字节流量
-
-
-
"obj" : "kafka.server:type=BrokerTopicMetrics,name=BytesRejectedPerSec"
"attr" : [ "Count" ]
"resultAlias":"BytesRejectedPerSec"
"tags" : {"application" : "BytesRejectedPerSec"} -
-
-
-
- 每秒FetchFollower的请求次数
-
-
-
"obj" : "kafka.network:type=RequestMetrics,name=RequestsPerSec,request=FetchFollower"
"attr" : [ "Count" ]
"resultAlias":"RequestsPerSec"
"tags" : {"request" : "FetchFollower"} -
-
-
-
- 每秒FetchConsumer的请求次数
-
-
-
"obj" : "kafka.network:type=RequestMetrics,name=RequestsPerSec,request=FetchConsumer"
"attr" : [ "Count" ]
"resultAlias":"RequestsPerSec"
"tags" : {"request" : "FetchConsumer"} -
-
-
-
- 内存使用的使用情况
-
-
-
"obj" : "java.lang:type=Memory"
"attr" : [ "HeapMemoryUsage", "NonHeapMemoryUsage" ]
"resultAlias":"MemoryUsage"
"tags" : {"application" : "MemoryUsage"} -
-
-
-
- GC的耗时和次数
-
-
-
"obj" : "java.lang:type=Threading"
"attr" : [ "PeakThreadCount","ThreadCount" ]
"resultAlias":"Thread"
"tags" : {"application" : "Thread"} -
-
-
-
- 线程的使用情况
-
-
-
"obj" : "java.lang:type=Threading"
"attr" : [ "PeakThreadCount","ThreadCount" ]
"resultAlias":"Thread"
"tags" : {"application" : "Thread"} -
-
-
-
- 还有很多(具体看jvm kafka…)
- topic指标
- falcon_monitor_us每秒的写入流量
-
-
-
"kafka.server:type=BrokerTopicMetrics,name=BytesInPerSec,topic=falcon_monitor_us"
"attr" : [ "Count" ]
"resultAlias":"falcon_monitor_us"
"tags" : {"application" : "BytesInPerSec"} -
-
-
-
- falcon_monitor_us每秒的输出流量
-
-
-
"kafka.server:type=BrokerTopicMetrics,name=BytesOutPerSec,topic=falcon_monitor_us"
"attr" : [ "Count" ]
"resultAlias":"falcon_monitor_us"
"tags" : {"application" : "BytesOutPerSec"} -
-
-
-
- falcon_monitor_us每秒写入消息的数量
-
-
-
"obj" : "kafka.server:type=BrokerTopicMetrics,name=MessagesInPerSec,topic=falcon_monitor_us"
"attr" : [ "Count" ]
"resultAlias":"falcon_monitor_us"
"tags" : {"application" : "MessagesInPerSec"} -
-
-
-
- falcon_monitor_us在每个分区最后的Offset
-
-
-
"obj" : "kafka.log:type=Log,name=LogEndOffset,topic=falcon_monitor_us,partition=*"
"attr" : [ "Value" ]
"resultAlias":"falcon_monitor_us"
"tags" : {"application" : "LogEndOffset"} -
-
-
-
- 还有很多(具体看jvm kafka…)
-
- 来一个完整的配置文件吧 base_10.96.92.223.json8.7 KBfalcon_monitor_us_223.json2 KB
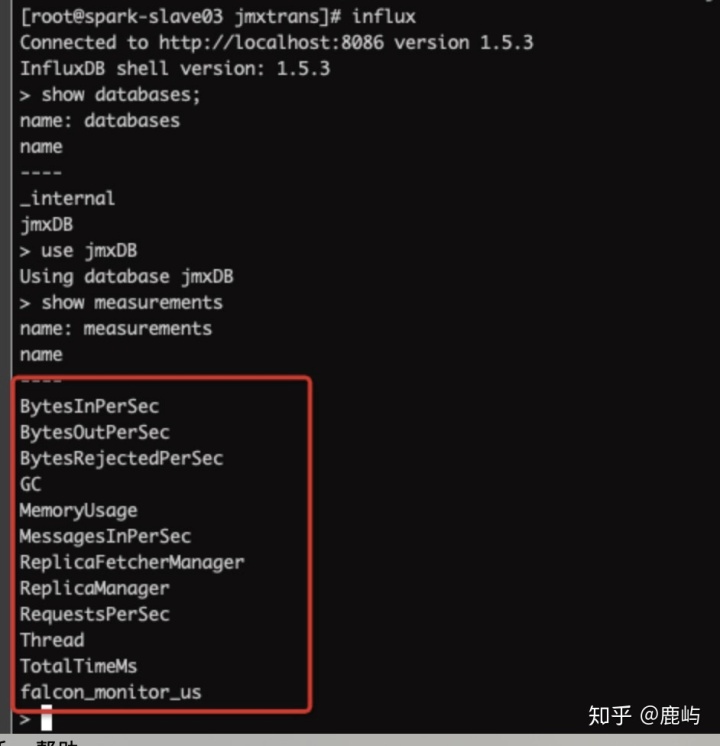
- 来看看是否采集到了所需的数据(激动~)
-
-
-
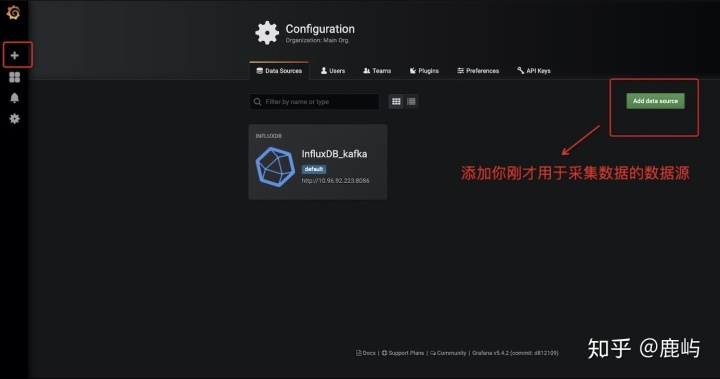
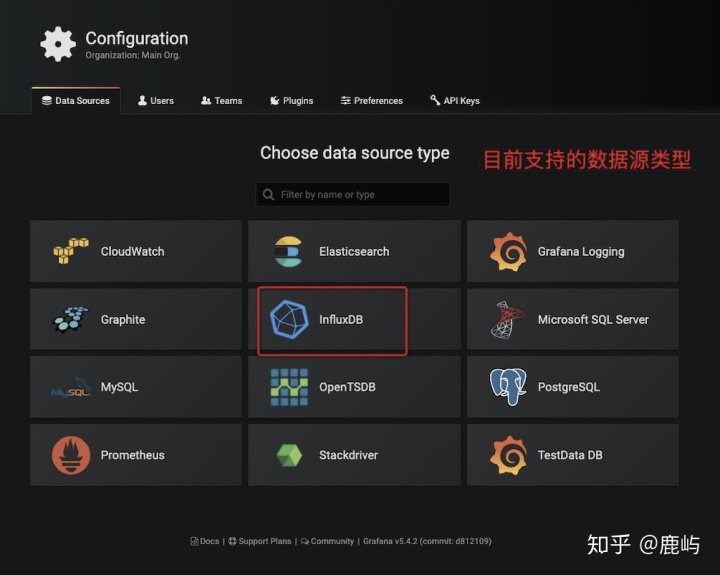
- InfluxDb==>Grafana (纯界面操作!!!最后一步了!!!)
- 添加数据源
- InfluxDb==>Grafana (纯界面操作!!!最后一步了!!!)
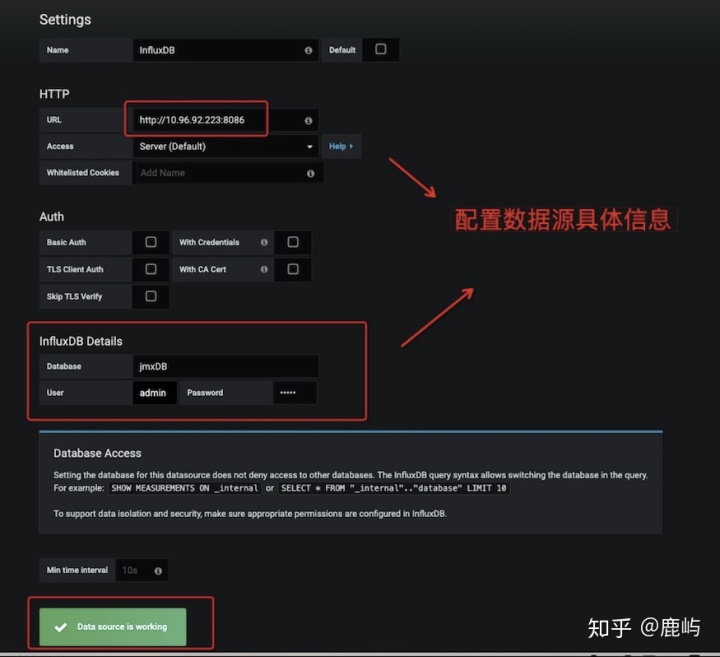
-
-
- 定制化图表类型
-
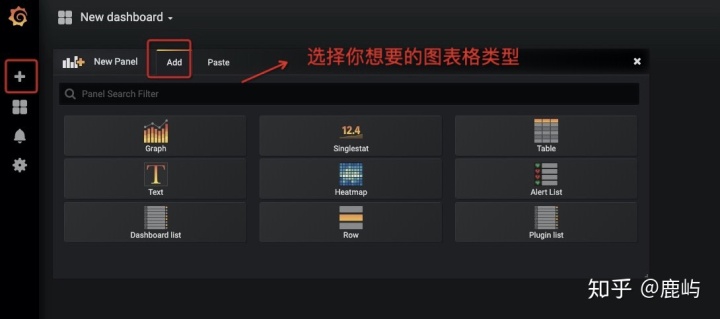
-
-
- 定制化指标(Query)
-
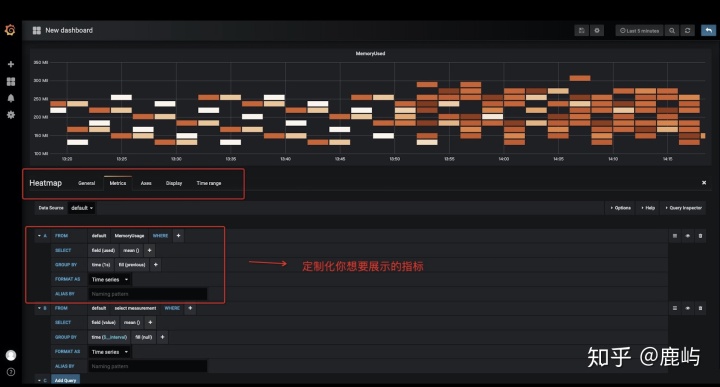
-
-
- 最终效果
-
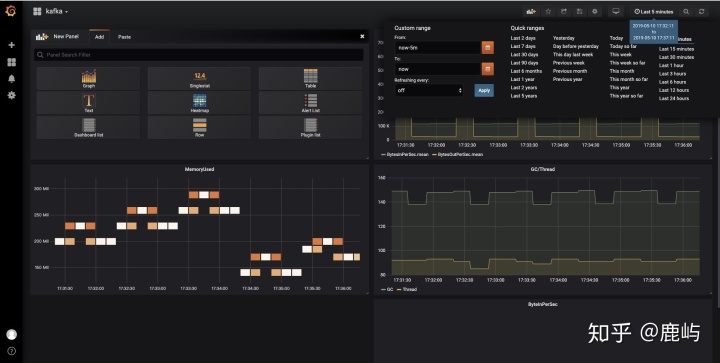
(3)感觉怎么样
- 图表功能把其他两款秒成渣渣,定制化功能灵活到让人“为所欲为”
- 一劳永逸,以后想展示其他zk数据?hdfs数据?jvm数据?flume数据?你采集就完事了~
- 只能监控,不能操作
- 搭建时需要不断踩坑,让人抓狂~学习成本相对较高(有付出才有回报)
四、大佬自己看看喜欢哪款
- 已部署地址(基于cdh http://10.96.98.4:7180 中的kafka集群)
- Kafka Manager:http://10.96.98.4:9001
- KafkaOffsetMonitor:http://10.96.101.194:8089/
- JMXtrans + InfluxDB + Grafana: http://10.96.92.223:3000















 491
491

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









