





本文非常全面的介绍了Scipy库,希望大家有耐心的看下去。参考链接在最后。
目录:
1. Scipy简介
1.1 子包
1.2 数据结构
2. Scipy开发环境安装
2.1 Windows
2.2 Linux
3. Scipy基本功能
3.1 内在Numpy数组创建
3.2 矩阵
4. Scipy簇聚
4.1 Scipy中实现K-Means
4.2 三个集群计算K均值
5. Scipy常量
5.1 Scipy常量包
5.2 可用常量列表
6. FFTpack
6.1 快速傅立叶变换
6.2 离散余弦变换
7. 积分
7.1 单积分
7.2 多重积分
7.3 双重积分
8. 插值
8.1 插值是什么
8.2 一线插值
8.3 样条曲线
9. 输入/输出
10. Linalg
10.1 线性方程组
10.2 查找行列式
10.3 特征向量与特征值
11. Ndimage
11.1 打开与写入图像文件
11.2 滤镜
11.3 边缘检测
12. 优化算法
12.1 Nelder-Mead单纯形算法
12.2 最小二乘
13. 统计函数
13.1 正太连续随机变量
13.2 均匀分布
14. CSGraph
14.1 图表示
14.2 获取单词列表
15. Scipy空间
15.1 Delaunay三角
15.2 共面点
15.3 凸壳
16. Scipy ODR
17. Scipy特殊包
----------------------------------------------------------------------------------
13. 统计函数
所有的统计函数都位于子包scipy.stats中,并且可以使用info(stats)函数获得这些函数的完整列表。随机变量列表也可以从stats子包的docstring中获得。 该模块包含大量的概率分布以及不断增长的统计函数库。
每个单变量分布都有其自己的子类,如下表所述。
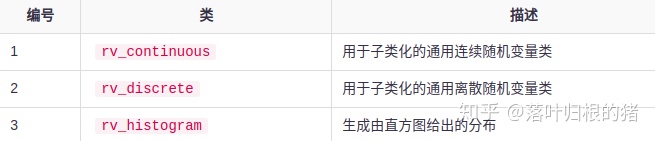
13.1 正态连续随机变量
随机变量X可以取任何值的概率分布是连续的随机变量。 位置(loc)关键字指定平均值。 比例(scale)关键字指定标准偏差。
作为rv_continuous类的一个实例,规范对象从中继承了一系列泛型方法,并通过特定于此特定分发的细节完成它们。
要计算多个点的CDF,可以传递一个列表或一个NumPy数组。 看看下面的一个例子。
from scipy.stats import norm
import numpy as np
cdfarr=norm.cdf(np.array([1,-1.,0,1,3,4,-2,6]))
print(cdfarr)
执行上面示例代码,得到以下结果 -
array([ 0.84134475, 0.15865525, 0.5 , 0.84134475, 0.9986501 ,
0.99996833, 0.02275013, 1. ])
要查找分布的中位数,可以使用百分点函数(PPF),它是CDF的倒数。 可通过使用下面的例子来理解。
from scipy.stats import norm
ppfvar=norm.ppf(0.5)
print(ppfvar)
执行上面示例代码,得到以下结果 -
0.0
要生成随机变量序列,应该使用size参数,如下例所示。
from scipy.stats import norm
rvsvar=norm.rvs(size=5)
print(rvsvar)
执行上面示例代码,得到以下结果 -
[-0.25993892 1.46653546 -0.53932984 -1.22796601 0.06542478]
上述输出不可重现。 要生成相同的随机数,请使用seed()函数。
13.2 均匀分布
使用统一函数可以生成均匀分布。 参考下面的一个例子。
from scipy.stats import uniform
cvar=uniform.cdf([0,1,2,3,4,5],loc=1,scale=4)
print(cvar)
上述程序将生成以下输出 -
array([ 0. , 0. , 0.25, 0.5 , 0.75, 1. ])
构建离散分布
生成随机样本,并将观察到的频率与概率进行比较。
二项分布
作为rv_discrete类的一个实例,binom对象从它继承了一个泛型方法的集合,并通过特定于这个特定分布的细节完成它们。 参考下面的例子。
from scipy.stats import uniform
cvar=uniform.cdf([0,1,2,3,4,5],loc=1,scale=4)
print(cvar)
上述程序将生成以下输出 -
array([ 0. , 0. , 0.25, 0.5 , 0.75, 1. ])
13.3 描述性统计
如Min,Max,Mean和Variance等基本统计数据将NumPy数组作为输入并返回相应的结果。 下表描述了scipy.stats包中的一些基本统计函数。
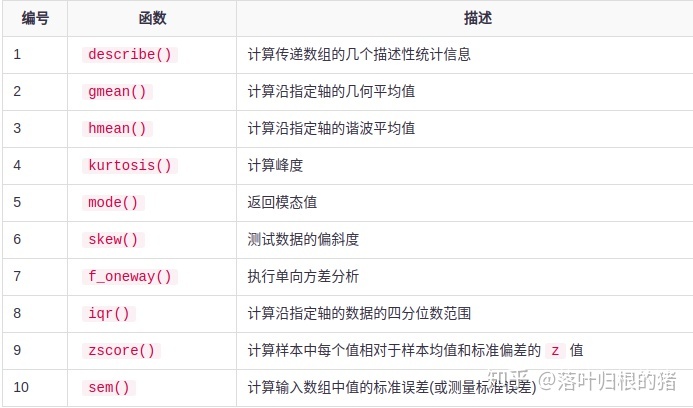
其中几个函数在scipy.stats.mstats中有一个类似的版本,它们用于掩码数组。 参考下面给出的例子来理解这一点。
from scipy import stats
import numpy as np
x=np.array([1,2,3,4,5,6,7,8,9])
print(x.max(),x.min(),x.mean(),x.var())
上述程序将生成以下输出 -
(9, 1, 5.0, 6.666666666666667)
T-检验
下面了解T检验在SciPy中是如何有用的。
ttest_1samp
计算一组分数平均值的T检验。 这是对零假设的双面检验,即独立观测值'a'样本的期望值(平均值)等于给定总体均值popmean,考虑下面的例子。
from scipy import stats
rvs=stats.norm.rvs(loc=5,scale=10,size=(50,2))
sta=stats.ttest_1samp(rvs,5.0)
print(sta)
上述程序将生成以下输出 -
Ttest_1sampResult(statistic = array([-1.40184894, 2.70158009]),
pvalue = array([ 0.16726344, 0.00945234]))
比较两个样本
在下面的例子中,有两个样本可以来自相同或不同的分布,想要测试这些样本是否具有相同的统计特性。
ttest_ind- 计算两个独立样本得分的T检验。 对于两个独立样本具有相同平均(预期)值的零假设,这是一个双侧检验。 该测试假设人口默认具有相同的差异。
如果观察到来自相同或不同人群的两个独立样本,可以使用这个测试。参考下面的例子。
from scipy import stats
rvs1=stats.norm.rvs(loc=5,scale=10,size=500)
rvs2=stats.norm.rvs(loc=5,scale=10,size=500)
print(stats.ttest_ind(rvs1,rvs2))
执行上面示例代码,得到以下结果 -
Ttest_indResult(statistic = -0.67406312233650278, pvalue = 0.50042727502272966)
可以使用相同长度的新数组进行测试,但具有不同的含义。 在loc中使用不同的值并测试相同的值。
14. Scipy CSGraph
14.1 图表示
首先,让我们了解一个稀疏图是什么以及它在图表示中的作用。
稀疏图是什么?
图只是节点的集合,它们之间有链接。 图几乎可以代表任何事物 - 社交网络连接,每个节点都是一个人,并且与熟人相连; 图像,其中每个节点是像素并连接到相邻像素; 指向一个高维分布,其中每个节点连接到最近的邻居; 实际上你可以想象的任何其他东西。
表示图形数据的一种非常有效的方式是在一个稀疏矩阵中: 假设名称为G。矩阵G的大小为N×N,并且G[i,j]给出节点'i'和节点之间的连接的值'J'。 稀疏图形包含大部分零 - 也就是说,大多数节点只有几个连接。
在scikit-learn中使用的几种算法激发了稀疏图子模块的创建,其中包括以下内容 -
Isomap - 流形学习算法,需要在图中找到最短路径。
分层聚类 - 基于最小生成树的聚类算法。
谱分解 - 基于稀疏图拉普拉斯算子的投影算法。
作为一个具体的例子,假设想要表示以下无向图 -
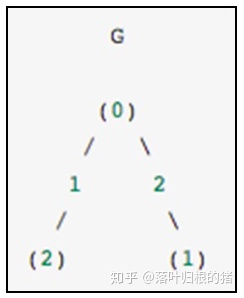
该图有三个节点,其中节点0和1通过权重2的边连接,节点0和2通过权重1的边连接。可以构造如下例所示的稠密,蒙板和稀疏表示,无向图由对称矩阵表示。
G_dense=np.array([[0,2,1],[2,0,0],[1,0,0]])
G_masked=np.ma.masked_values(G_dense,0)
from scipy.sparse import csr_matrix
G_sparse=csr_matrix(G_dense)
print(G_sparse.data)
上述程序将生成以下输出 -
array([2, 1, 2, 1])
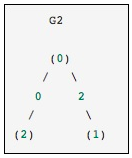
这与前面的图相同,只是节点0和2通过零权重的边连接。 在这种情况下,上面的稠密表示会导致含糊不清 - 如果零是一个有意义的值,那么如何表示非边缘。 在这种情况下,必须使用蒙版或稀疏表示来消除歧义。
from scipy.sparse.csgraph import csgraph_from_dense
G2_data=np.array([[np.inf,2,0],[2,np.inf,np.inf],[0,np.inf,np.inf]])
G2_sparse=csgraph_from_dense(G2_data,null_value=np.inf)
print(G2_sparse.data)
上述程序将生成以下输出 -
array([ 2., 0., 2., 0.])
使用稀疏图的词梯子
词梯是刘易斯卡罗尔发明的游戏,其中单词通过在每一步更改单个字母而链接在一起。 例如 -
APE → APT → AIT → BIT → BIG → BAG → MAG → MAN
在这里,分七步从“APE”到“MAN”,每次更换一个字母。 问题是 - 我们能否使用相同的规则在这些词之间找到更短的路径? 这个问题自然表示为一个稀疏图形问题。 节点将对应于单个单词,并且将创建最多不超过一个字母的单词之间的连接。
14.2 获取单词列表
首先,当然,我们必须获得有效的单词列表。如果使用Mac,并且Mac在以下代码块中给出的位置具有单词字典。 如果在其它的架构上,可能需要搜索一下才能找到你的系统字典。
wordlist=open('/usr/share/dict/words').read().split()
print(len(wordlist))
执行上面示例代码,得到以下结果 -
205882
现在想看长度为3的单词,选择正确长度的单词。 还将消除以大写字母(专有名词)开头的单词或包含撇号和连字符等非字母数字字符的单词。 最后,确保一切都是小写的,以便稍后进行比较。
word_list=[word for word in word_list if len(word)==3]
word_list=[word for word in word_list if word[0].islower()]
word_list=[word for word in word_list if word.isalpha()]
word_list=map(str.lower,word_list)
print(len(word_list))
执行上面示例代码,得到以下结果 -
1185
现在,列出了1185个有效的三个字母的单词(确切的数字可能会根据所使用的特定列表而变化)。 这些单词中的每一个都将成为图中的一个节点,我们将创建连接与每对单词关联的节点的边,这些节点之间的差异只有一个字母。
import numpy as np
word_list=np.asarray(word_list)
word_list.dtype
word_list.sort()
word_bytes=np.ndarray((word_list.size,word_list.itemsize),
dtype='int8',
buffer=word_list.data)
print(word_bytes.shape)
执行上面示例代码,得到以下结果 -
(1185,3)
我们将使用每个点之间的汉明距离来确定连接哪些单词对。 汉明距离度量两个向量之间的条目分数,它们不同:汉明距离等于1/N1/N的任何两个单词,其中NN是单词阶梯中连接的字母数。
from scipy.spatial.distance import pdist,squareform
from scipy.sparse import csr_matrix
hamming_dist=pdist(word_bytes,metric='hamming')
graph=csr_matrix(squareform(hamming_dist<1.5/word_list.itemsize))
比较距离时,不使用相等性,因为这对于浮点值可能不稳定。 只要字表中没有两个条目是相同的,不平等就会产生所需的结果。 现在,图形已经建立,我们将使用最短路径搜索来查找图形中任何两个单词之间的路径。
i1=word_list.searchsorted('ape')
i2=word_list.searchsorted('man')
print(word_list[i1],word_list[i2])
执行上面示例代码,得到以下结果 -
ape, man
我们需要检查它们是否匹配,因为如果单词不在列表中,输出中会有错误。 现在,需要在图中找到这两个索引之间的最短路径。使用dijkstra算法,因为它能够为一个节点找到路径。
from scipy.sparse.csgraph import dijkstra
distances,predecessors=dijkstra(graph,indices=i1,return_predecessors=True)
print(distances[i2])
执行上面示例代码,得到以下结果 -
5.0
因此,我们看到ape和man之间的最短路径只包含五个步骤。可以使用算法返回的前辈来重构这条路径。
path=[]
i=i2
whilei!=i1:
path.append(word_list[i])
i=predecessors[i]
path.append(word_list[i1])
print(path[::-1]i2])
上述程序将生成以下输出 -
['ape', 'ope', 'opt', 'oat', 'mat', 'man']
15. Scipy空间
scipy.spatial包可以通过利用Qhull库来计算一组点的三角剖分,Voronoi图和凸壳。 此外,它包含用于最近邻点查询的KDTree实现以及用于各种度量中的距离计算的实用程序。
15.1 Delaunay三角
下面来了解Delaunay Triangulations是什么以及如何在SciPy中使用。
什么是Delaunay三角?
在数学和计算几何中,对于平面中离散点的给定集合P的Delaunay三角剖分是三角形DT(P),使得P中的任何点都不在DT(P)中的任何三角形的外接圆内。
可以通过SciPy进行相同的计算。 参考下面的一个例子。
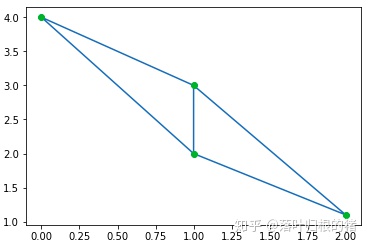
from scipy.spatial import Delaunay
points=np.array([[0,4],[2,1.1],[1,3],[1,2]])
tri=Delaunay(points)
import matplotlib.pyplot as plt
plt.triplot(points[:,0],points[:,1],tri.simplices.copy())
plt.plot(points[:,0],points[:,1],'o')
plt.show()
上述程序将生成以下输出 -
15.2 共面点
下面了解共面点是什么以及它们如何在SciPy中使用。
什么是共面点?
共平面点是三个或更多点位于同一平面上。 回想一下,一个平面是平坦的表面,其在所有方向端延伸没有终点。 它通常在数学教科书中显示为四面体。
下面来看看如何在SciPy中使用它,参考下面的例子。
from scipy.spatial import Delaunay
points=np.array([[0,0],[0,1],[1,0],[1,1],[1,1]])
tri=Delaunay(points)
print(tri.coplanar)
上述程序将生成以下输出 -
array([[4, 0, 3]], dtype = int32)
这意味着顶点4位于三角形顶点0和顶点3附近,但不包含在三角中。
15.3 凸壳
下面来了解什么是凸壳,以及它们如何在SciPy中使用。
什么是凸壳?
在数学中,欧几里德平面或欧几里德空间(或更一般地说,在实数上的仿射空间中)中的一组点X的凸包或凸包是包含X的最小凸集。
参考下面的例子来详细了解它 -
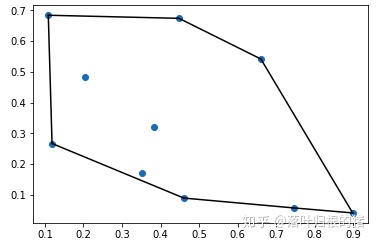
from scipy.spatial import ConvexHull
points=np.random.rand(10,2) # 30 random points in 2-D
hull=ConvexHull(points)
import matplotlib.pyplot as plt
plt.plot(points[:,0],points[:,1],'o')
for simplex in hull.simplices:
plt.plot(points[simplex,0],points[simplex,1],'k-')
plt.show()
参考:https://docs.python.org/3/
https://www.yiibai.com/scipy/scipy_introduction.html














 533
533











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









