






JEEK
容易脸红的编程大神

本文的内容重心是对于利用hive数据分析的过程中的一些常用技巧的总结,适合对hive有一定的基础用户。因此这里会省略很多关于基础概念的介绍,把有限的文本用在干货上。希望在读完本文后利用hive数据分析的能力能达到一个较高的层次。
1 让hive支持增删改查
通过select和insert into可以比较容易的实现查找和增加的操作,但是要实现行级的删除和修改操作就很费劲了,这里推荐一种通过insert overwrite实现删,改的方式。
删除:insert overwrite tmp1 select * from tmp1 where id != '123';
修改:insert overwrite tmp1 select id,label,if(id = '1' and label = 'age','25',value) as value from tmp1 where id != '123';
2 行转列,列转行
行列转换是在数据分析中经常遇见的问题。下面对这两类问题会再分不同层次的提供解决方案。(在阅读本节内容时如果你疑惑为什么要有“行表”和“列表”请等等,这个会在后面详述,因为这个问题远比行列转换要复杂)
行转列:
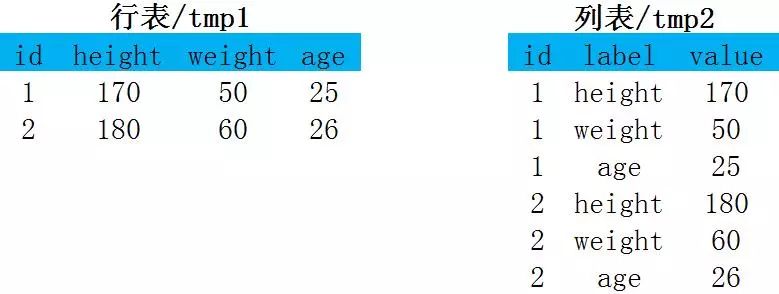
实现方式1:最简单粗暴union all
select id,'height' as label,height as value from tmp1 union all select id,'weight' as label,weight as value from tmp1 union allselect id,'age' as label,age as value from tmp1;这种方法最好理解,但是随着union all 字段的增多,计算量也是成倍增加。除了多张不同的表在数据拼接时会用到,一般避免这类操作。
实现方式2:一招鲜吃遍天的lateral view explode
--最后将info的内容切分select id,split(info,':')[0] as label,split(info,':')[1] as valuefrom ( --先将数据拼接成“height:180,weight:60,age:26” select id,concat('height',':',height,',','weight',':',weight,',','age',':',age) as value from tmp1) as tmp1--然后在借用explode函数将数据膨胀至多行lateral view explode(split(value,',')) mytable as info;方式二在多字段的展开效率上的优势是毋庸置疑的。explode函数的掌握和熟练利用可以帮助你更灵活的玩转hive。
列转行:
实现方式一:简单粗暴join
select tmp1.id as id,tmp1.value as height,tmp2.value as weight,tmp3.value as age from (select id,label,value from tmp2 where label = 'height') as tmp1joinon tmp1.id = tmp2.id(select id,label,value from tmp2 where label = 'weight') as tmp2joinon tmp1.id = tmp2.id(select id,label,value from tmp2 where label = 'age') as tmp3on tmp1.id = tmp3.id;通过join实现行转列的方式面临的问题和通过union all显现列转行一样,随着字段的增加计算量也将成倍增加。除了多张不同的表在数据拼接时会用到,一般避免这类操作。
实现方式2:一招鲜吃遍天的group聚合
通过group聚合后可以有多种方式实现行转列,这里推荐一种比较优雅的实现
selectid,tmpmap['height'] as height,tmpmap['weight'] as weight,tmpmap['age'] as agefrom ( select id,str_to_map(concat_ws(',',collect_set(concat(label,':',value))),',',':') as tmpmap from tmp2 group by id) as tmp1;这里首先通过concat将列名和对应的值连接起来;再将每一个id的全部数据用concat_ws+collect_set的方式平在一起;最后用str_to_map将每一个id的数据转为map类型。
在嵌套外面就可以很灵活很优雅的取出每一列了。
备注:
如果数据有重复怎么办?
如果有空值怎么办?
如果关联后对不齐怎么办?
具体情况具体处理
3 行表和列表:
在经历前面行列转换后对行表和列表应该很有感觉了。但是想要对其做一个非常全面的介绍还是是不太容易,因为这确实是一个比较复杂又没完全统一结论的命题。先讲一个小例子,“菜鸟的我为了记录每个用户每天个小时段内耗电量,我将表设计成0_h,1_h,2_h……23_h。只要一条select,不同用户在不同小时内耗电情况就可以看得很清楚。直到有一天我需要算平均每个用户每小时的耗电量select avg(0_h), avg(1_h), avg(2_h), avg(3_h), avg(4_h)……,好蠢的代码,好傻的设计”。

如上图,对行列表常见的特征做了一个比较,还有一点就是行表在做一些计算操作的时候真的很麻烦。
在此根据不同的使用情况给出一些建议。当对表结构和字段内容十分明确和固定时采用行表。如机型特征维表,

用了两个月了,100多个依赖任务。直到老大说加个分辨率吧……
当表中的字段要求能灵活扩展时采用列表。如对推荐结果的指标统计,
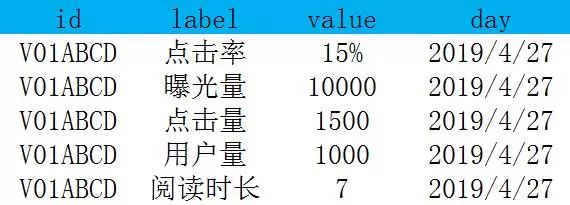
当有新的指标过来的时候可以一直往下加,即便是将推荐策略扩展成ABtest,每一个指标要分多个号段监控也是没问题的。
如果要更深刻的理解行表和列表的用处,建议直接去补充一下数仓的知识。在数据分析的过程中要保证整个流程的稳定和健壮,修改表结构是极其不推荐的。所以每一个create table操作请慎重。另外一个野路子的补救方案是:在字段中采用可扩张的数据结构如map,json;然后再加一层清洗和抽取的操作……
4 开窗函数的妙用:
开窗函数也是对数据分组聚合,不同于聚合函数的是对于每个分组可以返回多行,而聚合函数只能返回一行。开窗函数指定了分析函数工作的数据窗口大小,这个数据窗口大小可以根据传入的参数灵活的调节。
基础结构:Windowing functions|Analytics functions + The OVER clause
Windowing functions:LEAD,LAG,FIRST_VALUE,LAST_VALUE
Analytics functions:RANK,ROW_NUMBER,DENSE_RANK,CUME_DIST,PERCENT_RANK,NTILE
窗口函数和分析函数在用法上基本一致,只是hive的官方文档上做了这个分类,此处我就照搬一下
The OVER clause:over函数是用来控制窗口的大小的,
其他:标准准聚合(count,sum,min,max,avg),partition by,order by配合over子句使用可以很灵活在窗口内分析数据
下面通过一段简单的代码认识一下开窗函数的效果:
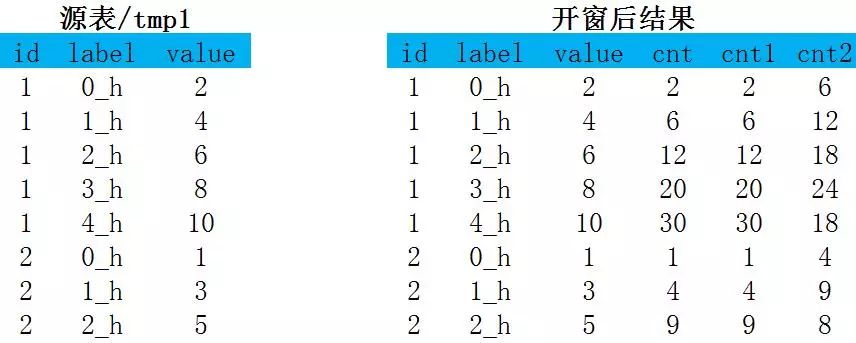
select id,label,value,sum(value)over(partition by id order by label) as cnt,sum(value)over(partition by id order by label rows between unbounded preceding and current row) as cnt1,sum(value)over(partition by id order by label rows between 1 preceding and 1 following) as cnt2from tmp再看over子句的写法:
over(partition by id order by label rows between 1 preceding and 1 following)partition by决定了分组的依赖的字段
order by控制数据的排列顺序
rows用以控制实际函数计算的窗口范围,定义规范可参见下图:

Windowing functions示例:
lead(col,n,default),在分组内将col列的数据往上n行(默认1),default默认为null;
lag(col,n,default),在分组内将col列的数据往下n行(默认1),default默认为null;
first_value,在分组内截止到当前行的第一个值;
last_value,在分组内截止到当前行的最后一个值。
select id,label,value,lead(value,1,0)over(partition by id order by label) as lead,lag(value,1,999)over(partition by id order by label) as lag,first_value(value)over(partition by id order by label) as first_value,last_value(value)over(partition by id order by label) as last_valuefrom tmp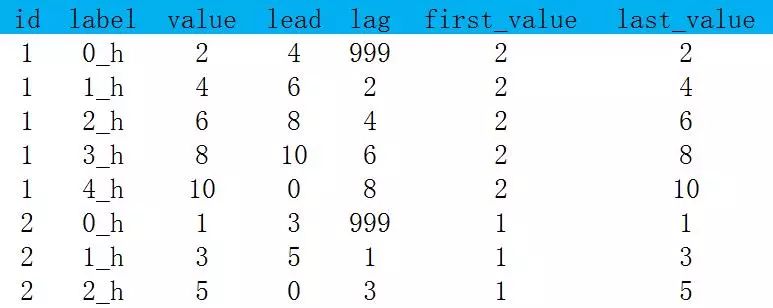
为了比较row_number,rank,dense_rank的差别将数据做了一点修改,并把结果放在一起方便比较
Analytics functions示例:
row_number:返回分组内的排名,排名结果唯一;
rank:返回分组中的排名,排名相等会在名次相同,会留下空位;
dense_rank:返回分组中的排名,排名相等会在名次相同,不会留下空位。
select id,label,value,row_number()over(partition by id order by value) as row_number,rank()over(partition by id order by value) as rank,dense_rank()over(partition by id order by value) as dense_rankfrom tmp;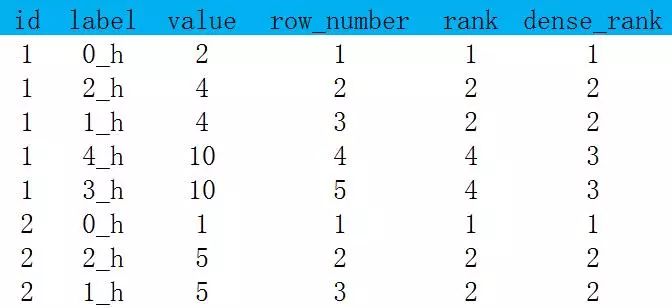
其余函数不太常用,就不再赘述。
ps.一次某同事面试结束回来跟说:“我出了一个题,在一张保留了用户一个月登陆历史的表中怎么抽出有连续7天登陆的用户?”。能实现的方法有很多,但是借用窗口函数一定是最优雅的方式。
先对用户分组并将登陆日期升序排列,再将日期列用lag往下6行,datediff('原始日期',lag结果列)=6。
5 加强版聚合操作
hive所提供的Enhanced Aggregation, Cube, Grouping and Rollup,对聚合计算带来了极大的改善和便利。一些多维数据分析平台实现预计算的本质也就是利用了这些操作。如kylin
Grouping SETS:用来在一条group语句中定义多种聚合项。逻辑上可以被理解成多条独立的group结果的union。
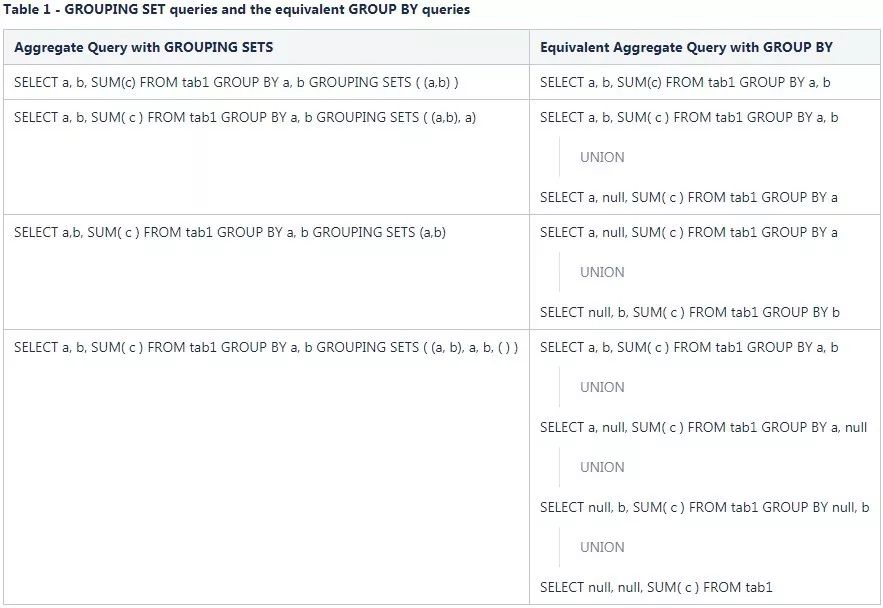
一般的数据分析中如果只是几个简单字段的组合聚合还不会有太大问题,一旦涉及的组合情况太多,每个组合中的结果又很复杂,那么执行结果对人类阅读就很不友好。因为结果中会充斥着太多的NULL值。除此之外如果字段本身也包含NULL分辨起来就更难了,所以有了Grouping__ID函数,Grouping__ID将参与group by的字段记为1没参与的记为0.组织成一个二进制,最终返回这个二进制结果的10进制数作为id。在下面的结果中我会对分组结果给出详细的标识和对group_id还原到二进制。
select col1,col2,col3,count(1),Grouping__ID from tmp group by col1,col2,col3grouping sets(col1,col2,col3,(col1,col2),(col1,col3),(col2,col3),())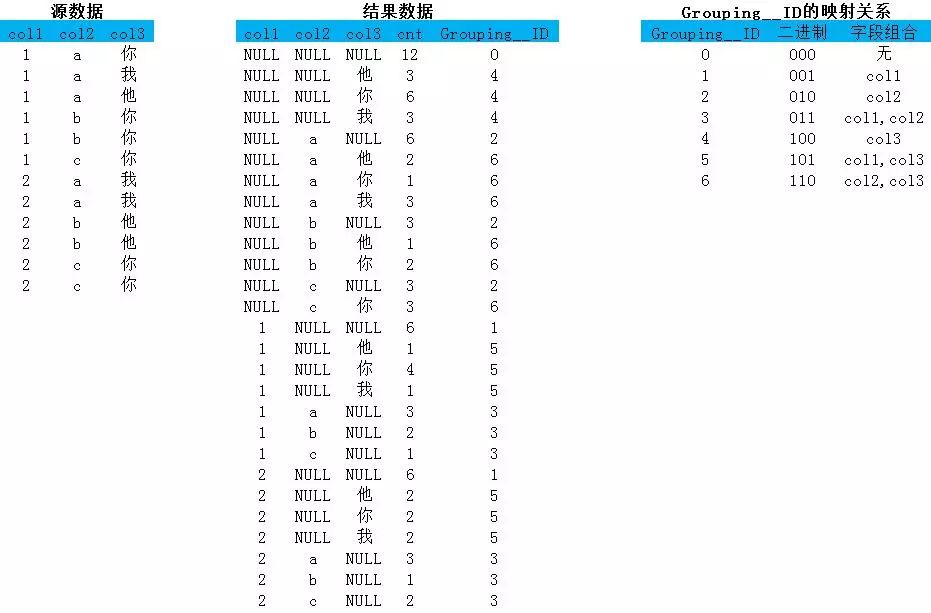
Cubes and Rollups:这两个也是kylin里面重要的概念,本质上它们都可以转化成相应的grouping SETS操作。
GROUP BY a,b,c WITH CUBE 相当于
GROUP BY a,b,c GROUPING SETS ((a,b,c),(a,b),(b,c),(a,c),(a),(b),(c),())
GROUP BY a,b,c, WITH ROLLUP 相当于
GROUP BY a,b,c GROUPING SETS ((a,b,c),(a,b),(a),()).
值得注意的是当组合种类T相当于在map段将一条数据膨胀到T条,对map段的聚合计算带来压力。hive中通过hive.new.job.grouping.set.cardinality来配置一次操作中组合的上限,
当T的数量超过集群hive.new.job.grouping.set.cardinality的值是就会增加额外的MR任务。
6 数据倾斜问题
如何发觉任务中出现了数据倾斜:
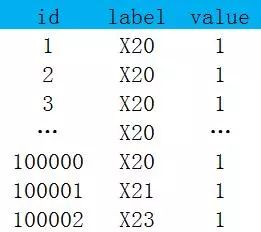
从原理上说在进行shuffle的时候会把相同key的数据分配到相同的reduce上去处理,比如join的操作时相同的关联键,group by时相同的分组,如果某个key的数据量太大就会导致个别reduce执行过慢(我们一般讨论reduce阶段的数据倾斜,因为map阶段发生数据倾斜的概率很小),相比其他reduce可能会花费数倍升至数十倍的时间,从而导致整个mapreduce任务花费的时间大大增加。下图就是一个例子,数据相同机型的数据被分到同一个reduce,负责X20这个reduce要处理的数据量就会多于其他。
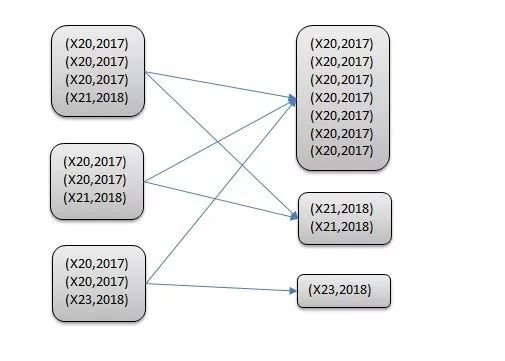
如果是对自己数据分布足够了解,那在执行之前对于这个任务的数据倾斜情况就应该心中有数。
借助日志发现问题。不是所有跑的慢的任务都是数据倾斜,最方便的是借用yarn的日志来检查任务运行状态。
1,查看各个reduce执行的时间

这任务还剩下的这两个reduce执行的过长。
2,再点logs查看各个container详细日志,

这是一个用经纬度做关联键的关联操作。这个日志的意思是关联操作中的一张表(table 0)在[23.1,113.26]上有8000条数据。因为多次才把数据拉取完,所以会有多条日志直到最后才估算出这个关联键下这张表有8000条数据。假设另一张表也有8000条,那么关联后的结果就有6400万条数据会分配到同一个reduce上去执行,当然会很耗时。
数据倾斜的解决方案
Level1............跳过
Level2............跳过
Level3............跳过
......................跳过
常见的解决方案就省略了,直接上应对数据倾斜的大杀器“随机数”大法。这个也是其他很多解决方式的根本思路,也有助于进一步理解倾斜的本质。
Group下的“随机数”大法:
对下面数据按照label分组并对value求和(负责计算X20的reduce会比其他reduce慢很多)
优化代码:
第一步:构造一个保留两位小数的随机数
第二步:这次会根据rd+label两个键来分配reduce,数据量较大的label理论上会被均分到100个reduce上,这样就均分了之前那一个reduce的压力
第三步:将第一次分组计算的结果再聚合一次求和。经过一次聚合后数据量已经下降了很多,每个分组最多100条数据
select label,sum(cnt) as all from ( select rd,label,sum(1) as cnt from ( select id,round(rand(),2) as rd,value from tmp1 ) as tmp1 group by rd,label) as tmp1group by label;join下的“随机数大法”:
对下面数据按照label先关联再对value求和。直接关联两张表的X20的数据会膨胀到100万条,并且由一个reduce处理。
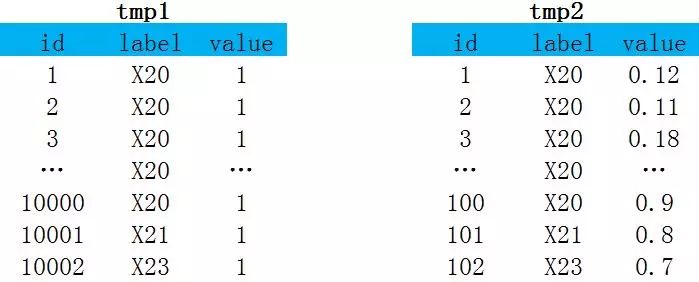
优化代码:
第一步:对tmp1构造一个小数点后一位的随机数rd
第二步:选择一张小表tmp2,每条数据复制10遍,区别在于这10条都有一个0.0-0.9之前不同的随机数rd
第三步:选着label+rd关联,此时的关联既不会产生数据丢失,又可以对每个label下的数据均分10分给不同的reduce,关联阶段的倾斜问题就已经解决
第四步:用label+rd聚合
第五步:用label聚合
select label,sum(value) as all from ( select rd,label,sum(value) as cnt from ( select tmp1.rd as rd,tmp1.label as label,tmp1.value*tmp2.value as value from ( select id,round(rand(),1) as rd,label,value from tmp1 ) as tmp1 join ( select id,rd,label,value from tmp2 lateral view explode(split('0.0,0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9',',')) mytable as rd ) as tmp2 on tmp1.rd = tmp2.rd and tmp1.label = tmp2.label ) as tmp1 group by rd,label) as tmp1group by label;注意:这种方法会导致tmp2的数据完整的增加10倍,虽然减少了个别reduce执行的时间,但是整个任务执行的数据量是增加的。
参考文献
[1]https://blog.csdn.net/Abysscarry/article/details/81408265
[2]https://tech.meituan.com/2016/04/29/spark-tuning-basic.html
[3]https://cwiki.apache.org/confluence/display/Hive/Configuration+Properties
[4]https://cwiki.apache.org/confluence/pages/reorderpages.action?key=Hive
[5]https://cwiki.apache.org/confluence/display/Hive/LanguageManual+UDF#LanguageManualUDF-stack(values)
回顾上篇:
一张图带你入门Apache Kylin
















 3951
3951











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









