





stacking原理
以Kaggle的Titanic(泰坦尼克预测)入门比赛来讲解stacking的应用(两层!)。
数据的行数:train.csv有890行,也就是890个人,test.csv有418行(418个人)。
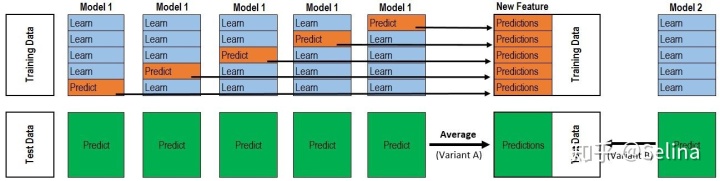
对于每一轮的 5-fold,Model 1都要做满5次的训练和预测。
Train Data有890行。(请对应图中的上层部分)
每1次的fold,都会生成 713行 小train, 178行 小test。我们用Model 1来训练 713行的小train,然后预测 178行 小test。预测的结果是长度为 178 的预测值。
这样的动作走5次! 长度为178 的预测值 X 5 = 890 预测值,刚好和Train data长度吻合。这个890预测值是Model 1产生的,我们先存着,因为,一会让它将是第二层模型的训练来源。重点:这一步产生的预测值我们可以转成 890 X 1 (890 行,1列),记作 P1 (大写P)接着说 Test Data 有 418 行。(对应图中的下层部分)。
每1次的fold,713行 小train训练出来的Model 1要去预测我们全部的Test Data(全部!因为Test Data没有加入5-fold,所以每次都是全部!)。此时,Model 1的预测结果是长度为418的预测值。
这样的动作走5次!我们可以得到一个 5 X 418 的预测值矩阵。然后我们根据行来就平均值,最后得到一个 1 X 418 的平均预测值。重点:这一步产生的预测值我们可以转成 418 X 1 (418行,1列),记作 p1 (小写p)
走到这里,你的第一层的Model 1完成了它的使命。
第一层还会有其他Model的,比如Model 2,同样的走一遍, 我们有可以得到 890 X 1 (P2) 和 418 X 1 (p2) 列预测值。
假设第一层有3个模型,这样就会得到:来自5-fold的预测值矩阵 890 X 3,(P1,P2, P3) 和 来自Test Data预测值矩阵 418 X 3, (p1, p2, p3)。
第二层:
来自5-fold的预测值矩阵 890 X 3 作为你的Train Data,训练第二层的模型
来自Test Data预测值矩阵 418 X 3 就是你的Test Data,用训练好的模型来预测他们吧。
模型融合stacking的代码
import numpy as np
from sklearn.model_selection import KFold
def get_stacking(clf, x_train, y_train, x_test, n_folds=10):
"""
这个函数是stacking的核心,使用交叉验证的方法得到次级训练集
x_train, y_train, x_test 的值应该为numpy里面的数组类型 numpy.ndarray .
如果输入为pandas的DataFrame类型则会把报错"""
train_num, test_num = x_train.shape[0], x_test.shape[0]
second_level_train_set = np.zeros((train_num,))
second_level_test_set = np.zeros((test_num,))
test_nfolds_sets = np.zeros((test_num, n_folds))
kf = KFold(n_splits=n_folds)
for i,(train_index, test_index) in enumerate(kf.split(x_train)):
x_tra, y_tra = x_train[train_index], y_train[train_index]
x_tst, y_tst = x_train[test_index], y_train[test_index]
clf.fit(x_tra, y_tra)
second_level_train_set[test_index] = clf.predict(x_tst)
test_nfolds_sets[:,i] = clf.predict(x_test)
second_level_test_set[:] = test_nfolds_sets.mean(axis=1)
return second_level_train_set, second_level_test_set
#我们这里使用5个分类算法,为了体现stacking的思想,就不加参数了
from sklearn.ensemble import (RandomForestClassifier, AdaBoostClassifier,
GradientBoostingClassifier, ExtraTreesClassifier)
from sklearn.svm import SVC
rf_model = RandomForestClassifier()
adb_model = AdaBoostClassifier()
gdbc_model = GradientBoostingClassifier()
et_model = ExtraTreesClassifier()
svc_model = SVC()
#在这里我们使用train_test_split来人为的制造一些数据
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
iris = load_iris()
train_x, test_x, train_y, test_y = train_test_split(iris.data, iris.target, test_size=0.2)
train_sets = []
test_sets = []
for clf in [rf_model, adb_model, gdbc_model, et_model, svc_model]:
train_set, test_set = get_stacking(clf, train_x, train_y, test_x)
train_sets.append(train_set)
test_sets.append(test_set)
meta_train = np.concatenate([result_set.reshape(-1,1) for result_set in train_sets], axis=1)
meta_test = np.concatenate([y_test_set.reshape(-1,1) for y_test_set in test_sets], axis=1)
#使用决策树作为我们的次级分类器
from sklearn.tree import DecisionTreeClassifier
dt_model = DecisionTreeClassifier()
dt_model.fit(meta_train, train_y)
df_predict = dt_model.predict(meta_test)
print(df_predict)
模型融合时stacking为什么有用?
融合后的期望风险≤单模型的期望风险















 3155
3155











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









