






本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理
以下文章来源于腾讯云 作者:昱良
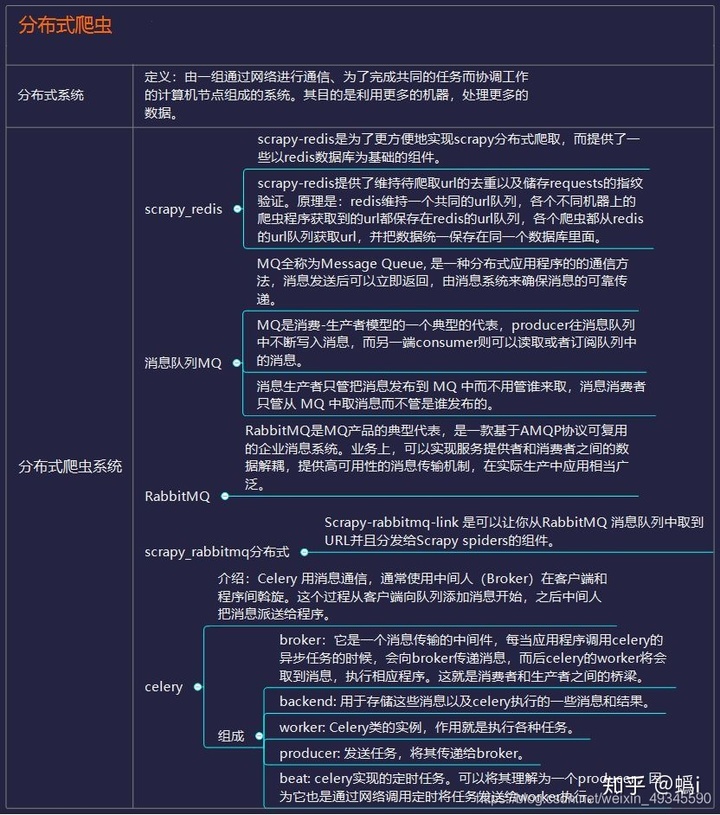
分布式爬虫
爬取基本数据已经没有问题,还能使用框架来面对一写较为复杂的数据,此时,就算遇到反爬,你也掌握了一些反反爬技巧。
你的瓶颈会集中到爬取海量数据的效率,这个时候相信你会很自然地接触到一个很厉害的名字:分布式爬虫。
分布式这个东西,听起来很恐怖,但其实就是利用多线程的原理将多台主机组合起来,共同完成一个爬取任务,需要你掌握 Scrapy +Redis+MQ+Celery 这些工具。
Scrapy 前面我们说过了,用于做基本的页面爬取, Redis 则用来存储要爬取的网页队列,也就是任务队列。
scarpy-redis就是用来在scrapy中实现分布式的组件,通过它可以快速实现简单分布式爬虫程序。
由于在高并发环境下,由于来不及同步处理,请求往往会发生堵塞,通过使用消息队列MQ,我们可以异步处理请求,从而缓解系统的压力。
RabbitMQ本身支持很多的协议:AMQP,XMPP, SMTP,STOMP,使的它变的非常重量级,更适合于企业级的开发。
Scrapy-rabbitmq-link是可以让你从RabbitMQ 消息队列中取到URL并且分发给Scrapy spiders的组件。
Celery 是一个简单、灵活且可靠的,处理大量消息的分布式系统。
支持 RabbitMQ、Redis 甚至其他数据库系统作为其消息代理中间件, 在处理异步任务、任务调度、处理定时任务、分布式调度等场景表现良好。
所以分布式爬虫只是听起来有些可怕,也不过如此。当你能够写分布式的爬虫的时候,那么你可以去尝试打造一些基本的爬虫架构了,实现一些更加自动化的数据获取。
推荐分布式资源:
- scrapy-redis文档 http://t.im/ddgk
- scrapy-rabbitmq文档 http://t.im/ddgn
- celery文档 http://t.im/ddgr
解锁每一个部分的知识点并且有针对性的去学习,走完这一条顺畅的学习之路,你就能掌握python爬虫















 533
533











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









