
YOLO原作者Joseph Redmon之前宣布退出CV界,CV界以为以后再无YOLO系列更新。谁能想到今年四月份有了一篇名为YOLOv4的文章,作者将很多好的trick组合得到了可以吊打一切的YOLOv4。最近又出来一个yolov5,惊不惊喜意不意外。ultralytics团队的大神发明了mosaic,Alexeyab(YOLOv4作者)将mosaic用在YOLOv4里面提高了AP,也得到了YOLO的原作者认可ultralytics团队不服气,认为 YOLOv4应该是属于他们的,但是被人占了没办法啊,就有了yolov5。
其实,我们看看YOLO系列就知道,v2相较于v1,很有诚意加了很多新东西,实实在在将模型的性能进行了提升,实现了第一次质的飞越,也确定了YOLO系列的风格;到了v3,又加入了FPN技术,实现了第二次质的飞越,到了今年的v4,虽然作者换成了AB大佬,但从中还是可以读出那味儿——有变化、有亮点,比如换了更好的骨干网络CSPDarkNet53,用更好的PAN取代FPN,同时也探讨了很多的新模块、损失函数、数据增强手段,优胜劣汰,最后v3进化到v4。而v5(姑且这样叫吧)只跟你比速度和精度,比你好就可以叫v5?
扯的有点远,闲话少叙。今天说说v2,如果你想全面了解YOLO系列,欢迎你持续关注我们的分享。v2相较于v1正如论文名字一样:Better、Faster、Stronger。Better、Faster主要介绍的是YOLO v2,而Stronger主要介绍的是YOLO9000。
Better
v1是利用全连接层直接预测目标的坐标,v2则借鉴了Faster R-CNN的思想,引入anchor(预先规定好的一系列检测框,回想一代YOLO是每个cell中提供若干个box来预测,但是没有对box的尺寸做预先设定,因此2代把box进一步优化,自然地采取了anchor的形式)。Faster R-CNN中anchor box的大小和比例是按经验设定的,然后网络会在训练过程中调整anchor box的尺寸。如果一开始就选择到合适尺寸的anchor box,那肯定可以帮助网络更好地预测,所以作者采用k-means的方式对anchor box的尺寸做聚类,找到合适的anchor box。
通过预测tx和ty来得到(x,y)值,也就是通过预测anchor box的偏移量的预测目标的位置坐标。Faster R-CNN中的公式如下:
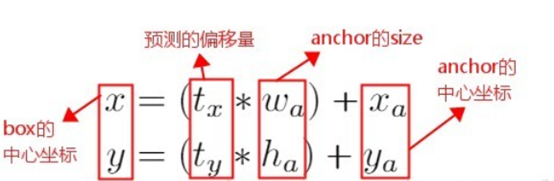
从公式中可以看出由于tx和ty无约束,预测的边界框很容易向任何方向偏移,因此,每个位置预测的边界框可以落在图片任何位置,这导致模型训练过程的不稳定性。
v2中没有采用这种预测方式,而是沿用了v1的方法,就是预测边界框中心点相对于对应cell左上角位置(红色三角)的相对偏移值,使用sigmoid函数将tx、ty归一化处理,将值约束在0~1,将bounding box的中心点约束在当前cell中,这使得模型训练更稳定。
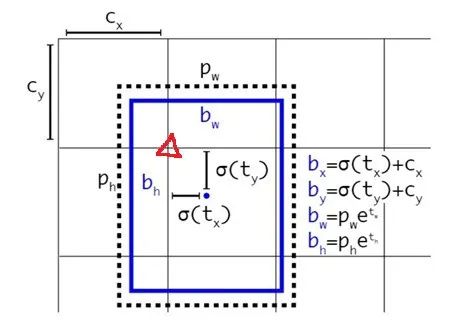
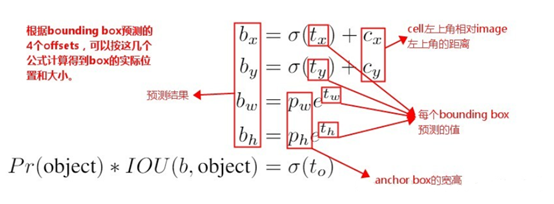
当然基于anchor来预测的公式表达与Faster-RCNN中保持一致,优化的部分就在于限定了偏置只能在一个cell的范围内,
v2为了更好地预测小目标,采用了称为pass through的特征融合方式,具体的操作建议大家好好看看源码的实现,好多网上的博文解释都是错的,虽然实现的效果是将上一级较大的特征图下采样(保证尺度一致)与当前较小一级的特征图进行拼接,而且大家再回头细读一下文章中说的是把相邻的特征图放到不同的通道上去。

v2中只有卷积层和池化层,因此不需要固定的输入图片的大小。为了让模型更有鲁棒性,作者引入了多尺度训练。就是在训练过程中,每迭代一定的次数,改变模型的输入图片大小。一共采用320、352、384、416、448、480、512、544、576、608共10种图片尺寸。
这一步是在检测数据集上微调时候采用的,不要跟前面在Imagenet数据集上的两步预训练分类模型混淆。
Faster
v1作者采用的训练网络是基于GooleNet,v2并不是通过加深或加宽网络达到效果提升,反而是简化了网络,v2作者采用了新的分类模型作为基础网络那就是Darknet-19。作为v2模型特征提取前端网络的darknet-19有19个Conv 层与5个maxpooling层。在此网络中引入了BN用于稳定训练加快收敛,同时防止模型过拟合。
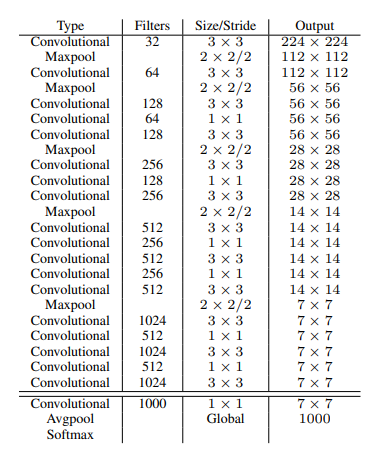
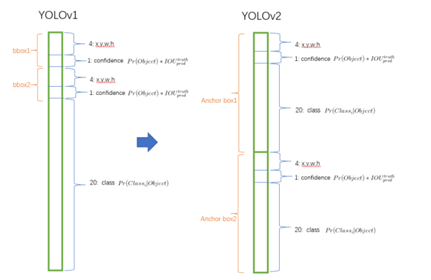
YOLO V2 的每个cell包含N个预测bounding box,每个bounding box有5个坐标值和C个类别值,所以每个cell有 N * (C + 5)个预测值。在v1中类别概率是由cell来预测的,一个cell对应的两个box共用同一个类别概率,但是在v2中,类别概率是属于box的,每个box对应一个类别概率,而不是由cell决定。
Stronger
YOLO9000是在v2的基础上提出的一种可以
检测超过9000个类别的模型,
其主要贡献点在于提出了一种分类和检测的联合训练策略。
当网络遇到一个来自检测数据集的图片与标记信息,那么就把这些数据用完整的 v2 loss 功能反向传播这个图片。
当网络遇到一个来自分类数据集的图片和分类标记信息,只用v2中分类部分的 loss 功能反向传播这个图片。在YOLO中,边界框的预测其实并不依赖于物体的标签,所以YOLO可以实现在分类和检测数据集上的联合训练。对于检测数据集,可以用来学习预测物体的边界框、置信度以及为物体分类,而对于分类数据集可以仅用来学习分类,但是其可以大大扩充模型所能检测的物体种类(不知道大家在实际工程中会不会这样训练?)。
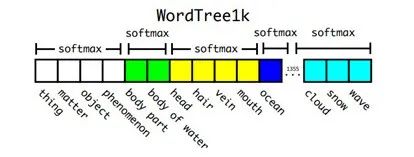
作者选择在COCO和ImageNet数据集上进行联合训练,遇到的问题是多个数据集间类别并不是完全互斥的,比如"Norfolk terrier"明显属于"dog",所以作者提出了一种层级分类方法(Hierarchical classification),主要思路是通过条件概率,建立一个分层树 WordTree,同时对相应的类别进行扩充。之前的 ImageNet 分类是使用一个大 softmax 进行分类,
在构建 WordTree 的情况下, 只需要对同一概念下的同义词进行 softmax 分类(互斥)。在给出某个类别的预测概率时,需要找到其所在的位置,遍历这个分枝路径,然后计算分枝路径上各个节点的概率之积。

好了以上就是我的好朋友杨巅峰跟大家分享的全部内容,其实以现在的眼光回头再看看YOLO的发展却还是津津有味的。最近入手了女神异闻录5S,不得不佩服制作团队的先进性,把AI的概念也放到了游戏里,想想如果自己不是在这一行业又会是如何看待这个新鲜词汇呢?





















 540
540











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









