





Data本节主要介绍Pandas在数据分析中的应用
pandas是一种快速,强大,灵活且易于使用的开源数据分析和处理工具,
建立在Python编程语言和numpy之上。主要特点如下:
具备按轴自动或显示数据对齐功能的数据结构
集成时间序列功能
数学运算简约
灵活处理缺失数据
合并关系型运算
pandas两大数据结构:Series and DataFrame
Series是一种类似于一维数组的对象,它由一组数组以及一组与之对应的标签组成。仅由一组数据即可产生最简单的series. 基本数据结构如下图所示:

常见操作如下:
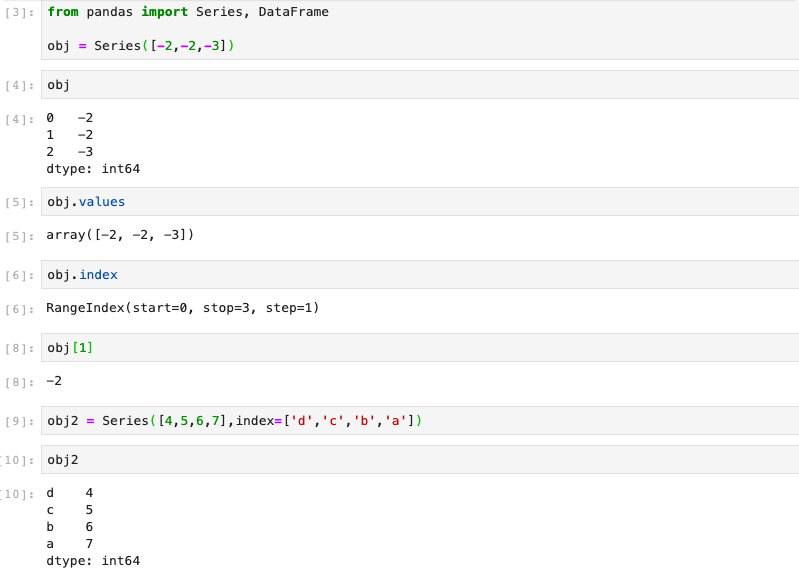
可以将Series 看成一个定长的有序字典,是索引值到数据的一个映射
DataFrame
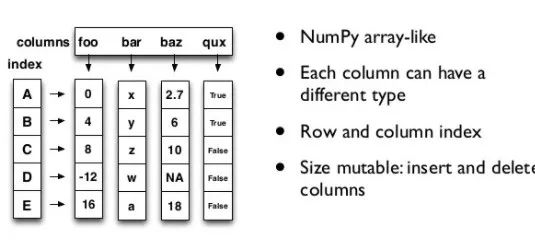
DataFrame是一种表格型数据结构,它包含有一组有序的列,每列可以是不同的值烈性。DataFrame既有行索引也有列索引,可以看做由series组成的字典。具体数据结构如图所示:
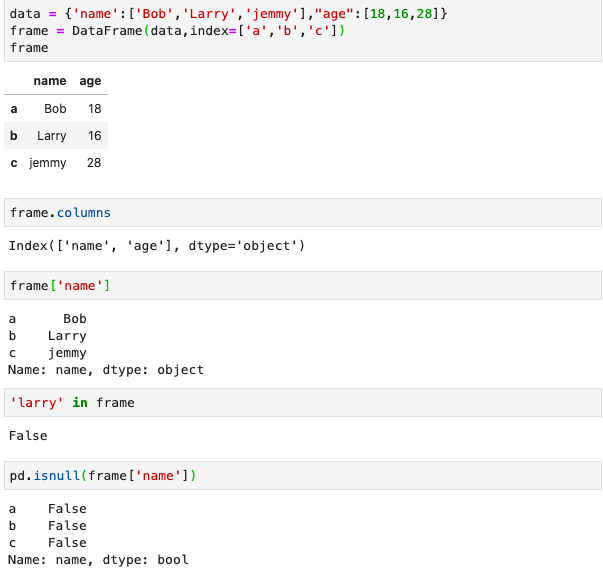
构建DataFrame数据结构,常见基本操作
算术运算中,自动对齐不同的索引数据
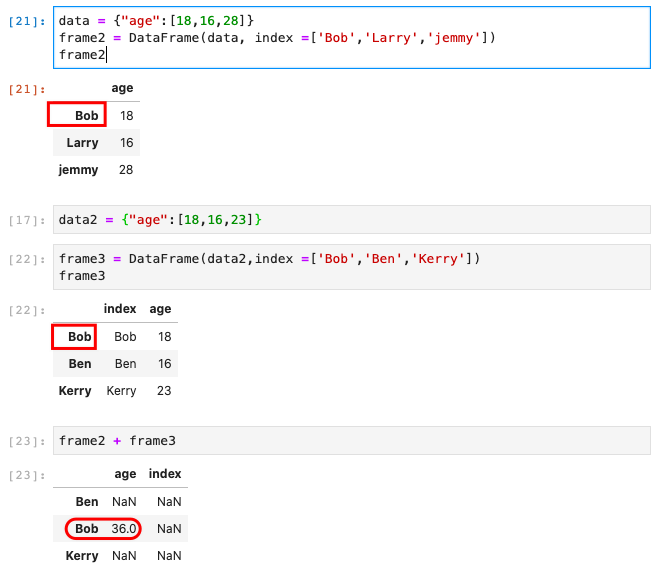
DataFrame构造器的数据

索引对象
负责管理轴坐标和其他元数据,构建Series和DataFrame时,所用到的任何数组或其他序列的标签都会被转换成一个Index, index的值无法修改,可以保证多个数据结构之前安全共享。
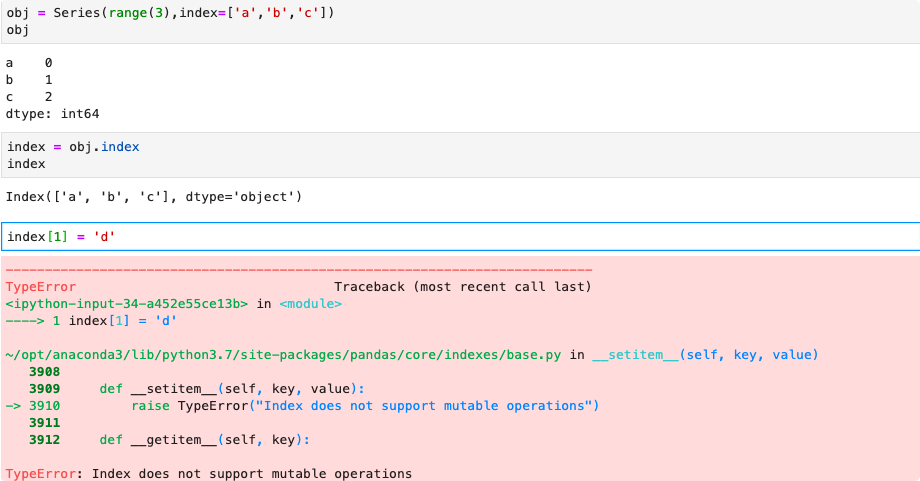
pandas中的主要index对象

index的方法和属性
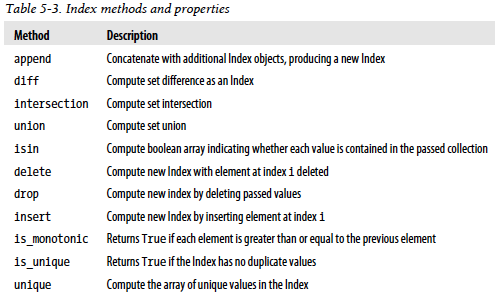
基本功能
介绍操作数据容器Series和DataFrame中的数据的基本手段。
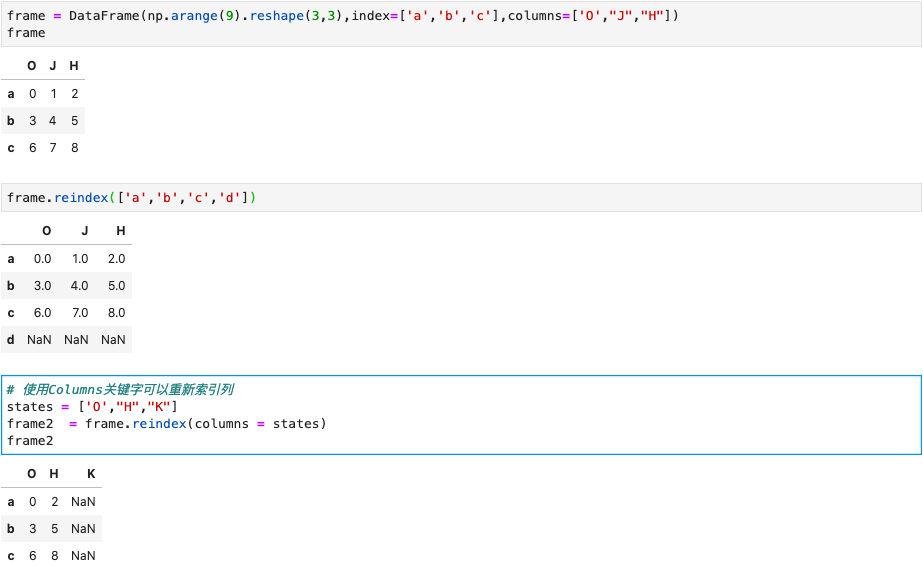
重新索引
pandas对象的一个重要方法是reindex,其作用是创建一个适应新索引的新对象。
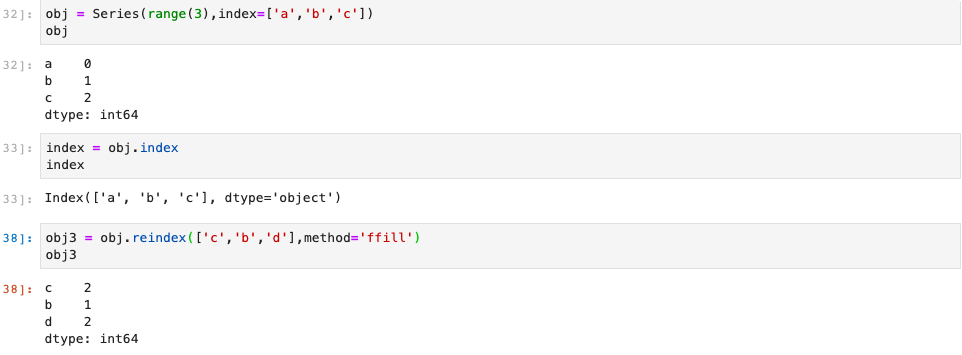

对于dataFrame,reindex可以修改(行)索引、列,或两个都修改。如果仅传入一个序列,则会重新索引行

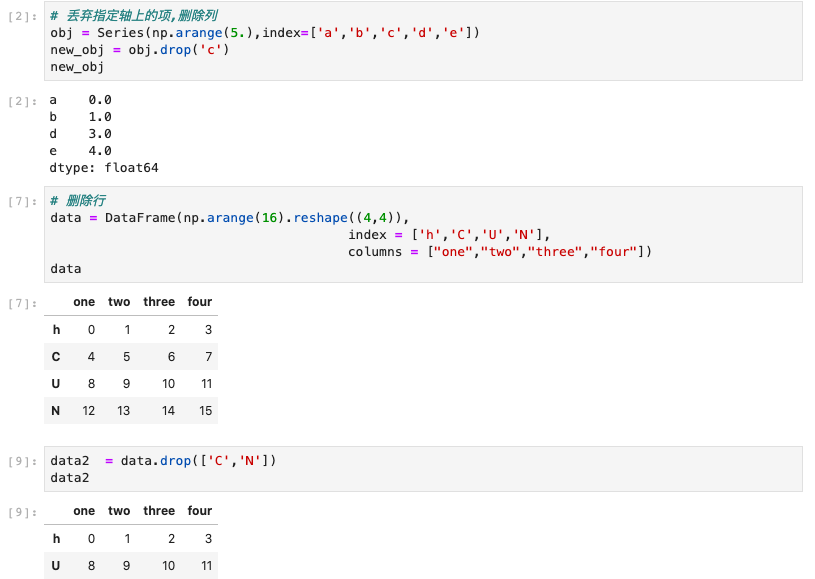
丢弃指定轴上的项
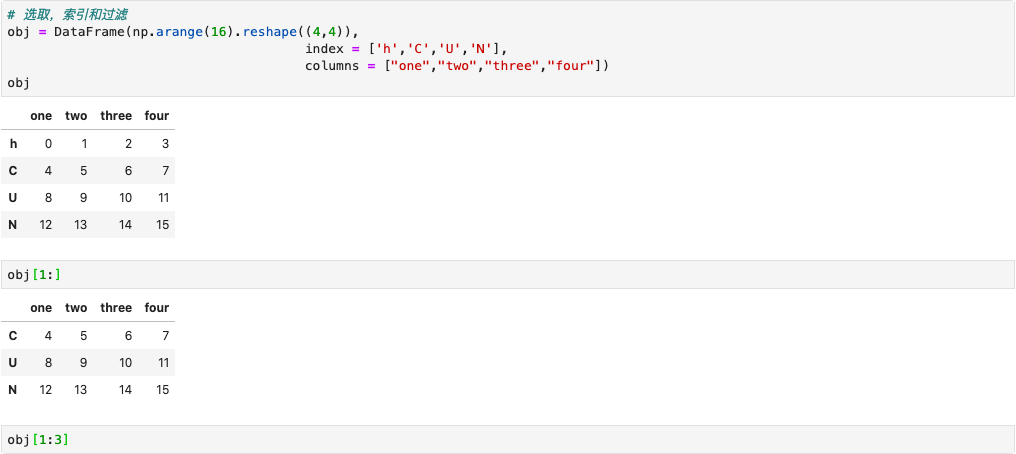
索引,选取和过滤
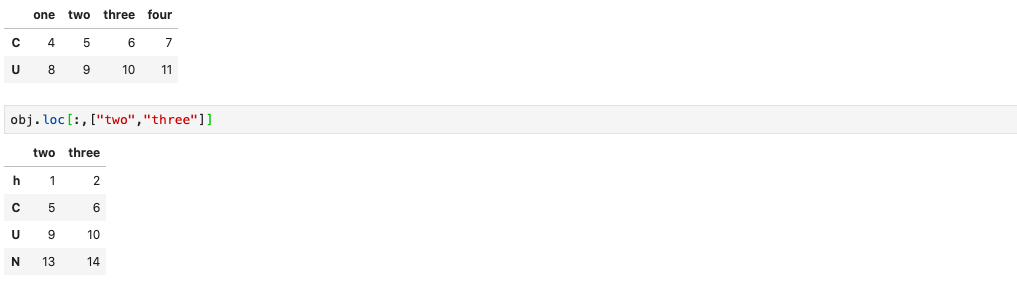
DataFrame 索引选项
DataFrame.atAccess a single value for a row/column label pair.
DataFrame.ilocAccess group of rows and columns by integer position(s).
DataFrame.xsReturns a cross-section (row(s) or column(s)) from the Series/DataFrame.
Series.locAccess group of values using labels.
算术运算和数据对齐
df1+df2
Equivalent to dataframe + other, but with support to substitute a fill_value for missing data in one of the inputs. With reverse version, radd.
Among flexible wrappers (add, sub, mul, div, mod, pow) to arithmetic operators: +, -, *, /, //, %, **.

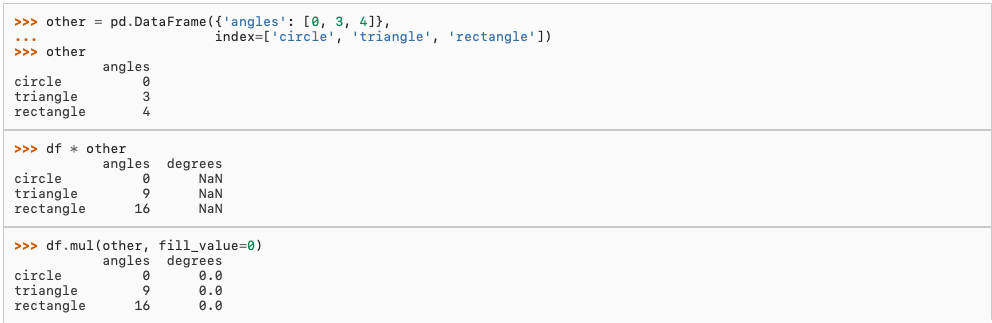

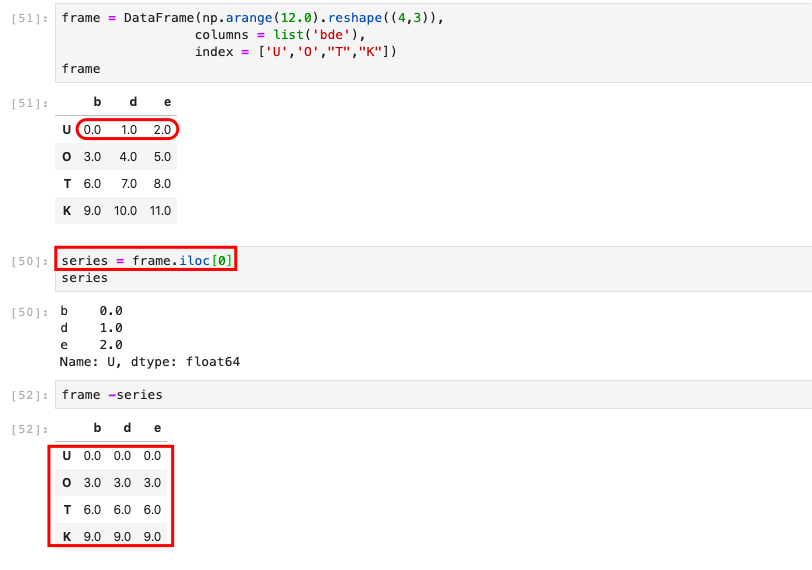
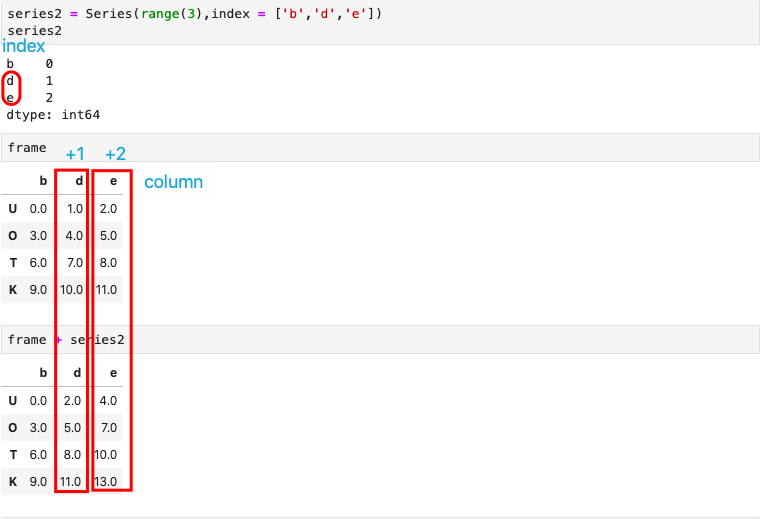
DataFrame和Series之间的运算
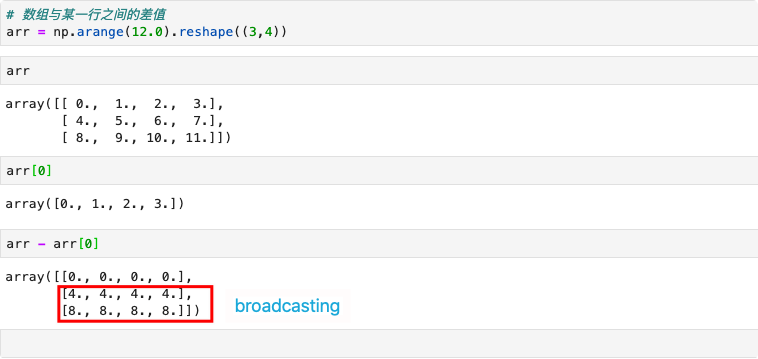
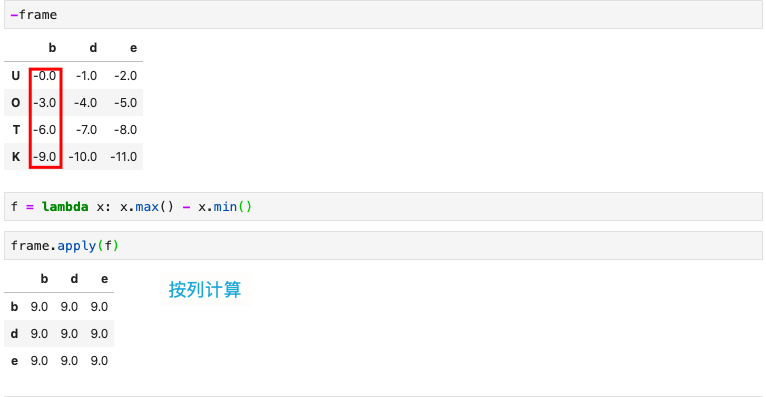
相减
函数应用与映射
排序和排名
根据条件对内置序列进行排序。要对行或列索引进行排序

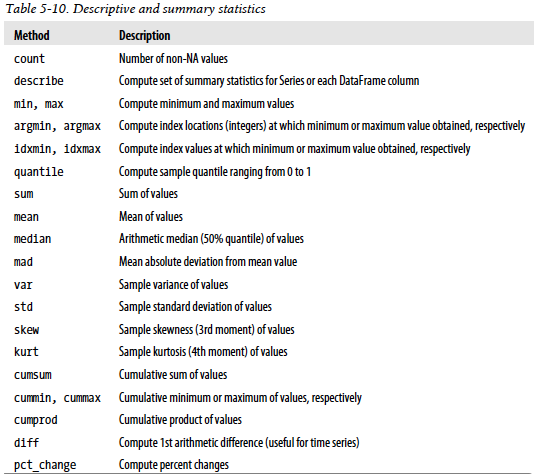
汇总和描述性统计

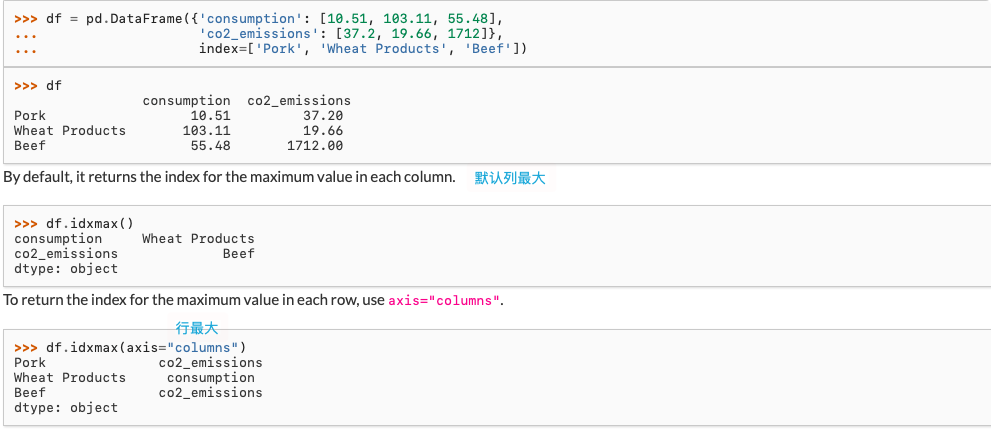
描述性统计函数
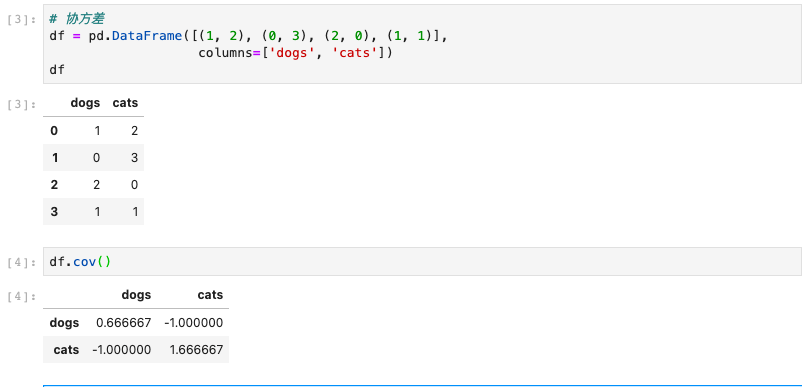
相关系数和协方差
数据基础
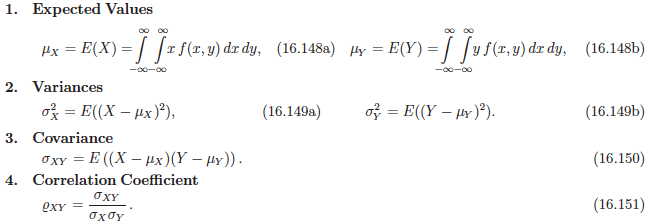

相关系数
协方差

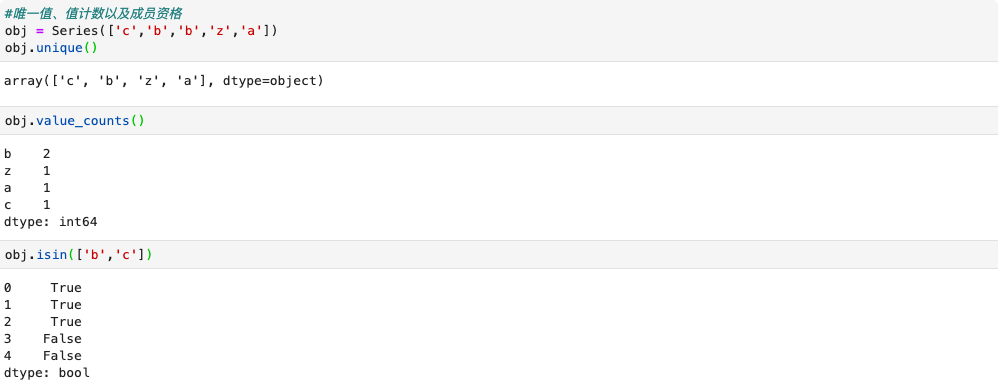
唯一值、值计数以及成员资格
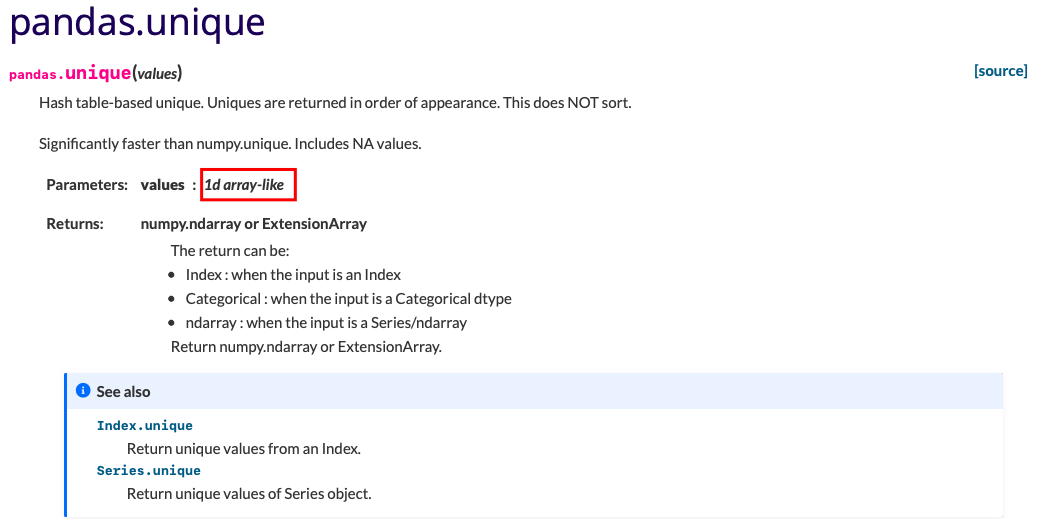
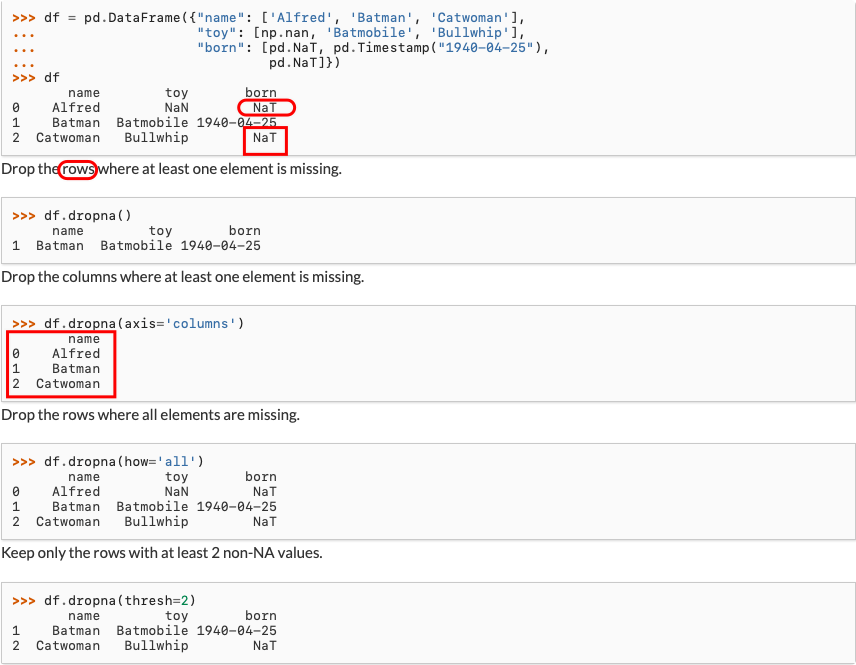
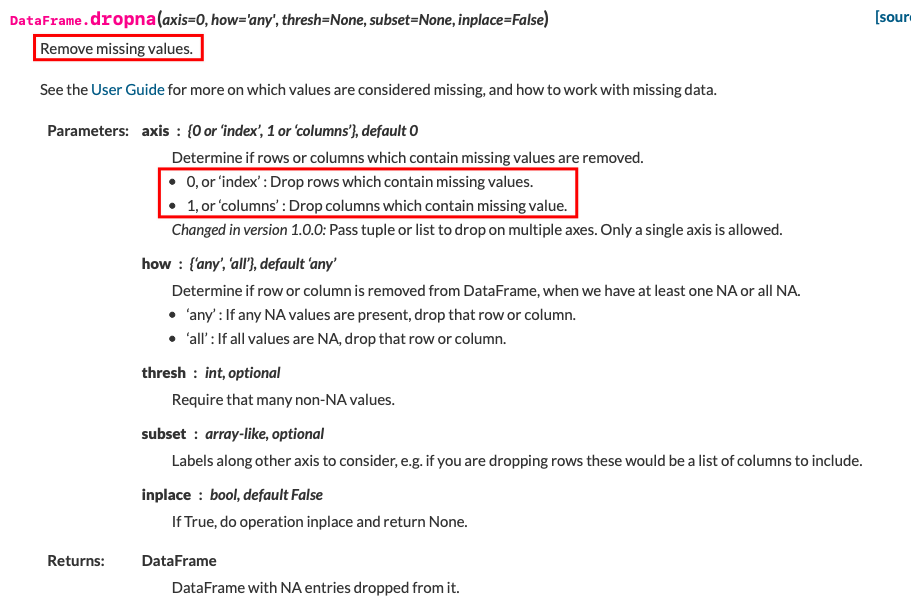
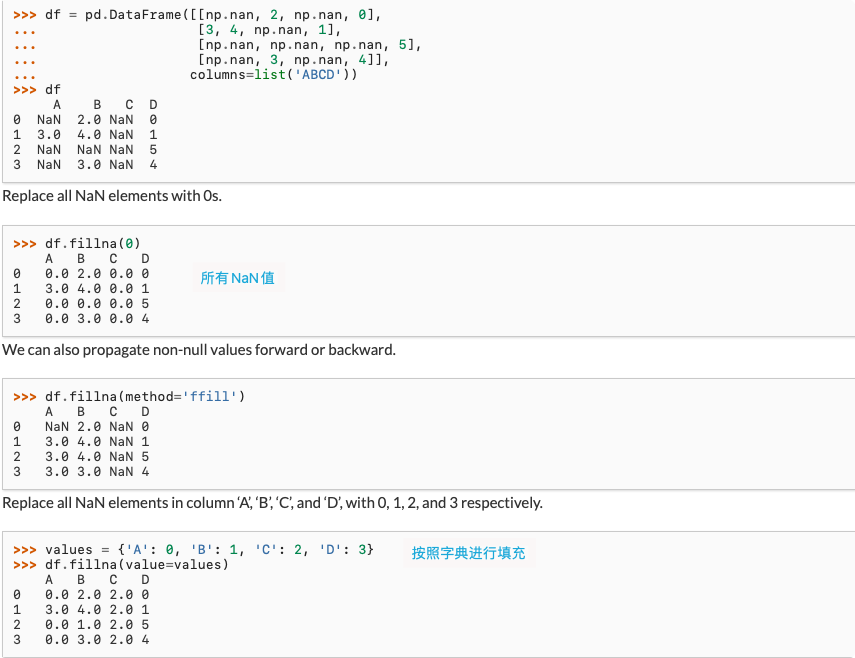
处理缺失数据


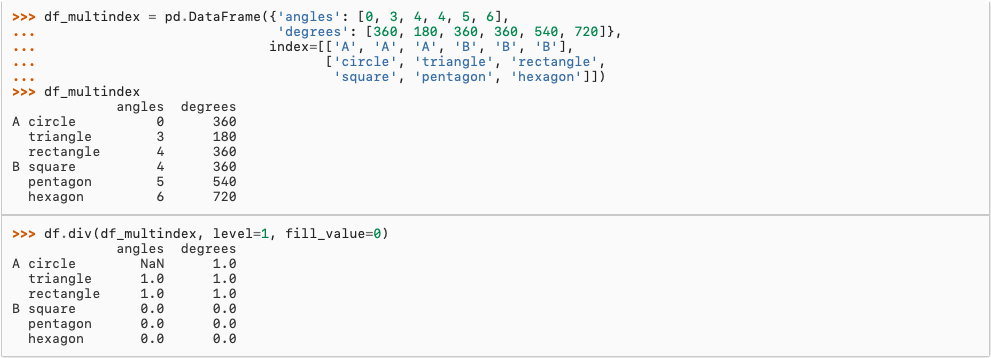
层次化索引
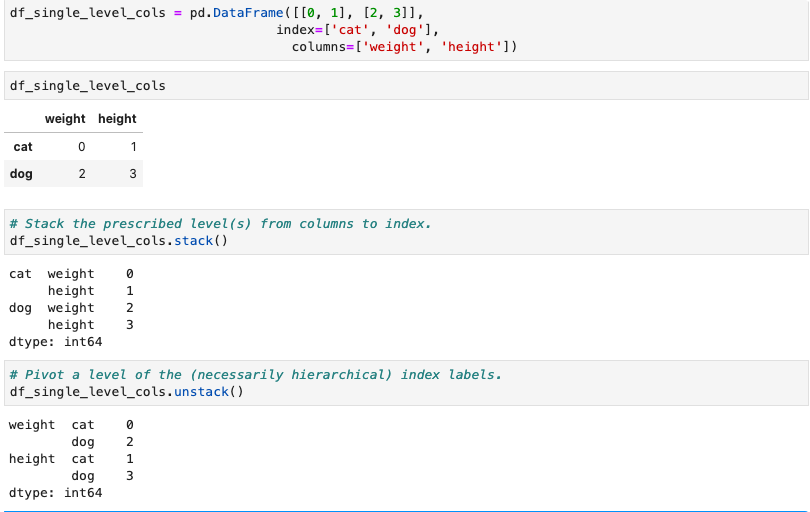
重排分级数据


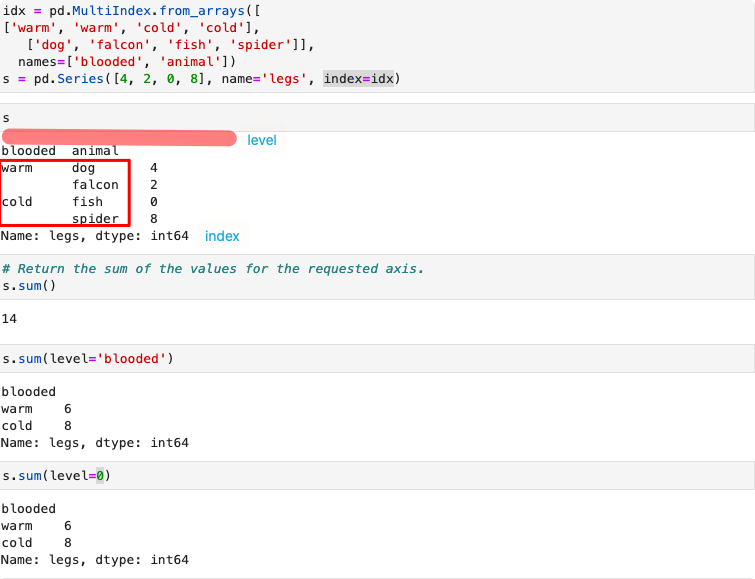
使用级别汇总统计
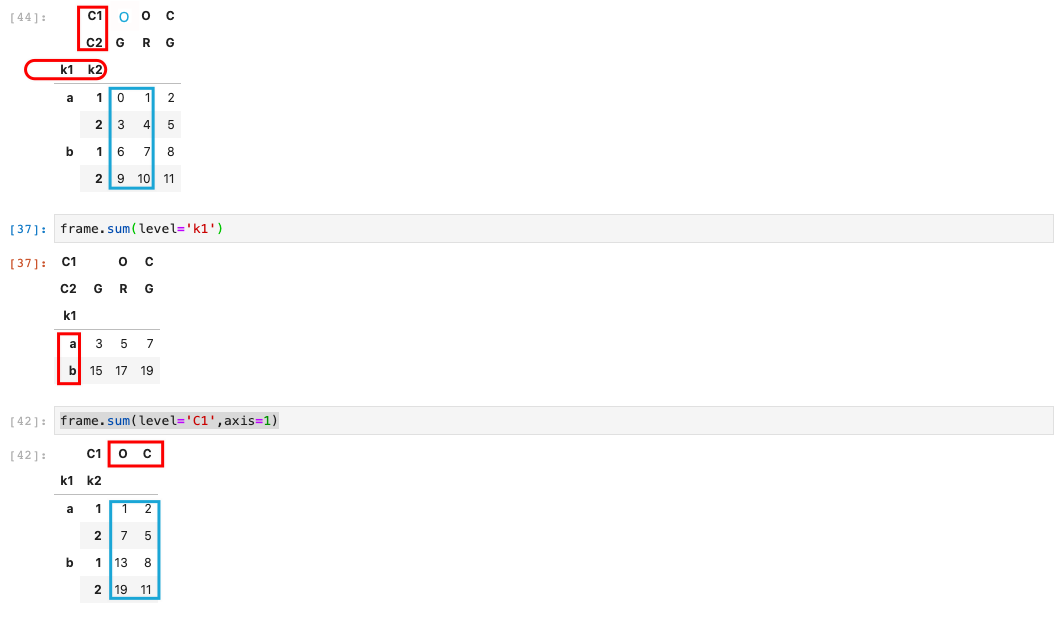
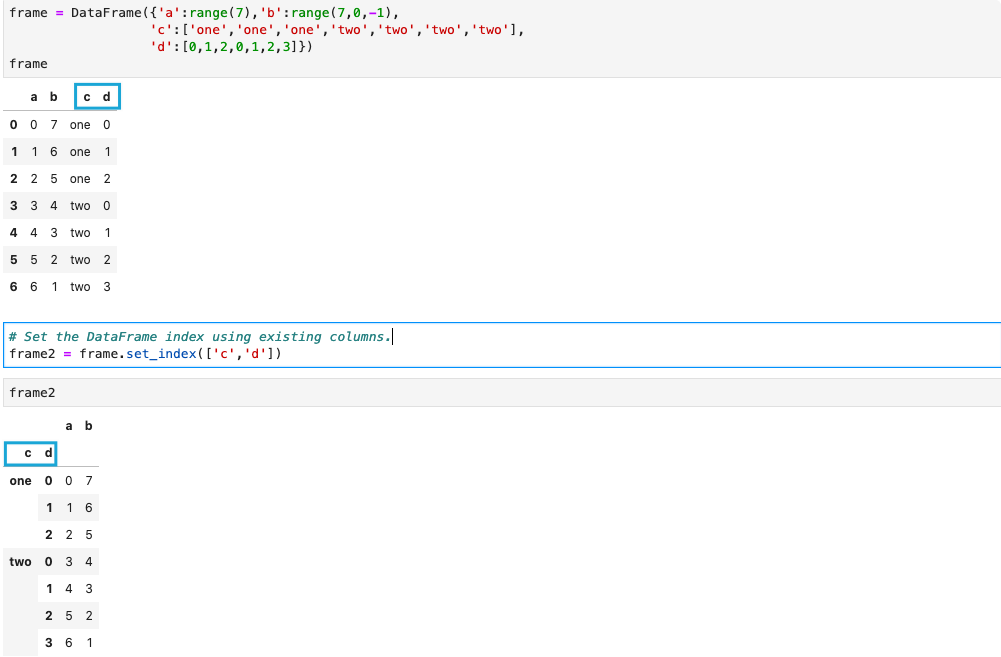
使用DataFrame的列
















 605
605











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









