








安装更新pandas:pip install pandas --upgrade i https://mirrors.163.com/pypi/simple/
Pandas的基础类型2.DataFrame创建修改提取数据
创建一个DataFrame类型的数据
df = pd.DataFrame([[1, 2], [4, 5], [7, 8]], #红色方括号里的是数据,一个逗号分隔一行,每行里边的方括号又以逗号分隔列
... index=['cobra', 'viper', 'sidewinder'], #index=[]表示各行的名称,包以引号,以逗号分隔行位
... columns=['max_speed', 'shield']) #columns=[]表示列的名称.在创建列表的时候,表示列名都在圆括号内设置.
>>> df
max_speed shield
cobra 1 2
viper 4 5
sidewinder 7 8df.loc['viper'] #有索引的时候
max_speed 4
shield 5
Name: viper, dtype: int64dict_data={ #这是以字典的形式提供数据
'student':['lilei','hanmeimei','madongmei'],
'score':[98,99,100],
'gender':['M','F','F']
}
data=pd.DataFrame(dict_data)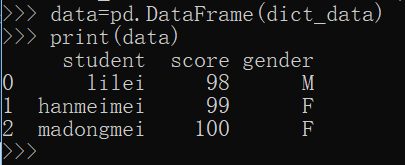
原字典的索引不再是索引了,成为列标题名字
指定DataFrame数据的列顺序
data=pd.DataFrame(dict_data,columns=['gender','student','score'])
指定DataFrame数据的索引值
data=pd.DataFrame(dict_data,columns=['gender','student','score'],index=['a','b','c'])
获取DataFrame数据的列名称
print(data.columns)
获取DataFrame数据中的某列数据
print(data['student']) #用类似字典的关键字
print(data.student) #用一个点.
两种方式都可.

获取DataFrame数据中的多列数据: #多个列字段,必需放在一个列表里[ ]
print(data[['student','age']])
获取DataFrame数据中某某行的数据
1.根据行编号序号
print(data.iloc[0]) #注意是iloc[ ] 4个字母
df = pd.DataFrame(mydict)df
a b c d
0 1 2 3 4
1 100 200 300 400
2 1000 2000 3000 4000df.iloc[行,列] 方括号里,有逗号出现则有列,无逗号则都时对行号的要求
df.iloc[0, 1] #0行,1列
2
type(df.iloc[0])
<class 'pandas.core.series.Series'>
>>> df.iloc[0] #以行号数字为查询关键字 结果是series对象
a 1
b 2
c 3
d 4
Name: 0, dtype: int64注意:上例df.iloc[0]与下列df.iloc[[0]],在显示的形式上有差别,数据类型上也有差别
df.iloc[[0]]
a b c d
0 1 2 3 4
>>> type(df.iloc[[0]]) #以列表形式[]为查询关键字,结果是DataFrame对象
<class 'pandas.core.frame.DataFrame'>
详细参阅pandas官方文档https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.iloc.html
df.iloc[[0, 1]] #以列表作参数,查询前两行.只要逗号与最外层方括号之间还隔有方括号,那就都只是行的事
a b c d
0 1 2 3 4
1 100 200 300 400df.iloc[[True, False, True]] #列表里以布尔型决定要显示第几行.本例第2行不显示
a b c d
0 1 2 3 4
2 1000 2000 3000 4000
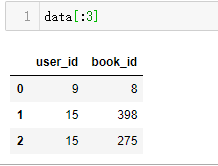
df.iloc[:3] #以切片slice作参数,查询前3行 注意:loc[:3]则会包括前4行,包括右界
a b c d
0 1 2 3 4
1 100 200 300 400
2 1000 2000 3000 4000df.iloc[[0, 2], [1, 3]] #逗号前面列表里显示第0行,第2位行即第3行,第1号,第3号列,即第2第4列
b d
0 2 4
2 2000 4000With slice objects.
>>> df.iloc[1:3, 0:3] #以切片标示两轴(左边从上到下的轴标示行号,上边从左至右标示列号)参数, a b c #本列行轴上1号到2号两行,列轴上0,1,2三列 1 100 200 3002 1000 2000 3000
2.根据行索引(有索引的时候可用)
print(data.loc['a']) #这里是3个字母loc(loc(对应的大写是LOC)
df.loc['viper'] #有索引的时候
max_speed 4
shield 5
Name: viper, dtype: int64List of labels. Note using [[]] returns a DataFrame.
>>> df.loc[['viper', 'sidewinder']]
max_speed shield
viper 4 5
sidewinder 7 8Slice with labels for row and single label for column. note that both the start and stop of the slice are included.
>>> df.loc['cobra':'viper', 'max_speed'] #注意:loc[]与python平常不同,此处切片,上下界都包括.
cobra 1 #而iloc[],则与此不同,和python一样也是不包括右界.
viper 4
Name: max_speed, dtype: int64注意loc与iloc在边界上的不同:
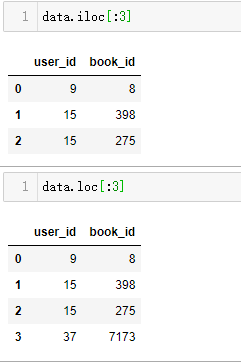

Single index tuple. Note this returns a Series.
>>> df.loc[('cobra', 'mark ii')] #单一元组( ),标示的双索引,对应获取那一行的两个数据0,4,Series格式
max_speed 0
shield 4
Name: (cobra, mark ii), dtype: int64Single tuple. Note using [[]] returns a DataFrame. #单一元组外面再套一个中括号[()],获取的数据为DataFrame格式
多包一层[ ],似乎就转变为DataFrame了.包装产生质变,比如明星包装:
>>> df.loc[[('cobra', 'mark ii')]]
max_speed shield
cobra mark ii 0 4
切片数据变化会影响原始数据,同Numpy数组一样.
slice_data=data['score'] #取score列的值 用data.score也是一样
slice_data[0]=70 #将第1个值赋为70
print(data)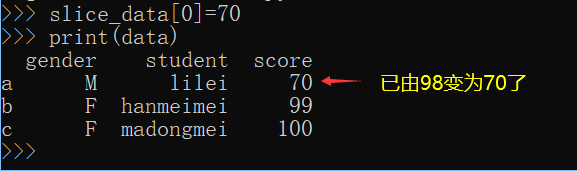
修改DataFrame整行数据:
Set value for an entire row
>>> df.loc['cobra'] = 10
>>> df
max_speed shield
cobra 10 10
viper 4 50
sidewinder 7 50修改DataFrame整列数据:
Set value for an entire column
>>> df.loc[:, 'max_speed'] = 30
>>> df
max_speed shield
cobra 30 10
viper 30 50
sidewinder 30 50
Set value for rows matching callable condition
>>> df.loc[df['shield'] > 35] = 0 #设置关于列的条件
>>> df
max_speed shield
cobra 30 10
viper 0 0
sidewinder 0 0
另一个例子,注意切片,包括起止边界:
Slice with integer labels for rows. As mentioned above, note that both the start and stop of the slice are included.>>> df.loc[7:9] #包括起止边界
max_speed shield
7 1 2
8 4 5
9 7 8上例中不用.loc也行,直接data[7:9]
df = pd.DataFrame([[1, 2], [4, 5], [7, 8]],
... index=[7, 8, 9], columns=['max_speed', 'shield'])
>>> df
max_speed shield
7 1 2
8 4 5
9 7 8DataFrame()内以方括号[],逗号组成的数据结构[[1, 2], [4, 5], [7, 8]],与
DataFrame()内以大括号{},冒号+逗号组成的数据结构不同,字典的关键字作为列名.
上例是三列三行,下例是2行3列:
df = pd.DataFrame({'col1': [1, 2], 'col2': [3, 4],
... 'col3': [5, 6]})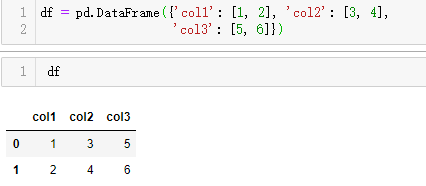
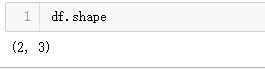
也不同于: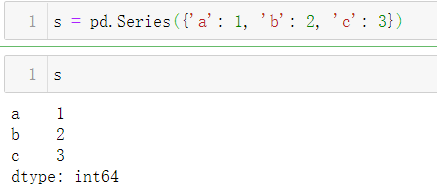

获取元素个数:pandas.DataFrame.size
Return an int representing the number of elements in this object.返回一个表示此对象中元素数量的int
Return the number of rows if Series. Otherwise return the number of rows times number of columns if DataFrame.
如果为Series,则返回行数。否则,如果是DataFrame,则返回行数乘以列数。
Examples
>>> s = pd.Series({'a': 1, 'b': 2, 'c': 3})
s
a 1
b 2
c 3
dtype: int64
>>> s.size
3
>>> df = pd.DataFrame({'col1': [1, 2], 'col2': [3, 4]})
>>> df.size
4
>>>df = pd.DataFrame({'col1': [1, 2], 'col2': [3, 4],'col3': [1, 2], 'col4': [3, 4]})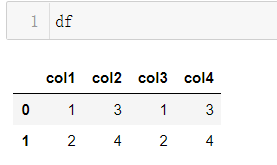
>>>df.size
8 #2X4=8
查看字段类型data.dtypes
df = pd.DataFrame({'age': [ 3, 29],
'height': [94, 170],
'weight': [31, 115]})
df
age height weight
0 3 94 31
1 29 170 115df.dtypes
age int64
height int64
weight int64
dtype: object显示前n行,默认5行pandas.DataFrame.head
DataFrame.head(self: ~FrameOrSeries, n: int = 5) → ~FrameOrSeries[source]
Return the first n rows.
This function returns the first n rows for the object based on position. It is useful for quickly testing if your object has the right type of data in it.
For negative values of n, this function returns all rows except the last n rows, equivalent to df[:-n].
如果参数为负值 ,则除了最后n行外的全部显示.
Examples
df = pd.DataFrame({'animal': ['alligator', 'bee', 'falcon', 'lion',
'monkey', 'parrot', 'shark', 'whale', 'zebra']})
df
animal
0 alligator
1 bee
2 falcon
3 lion
4 monkey
5 parrot
6 shark
7 whale
8 zebra
Viewing the first 5 lines
df.head()
animal
0 alligator
1 bee
2 falcon
3 lion
4 monkey
Viewing the first n lines (three in this case)
df.head(3)
animal
0 alligator
1 bee
2 falcon
For negative values of n
df.head(-3)
animal
0 alligator
1 bee
2 falcon
3 lion
4 monkey
5 parrot显示数据基本信息pandas.DataFrame.info
data.info(verbose=True)
This method prints information about a DataFrame including the index dtype and column dtypes, non-null values and memory usage.
Getting values with a MultiIndex
A number of examples using a DataFrame with a MultiIndex
>>> tuples = [
... ('cobra', 'mark i'), ('cobra', 'mark ii'),
... ('sidewinder', 'mark i'), ('sidewinder', 'mark ii'),
... ('viper', 'mark ii'), ('viper', 'mark iii')
... ]
>>> index = pd.MultiIndex.from_tuples(tuples)
>>> values = [[12, 2], [0, 4], [10, 20],
... [1, 4], [7, 1], [16, 36]]
>>> df = pd.DataFrame(values, columns=['max_speed', 'shield'], index=index)
>>> df
max_speed shield
cobra mark i 12 2
mark ii 0 4
sidewinder mark i 10 20
mark ii 1 4
viper mark ii 7 1
mark iii 16 36
修改DataFrame数据中的某一列数据
data['score']=95 #让该列的值都为95
data['score']=range(95,98) #让该列数据按95,96,97分别给三行的score
用Series类型数据修改DataFrame数据中的某一列数据
score=pd.Series([100,90,80]),index=['c','b','a']) #这是Series类型数据
data['score']=score #用Series型数据赋值给DataFrame型的data中score列
score数值会按索引自动匹配.最后输出的索引顺序是按DataFrame的索引序.
删除DataFrame数据中的某一列数据del
del data['score']
调整索引顺序重新排列数据的行位置reindex()
data=data.reindex(['c','a','b','d']) #多出来的索引会加上,并且自动补上其他列的值为NaNa或指定为0
data=data.reindex(['c','a','b','d', fill_value=0]) #将缺失补为0
data=data.reindex(['c','a','b','d'],method='ffill') #将缺失位置通过插值法计算并补上内容
ffill:从前面数据计算插值 #什么是插值法?
bfill:从后面数据计算插值
扔掉包含缺失的数据(NaN)的行 #该行中,有部分列无数据
print(data.dropna())
扔掉全部都是缺失的数据(NaN)的行
print(data.dropna(how='all'))
填充所有缺失数据为一个值,比如0
print(data.fillna(0))
填充缺失数据,按列填充合适的值(不一定相同)
print(data.fillna({'gender':'M','student':'unknown','score':60}))
删除某一行数据
data=data.drop('d')
筛选数据 #很常用
print(data[data['score']>=90]) #data['score']>=90是索引条件
从列表中筛选数据 #常用
print(data[data['socre'].isin(select_list)]) #求 data的score列的值,符合列表select_list条件的,
其中dict_data= {
'student': ['a','b', 'c','d','e','f'],
'score': [98,99,100,95,96,98] ,
'gender': [ 'M','F','F','F','M','M']
}
data = pd. DataFrame(dict_data)
select_list = [95,98, 100 ]
利用groupby对数据进行分组并计算sum,mean,count等 #常用
import pandas as pd
data=pd.DataFrame({
'tag_id':['a','b','c','a','a','c'],
'count':[10,30,20,10,15,22]
})
grouped_data=data.groupby('tag_id')
print(grouped_data.sum())
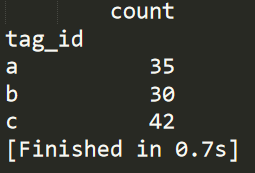
注意:grouped_data不是一个DataFrame数据结构,但可以用grouped_data.sum #或mean
数据排序--按索引名称升序排列
print(data.sort_index())
数据排序--按索引名称降序排列
print(data.sort_index(ascending=False))
数据排序--按某一列的数据进行排序
print(data.sort_values(by='socre')) #默认是升序
print(data.sort_values(by='socre',ascending=False)) #降序
数据汇总
print(data.sum()) #各列求和,数字相加,字符相连
Pandas一些常用的方法
获取维度数pandas.DataFrame.ndim
Examples
>>> s = pd.Series({'a': 1, 'b': 2, 'c': 3})
>>> s.ndim
1
>>> df = pd.DataFrame({'col1': [1, 2], 'col2': [3, 4]})
>>> df.ndim
2获取行,列数pandas.DataFrame.shape
(上一节数据分析(三)Pandas数据结构基础1.Series:https://blog.csdn.net/ahmcwt/article/details/104621782
下一节 数据分析(三)Pandas数据结构基础3.Pandas的层次化索引,数据合并,文件存取excel文件:https://blog.csdn.net/ahmcwt/article/details/104646246)















 757
757











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









