







解Bug之路-记一次中间件导致的慢SQL排查过程
前言
最近发现线上出现一个奇葩的问题,这问题让笔者定位了好长时间,期间排查问题的过程还是挺有意思的,就以此为素材写出了本篇文章。
Bug现场
我们的分库分表中间件在经过一年的沉淀之后,已经到了比较稳定的阶段。而且经过线上压测的检验,单台每秒能够执行1.7W条sql。但线上情况还是有出乎我们意料的情况。有一个业务线反映,每天有几条sql有长达十几秒的超时。而且sql是主键更新或主键查询,更奇怪的是出现超时的是不同的sql,似乎毫无规律可寻,如下图所示: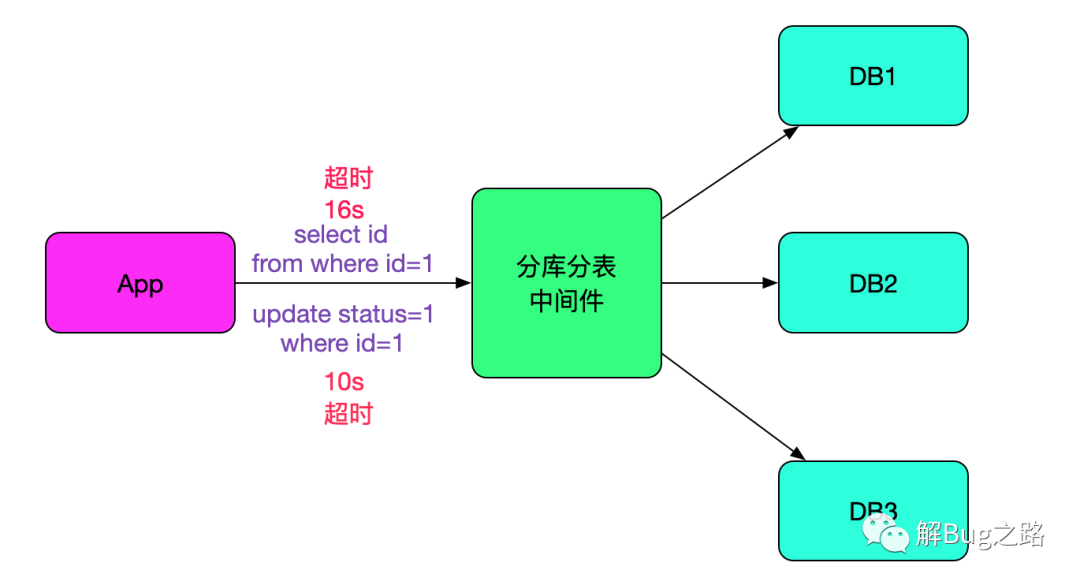
一个值得注意的点,就是此业务只有一部分流量走我们的中间件,另一部分还是直接走数据库的,而超时的sql只会在连中间件的时候出现,如下图所示: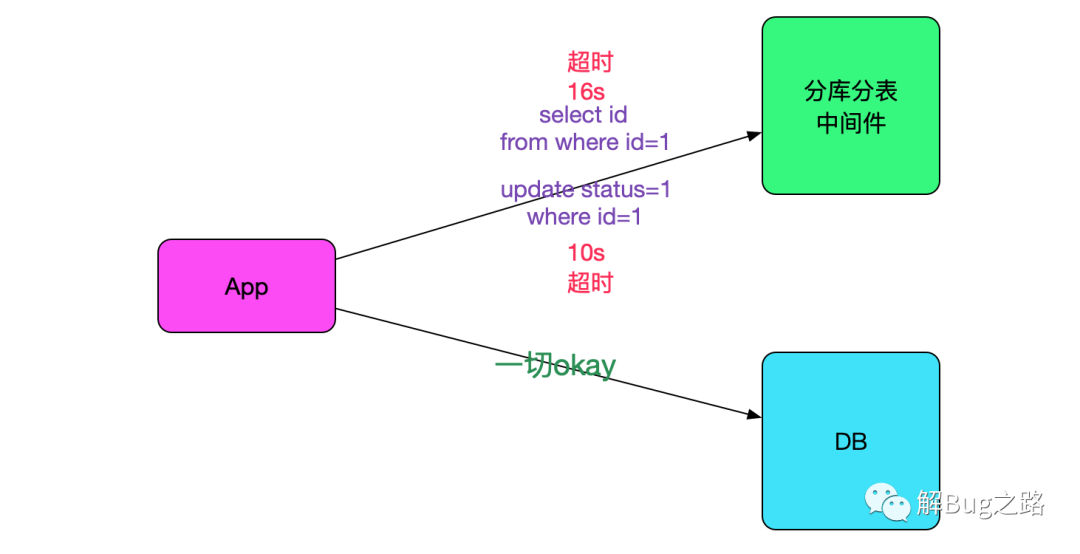
很明显,是引入了中间件之后导致的问题。
排查是否sql确实慢
由于数据库中间件只关心sql,并没有记录对应应用的traceId,所以很难将对应的请求和sql对应起来。在这里,我们先粗略的统计了在应用端超时的sql的类型是否会有超时的情况。
分析了日志,发现那段时间所有的sql在往后端数据执行的时候都只有0.5ms,非常的快。如下图所示: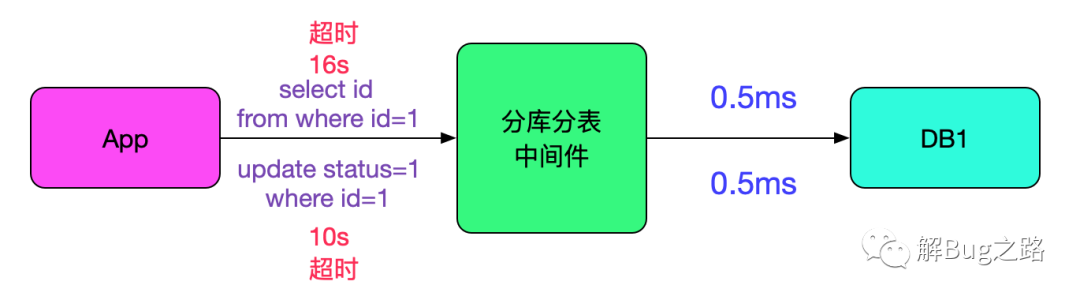
看来是中间件和数据库之间的交互是正常的,那么继续排查线索。
寻找超时规律
由于比较难绑定对应请求和中间件执行sql之间的关系,于是笔者就想着列出所有的异常情况,看看其时间点是否有规律,以排查一些批处理导致中间件性能下降的现象。下面是某几条超时sql业务方给出的信息:
| 业务开始时间 | 执行sql的应用ip | 业务执行耗时(s) |
|---|---|---|
| 2018-12-24 09:45:24 | xx.xx.xx.247 | 11.75 |
| 2018-12-24 12:06:10 | xx.xx.xx.240 | 10.77 |
| 2018-12-24 12:07:19 | xx.xx.xx.138 | 13.71 |
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 956
956











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









