






练习地址:
sql实战_在线编程_牛客网www.nowcoder.com
其实这些题很早之前就刷过了,但是时间很久了。最近在复习sql,所以挑选部分题目又重新做了一遍(增删改不涉及),并记录下来。
1.建表
CREATE TABLE `employees` (
`emp_no` int(11) NOT NULL,
`birth_date` date NOT NULL,
`first_name` varchar(14) NOT NULL,
`last_name` varchar(16) NOT NULL,
`gender` char(1) NOT NULL,
`hire_date` date NOT NULL,
PRIMARY KEY (`emp_no`));
CREATE TABLE `salaries` (
`emp_no` int(11) NOT NULL, -- '员工编号',
`salary` int(11) NOT NULL,
`from_date` date NOT NULL,
`to_date` date NOT NULL,
PRIMARY KEY (`emp_no`,`from_date`));
CREATE TABLE `dept_manager` (
`dept_no` char(4) NOT NULL, -- '部门编号'
`emp_no` int(11) NOT NULL, -- '员工编号'
`to_date` date NOT NULL,
PRIMARY KEY (`emp_no`,`dept_no`));
CREATE TABLE `dept_emp` (
`emp_no` int(11) NOT NULL, -- '所有的员工编号'
`dept_no` char(4) NOT NULL, -- '部门编号'
`from_date` date NOT NULL,
`to_date` date NOT NULL,
PRIMARY KEY (`emp_no`,`dept_no`));
CREATE TABLE IF NOT EXISTS "titles" (
`emp_no` int(11) NOT NULL,
`title` varchar(50) NOT NULL,
`from_date` date NOT NULL,
`to_date` date DEFAULT NULL);
CREATE TABLE film_category (
film_id smallint(5) NOT NULL,
category_id tinyint(3) NOT NULL, `last_update` timestamp);
CREATE TABLE IF NOT EXISTS film (
film_id smallint(5) NOT NULL DEFAULT '0',
title varchar(255) NOT NULL,
description text,
PRIMARY KEY (film_id));
CREATE TABLE category (
category_id tinyint(3) NOT NULL ,
name varchar(25) NOT NULL, `last_update` timestamp,
PRIMARY KEY ( category_id ));
emp_no int(11) NOT NULL,
received datetime NOT NULL,
btype smallint(5) NOT NULL);2.题库
- 查找最晚入职员工的所有信息
select * from employees
where hire_date = (SELECT max(hire_date) FROM employees);2. 查找入职员工时间排名倒数第三的员工所有信息
# method 1 用disticnt
select * from employees
where hire_date =
(select distinct hire_date from employees order by hire_date desc limit 2,1);
# method 2 用group by (比distinct快)
select * from employees where hire_date =
(select hire_date from employees group by hire_date order by hire_date desc limit 2,1)
# method 3 自连接
select * from employees e1
where (
select count(*) from employees e2
where e1.hire_date < e2.hire_date
)=2;3. 查找各个部门当前(dept_manager.to_date='9999-01-01')领导当前(salaries.to_date='9999-01-01')薪水详情以及其对应部门编号dept_no;(注:请以salaries表为主表进行查询,输出结果以salaries.emp_no升序排序,并且请注意输出结果里面dept_no列是最后一列)
# 两个表格都要限制时间(9999-01-01),因为领导会离职
select s.*,d.dept_no from salaries s
inner join dept_manager d on s.emp_no=d.emp_no
where s.to_date='9999-01-01' and d.to_date='9999-01-01'
order by s.emp_no;4. 查找所有已经分配部门的员工的last_name和first_name
SELECT e.last_name,e.first_name,d.dept_no from employees e
inner JOIN dept_emp d on e.emp_no=d.emp_no;5. 查找所有员工的last_name和first_name以及对应部门编号dept_no
SELECT e.last_name,e.first_name,d.dept_no from employees e
left JOIN dept_emp d on e.emp_no=d.emp_no;6. 查找所有员工入职时候的薪水情况
SELECT e.emp_no,s.salary from employees e
join salaries s on e.emp_no=s.emp_no
where e.hire_date=s.from_date
ORDER BY e.emp_no desc;7. 查找薪水涨幅超过15次的员工号emp_no以及其对应的涨幅次数t
# method 1 这样查询到的是薪水变化超过15次的员工号,并非涨幅
SELECT emp_no,count(emp_no) t from salaries
GROUP BY emp_no
HAVING t>15;
# method 2 该答案来自牛客网讨论区,个人认为更合理
select a.emp_no,count(*) t from salaries a
inner join salaries b on a.emp_no=b.emp_no and a.to_date = b.from_date
where a.salary < b.salary
group by a.emp_no
having t>15;8. 找出所有员工当前(to_date='9999-01-01')具体的薪水salary情况,对于相同的薪水只显示一次,并按照逆序显示
# method 1
SELECT DISTINCT salary from salaries
where to_date='9999-01-01'
ORDER BY salary desc;
#method 2
SELECT salary FROM salaries
WHERE to_date='9999-01-01'
GROUP BY salary
ORDER BY salary DESC;9. 获取所有部门当前manager的当前薪水情况,给出dept_no, emp_no以及salary(请注意,同一个人可能有多条薪水情况记录)
SELECT d.dept_no, d.emp_no,s.salary from dept_manager d
join salaries s on d.emp_no=s.emp_no
where s.to_date='9999-01-01' AND d.to_date = '9999-01-01';10. 获取所有非manager的员工emp_no
# method 1
SELECT e.emp_no from employees e
where e.emp_no not IN(
SELECT emp_no from dept_manager
);
# method 2
SELECT e.emp_no FROM employees e
LEFT JOIN dept_manager d ON e.emp_no = d.emp_no
WHERE d.dept_no IS NULL;11. 获取所有员工当前的manager,如果员工是manager的话不显示(也就是如果当前的manager是自己的话结果不显示)。输出结果第一列给出当前员工的emp_no,第二列给出其manager对应的emp_no。
select de.emp_no,dm.emp_no manager_no from dept_emp de
left join dept_manager dm on de.dept_no=dm.dept_no
where de.emp_no!=dm.emp_no
and de.to_date='9999-01-01'
and dm.to_date='9999-01-01';12. 获取所有部门中当前(dept_emp.to_date = '9999-01-01')员工当前(salaries.to_date='9999-01-01')薪水最高的相关信息,给出dept_no, emp_no以及其对应的salary,按照部门升序排列。
# 先得到关于部门和该部门最高工资的表r,再将r与另外两张表连接;最后当员工的工资正好等于部门最大工资时选择。
select r.dept_no,ss.emp_no,r.maxSalary
from (
select d.dept_no,max(s.salary)as maxSalary from dept_emp d,salaries s
where d.emp_no=s.emp_no
and d.to_date='9999-01-01' and s.to_date='9999-01-01'
group by d.dept_no
)as r,salaries ss,dept_emp dd
where r.maxSalary=ss.salary
and r.dept_no=dd.dept_no
and dd.emp_no=ss.emp_no
and ss.to_date='9999-01-01' and dd.to_date='9999-01-01'
order by r.dept_no;13. 从titles表获取按照title进行分组,每组个数大于等于2,给出title以及对应的数目t。
select title,count(title) t from titles
group by title
having t>=2;14. 从titles表获取按照title进行分组,每组个数大于等于2,给出title以及对应的数目t。注意对于重复的emp_no进行忽略(即emp_no重复的title不计算,title对应的数目t不增加)。
select title,count(distinct emp_no) t from titles
group by title
having t>=2;15. 查找employees表所有emp_no为奇数,且last_name不为Mary(注意大小写)的员工信息,并按照hire_date逆序排列(题目不能使用mod函数)
# method 1 取余
select * from employees
where emp_no%2=1 and last_name!='Mary'
order by hire_date desc;
# method 2 位运算
select * from employees
where emp_no&1=1 and last_name!='Mary'
order by hire_date desc;16. 统计出当前各个title类型对应的员工当前薪水对应的平均工资。结果给出title以及平均工资avg。
select t.title,avg(s.salary) avg from titles t
inner join salaries s on t.emp_no=s.emp_no
where t.to_date='9999-01-01' and s.to_date='9999-01-01'
group by t.title;17. 获取当前薪水第二多的员工的emp_no以及其对应的薪水salary
# method 1 返回指定的记录数
select emp_no, salary from salaries
where salary=(
select salary from salaries
group by salary
order by salary desc
limit 1,1
)
and to_date = '9999-01-01';
# method 2 在除去最高工资的数据集中查询最高的工资
select emp_no,max(salary) from salaries
where salary not in (select max(salary) from salaries)
and to_date='9999-01-01';18. 查找当前薪水排名第二多的员工编号emp_no、薪水salary、last_name以及first_name,(不使用order by)
# method 1
select e.emp_no,max(s.salary) salary,e.last_name,e.first_name from employees e
inner join salaries s on e.emp_no=s.emp_no
where s.to_date='9999-01-01' and s.salary not in(
select max(salary) from salaries
);
# method 2
select e.emp_no,s3.salary,e.last_name,e.first_name from employees e
inner join(
select s1.emp_no,s1.salary from salaries s1
inner join salaries s2 on s1.salary < s2.salary
where s1.to_date = '9999-01-01' and s2.to_date = '9999-01-01'
group by s1.emp_no
having count(*)=1
) s3
on e.emp_no = s3.emp_no;19. 查找所有员工的last_name和first_name以及对应的dept_name,也包括暂时没有分配部门的员工
select e.last_name,e.first_name,d.dept_name from employees e
left join dept_emp de on e.emp_no=de.emp_no
left join departments d on de.dept_no=d.dept_no;20. 查找员工编号emp_no为10001其自入职以来的薪水salary涨幅(总共涨了多少)growth(可能有多次涨薪,没有降薪)
SELECT (
(SELECT salary FROM salaries WHERE emp_no = 10001 ORDER BY to_date DESC LIMIT 1) -
(SELECT salary FROM salaries WHERE emp_no = 10001 ORDER BY to_date ASC LIMIT 1)
) AS growth21. 查找所有员工自入职以来的薪水涨幅情况,给出员工编号emp_no以及其对应的薪水涨幅growth,并按照growth进行升序(注:可能有employees表和salaries表里存在记录的员工,有对应的员工编号和涨薪记录,但是已经离职了,离职的员工salaries表的最新的to_date!='9999-01-01',这样的数据不显示在查找结果里面)
select e.emp_no,(a.salary-b.salary) as growth from employees e
inner join salaries a on e.emp_no=a.emp_no and a.to_date='9999-01-01'
inner join salaries b on e.emp_no=b.emp_no and b.from_date=e.hire_date
order by growth asc;22. 统计各个部门的工资记录数,给出部门编码dept_no、部门名称dept_name以及部门在salaries表里面有多少条记录sum
select de.dept_no,d.dept_name,count(s.salary) sum from salaries s
inner join dept_emp de on s.emp_no=de.emp_no
inner join departments d on de.dept_no=d.dept_no
group by de.dept_no;23. 对所有员工的当前薪水按照salary进行按照1-N的排名,相同salary并列且按照emp_no升序排列
# method 1 hive窗口函数
select emp_no,salary,dense_rank over(order by salary desc) rank
from salaries
where to_date='9999-01-01';
# method 2
select a.emp_no,a.salary,count(distinct b.salary) rank
from salaries a,salaries b
where a.to_date='9999-01-01' and b.to_date='9999-01-01'
and a.salary<=b.salary
group by a.emp_no
order by a.salary desc,a.emp_no;24. 获取所有非manager员工当前的薪水情况,给出dept_no、emp_no以及salary
select de.dept_no,s.emp_no,s.salary
from dept_emp de,salaries s
where de.emp_no=s.emp_no
and de.to_date='9999-01-01'and s.to_date='9999-01-01'
and de.emp_no not in (
select emp_no from dept_manager
);25. 获取员工其当前的薪水比其manager当前薪水还高的相关信息,第一列给出员工的emp_no,第二列给出其manager的manager_no,第三列给出该员工当前的薪水emp_salary,第四列给该员工对应的manager当前的薪水manager_salary
select
s1.emp_no,
dm.emp_no manager_no,
s1.salary emp_salary,
s2.salary manager_salary
from salaries s1,dept_emp de,dept_manager dm,salaries s2
where s1.emp_no=de.emp_no
and de.dept_no=dm.dept_no
and dm.emp_no=s2.emp_no
and s1.to_date='9999-01-01'
and s2.to_date='9999-01-01'
and de.to_date='9999-01-01'
and dm.to_date='9999-01-01'
and s1.salary>s2.salary;26. 汇总各个部门当前员工的title类型的分配数目,即结果给出部门编号dept_no、dept_name、其部门下所有的当前员工的当前title以及该类型title对应的数目count
select d.dept_no,d.dept_name,t.title,count(t.emp_no) from departments d
inner join dept_emp de on d.dept_no=de.dept_no
inner join titles t on de.emp_no=t.emp_no
where de.to_date='9999-01-01' and t.to_date='9999-01-01'
group by de.dept_no,t.title;27. 查找描述信息(film.description)中包含robot的电影对应的分类名称(category.name)以及电影数目(count(film.film_id)),而且还需要该分类包含电影总数量(count(film_category.category_id))>=5部
# 这道题要聚合前后聚合后分别统计,比较绕,以上三种解法来自牛客网讨论区,我认为是比较容易理解的。
# method 1
select c.name,sum(description like '%robot%') '电影数目' from film a
join film_category b on a.film_id=b.film_id
join category c on c.category_id=b.category_id
group by c.category_id
having count(*)>=5 and 电影数目>0;
# method 2
select c.name, count(f.film_id) from film f
join film_category fc on fc.film_id = f.film_id
join category c on c.category_id = fc.category_id
where exists
(select category_id from film_category
where category_id = fc.category_id
group by category_id
having count(category_id) >= 5
)
and f.description like '%robot%';
# method 3
SELECT b.name, COUNT(c.film_id)
FROM film a,category b,film_category c
WHERE a.description LIKE '%robot%'
AND a.film_id = c.film_id
AND b.category_id = c.category_id
and b.category_id in(
select category_id FROM film_category
GROUP BY category_id
HAVING count(film_id)>=5
)
group by b.category_id;28. 使用join查询方式找出没有分类的电影id以及名称
select f.film_id,f.title from film f
left join film_category fc on f.film_id=fc.film_id
where fc.category_id isnull;29. 使用子查询的方式找出属于Action分类的所有电影对应的title,description
select * from (select f.title,f.description from film f
inner join film_category fc on f.film_id=fc.film_id
inner join category c on fc.category_id=c.category_id
where c.name='Action');30. 将employees表的所有员工的last_name和first_name拼接起来作为Name,中间以一个空格区分
select CONCAT(last_name," ",first_name) as name from employees;31. 查找字符串'10,A,B' 中逗号','出现的次数cnt。
select (length("10,A,B") - length(replace("10,A,B", ",", ""))) cnt;32. 获取Employees中的first_name,查询按照first_name最后两个字母,按照升序进行排列
select first_name from employees
order by substr(first_name,length(first_name)-1,2);33. 按照dept_no进行汇总,属于同一个部门的emp_no按照逗号进行连接,结果给出dept_no以及连接出的结果employees
select dept_no,group_concat(emp_no) from dept_emp
group by dept_no;34. 查找排除最大、最小salary之后的当前员工的平均工资avg_salary。
select avg(salary) avg_salary from salaries
where salary not in (
select max(salary) from salaries
where to_date = '9999-01-01'
)
and salary not in (
select min(salary) from salaries
where to_date = '9999-01-01'
)
and to_date = '9999-01-01';35. 分页查询employees表,每5行一页,返回第2页的数据
select * from employees limit 5,5;36. 获取所有员工的emp_no、部门编号dept_no以及对应的bonus类型btype和received,没有分配奖金的员工不显示对应的bonus类型btype和received
select d.emp_no,d.dept_no,e.btype,e.received from dept_emp d
left join emp_bonus e on d.emp_no=e.emp_no;37. 使用含有关键字exists查找未分配具体部门的员工的所有信息。
select * from employees
where not exists(
select emp_no from dept_emp
where employees.emp_no=dept_emp.emp_no);38. 给出emp_no、first_name、last_name、奖金类型btype、对应的当前薪水情况salary以及奖金金额bonus。 bonus类型btype为1其奖金为薪水salary的10%,btype为2其奖金为薪水的20%,其他类型均为薪水的30%。
select e.emp_no,e.first_name,e.last_name,eb.btype,s.salary,
sum(case eb.btype
when 1 then s.salary*0.1
when 2 then s.salary*0.2
else s.salary*0.3
end) bonus
from employees e
inner join emp_bonus eb on e.emp_no=eb.emp_no
inner join salaries s on e.emp_no=s.emp_no
where s.to_date='9999-01-01'
group by e.emp_no;39. 按照salary的累计和running_total,其中running_total为前N个当前员工的salary累计和
# method 1
select a.emp_no, a.salary, sum(b.salary)
from salaries a, salaries b
where b.emp_no <= a.emp_no
and a.to_date = '9999-01-01'
and b.to_date = '9999-01-01'
group by a.emp_no
order by a.emp_no;
# method 2
select emp_no,salary,
sum(salary) over(order by emp_no) running_total
from salaries
where to_date= '9999-01-01';40. 对于employees表中,输出first_name排名(按first_name升序排序)为奇数的first_name
select a.first_name from employees a
where (
select count(b.first_name) from employees b
where a.first_name>=b.first_name)%2=1;41. 查询积分表里面出现三次及以上的积分
select number from grade
group by number
having count(number)>=3;42. 在牛客刷题有一个通过题目个数的(passing_number)表,id是主键,简化如下:
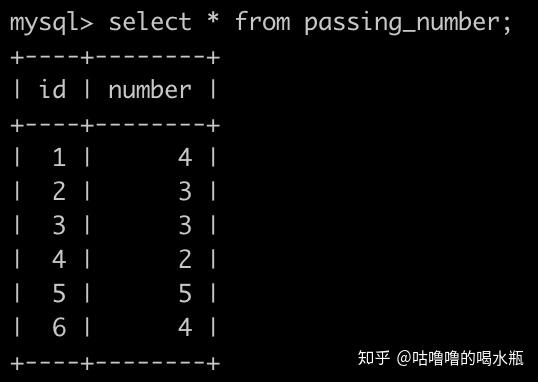
第1行表示id为1的用户通过了4个题目;第6行表示id为6的用户通过了4个题目;
请你根据上表,输出通过的题目的排名,通过题目个数相同的,排名相同,此时按照id升序排列,数据如下:

select id,number,dense_rank() over(order by number desc) rank
from passing_number
order by rank,id;43. 有一个person表,主键是id,如下:
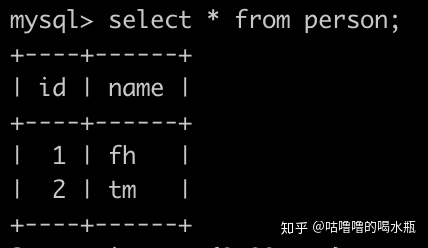
有一个任务(task)表如下,主键也是id,如下:
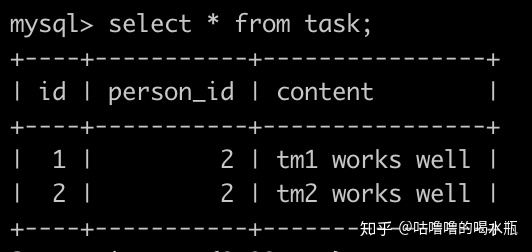
请你找到每个人的任务情况,并且输出出来,没有任务的也要输出,而且输出结果按照person的id升序排序,输出情况如下:

select p.id,p.name,t.content from person p
left join task t on p.id=t.person_id
order by p.id;44. 现在有一个需求,让你统计正常用户发送给正常用户邮件失败的概率:
有一个邮件(email)表,id为主键, type是枚举类型,枚举成员为(completed,no_completed),completed代表邮件发送是成功的,no_completed代表邮件是发送失败的。简况如下:
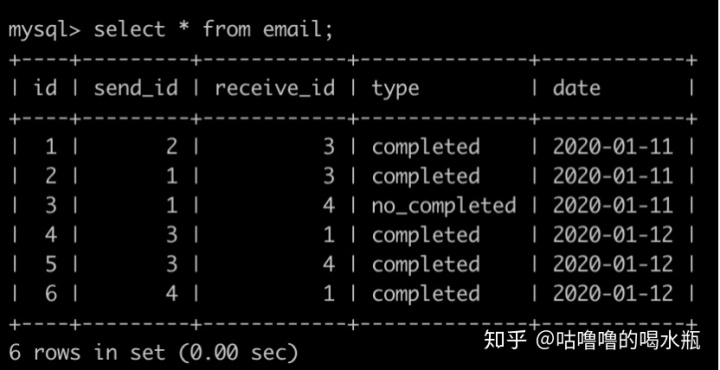
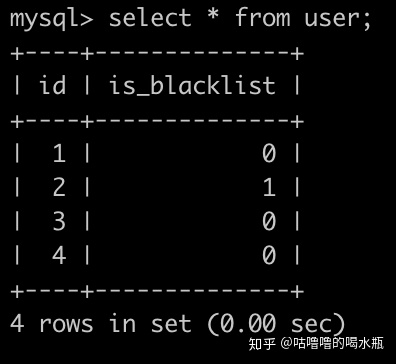
下面是一个用户(user)表,id为主键,is_blacklist为0代表为正常用户,is_blacklist为1代表为黑名单用户,简况如下:
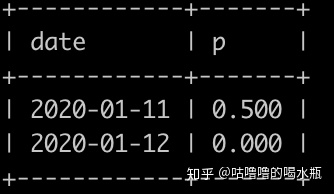
写一个sql查询,每一个日期里面,正常用户发送给正常用户邮件失败的概率是多少,结果保留到小数点后面3位(3位之后的四舍五入),并且按照日期升序排序,上面例子查询结果如下:
select e.date,
round(sum(case e.type when 'no_completed' then 1 else 0 end)/count(e.type),3) p
from email e
inner join user u1 on e.send_id=u1.id
inner join user u2 on e.receive_id=u2.id
where u1.is_blacklist=0 and u2.is_blacklist=0
group by e.date
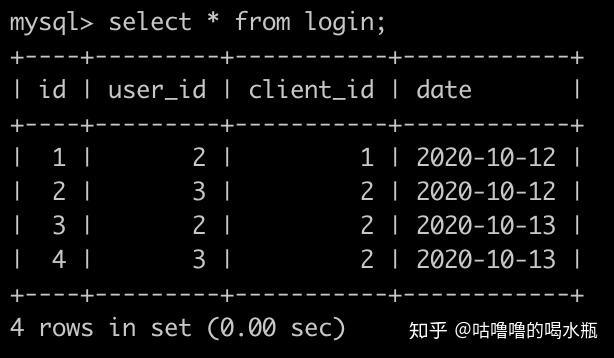
order by e.date;45. 牛客每天有很多人登录,请你统计一下牛客每个用户最近登录是哪一天,并且按照user_id升序排序。登录(login)记录表简况如下:
select max(date) from login
group by user_id
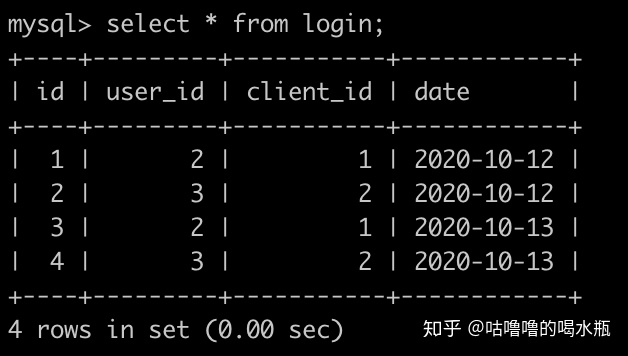
order by user_id;46. 查询每个用户最近一天登录的日子,用户的名字,以及用户用的设备的名字,并且查询结果按照user的name升序排序
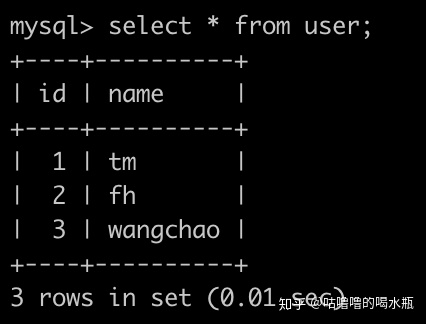
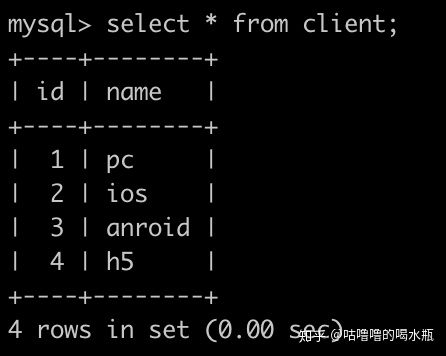
select u.name u_n,c.name c_n,max(l.date) d from login l
inner join user u on l.user_id=u.id
inner join client c on l.client_id=c.id
group by l.user_id
order by u.name;47. 查询新登录用户次日成功的留存率(sqlite里查找某一天的后一天的用法是:date(yyyy-mm-dd, '+1 day'))
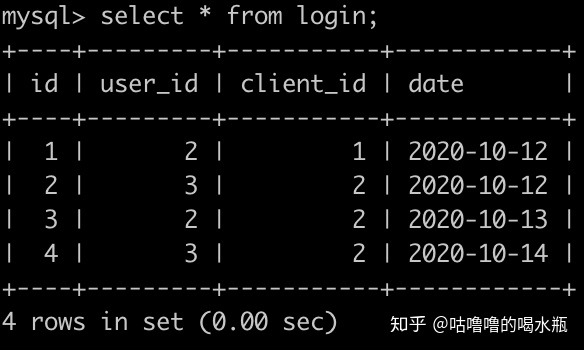
select round(count(distinct user_id)*1.0/(select count(distinct user_id) from login) ,3)
from login
where (user_id,date) in (
select user_id,date(min(date),'+1 day') from login
group by user_id
);48. 查询每个日期登录新用户个数,并且查询结果按照日期升序排序
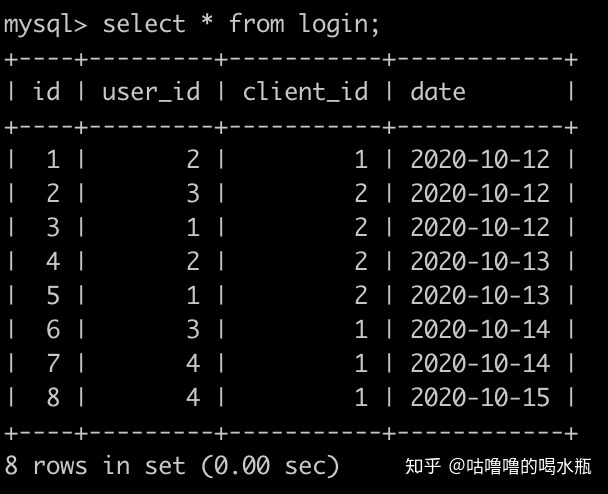
# method 1
select a.date,sum(case when rank=1 then 1 else 0 end) new
from (
select date, row_number() over(partition by user_id order by date) rank from login
) a
group by date;
# method 2
select date,
sum(case when (user_id,date) in (select user_id,min(date) from login group by user_id)
then 1 else 0 end)
from login
group by date
order by date;49. 查询每个日期新用户的次日留存率,结果保留小数点后面3位数(3位之后的四舍五入),并且查询结果按照日期升序排序
#答案来自牛客网讨论区
SELECT a.date, ROUND(COUNT(b.user_id) * 1.0/COUNT(a.user_id), 3) AS p
FROM (
SELECT user_id, MIN(date) AS date
FROM login
GROUP BY user_id) a
LEFT JOIN login b
ON a.user_id = b.user_id
AND b.date = date(a.date, '+1 day')
GROUP BY a.date
UNION
SELECT date, 0.000 AS p
FROM login
WHERE date NOT IN (
SELECT MIN(date)
FROM login
GROUP BY user_id)
ORDER BY date;50. 查询各个岗位分数的平均数,并且按照分数降序排序,结果保留小数点后面3位(3位之后四舍五入):
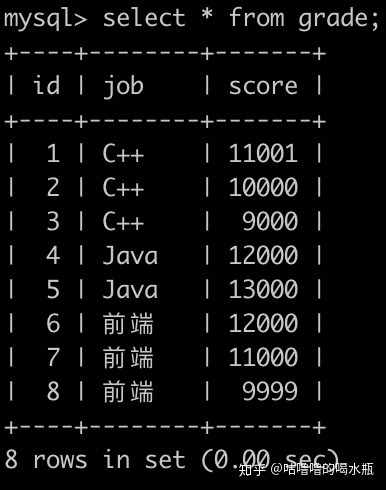
select job,round(avg(score),3) from grade
group by job
order by score desc;51. 查询用户分数大于其所在工作分数的平均分的所有grade的属性,并且以id的升序排序
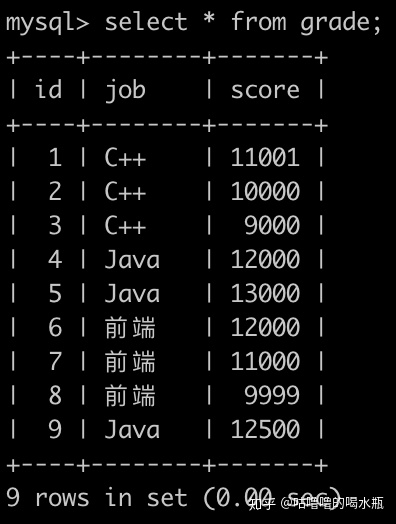
select g1.id,g1.job,g1.score from grade g1
left join (
select job,avg(score) avg from grade group by job) g2
on g1.job=g2.job
where g1.score>g2.avg
order by g1.id;52. 找出每个岗位分数排名前2的用户,得到的结果先按照language的name升序排序,再按照积分降序排序,最后按照grade的id升序排序
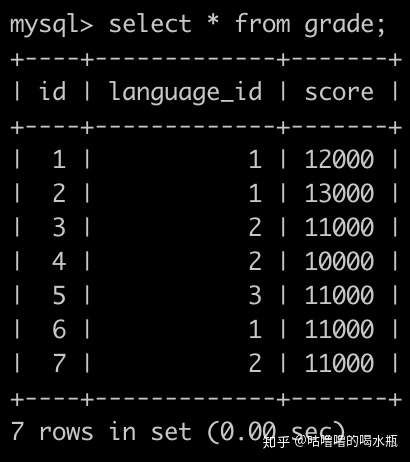
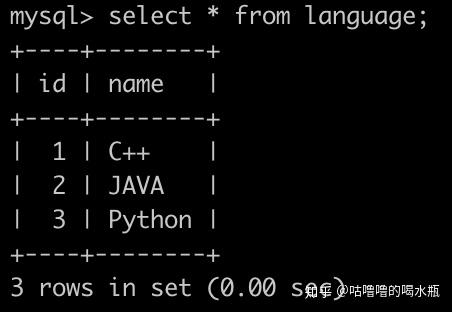
select g.id, l.name, g.score
from (select *,
dense_rank() over(partition by language_id order by score desc) rank
from grade) g,
language l
where g.language_id = l.id and g.rank <= 2
order by l.name asc, g.score desc, g.id asc;53. 查询各个岗位分数升序排列之后的中位数位置的范围,并且按job升序排序
select job,
case when num%2=0 then num/2 else (num+1)/2 end 'start',
case when num%2=0 then num/2+1 else (num+1)/2 end 'end'
from (
select job,count(job) num from grade
group by job)t;54. 查询各个岗位分数的中位数位置上的所有grade信息,并且按id升序排序
# 答案来自牛客网讨论区
select id,job,score,rn rank
from
(select *,
row_number()over(partition by job order by score desc) rn,
count(id)over(partition by job) num
from grade)
where abs(rn-(num+1)*1.0/2)<1
order by id;














 597
597











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









