





 提示:点击上方"我们的开心"↑关注我们
提示:点击上方"我们的开心"↑关注我们

文/张译权 汤浩 梁奇
网络爬虫是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。它为搜索引擎从万维网上下载网页,是搜索引擎的重要组成部分,爬虫软件首要的功能就是爬取网页数据。
 Scrapy
Scrapy
官方文档:
https://scrapy-chs.readthedocs.io/zh_CN/latest/intro/tutorial.html#intro-tutorial
Scrapy 是用 Python 实现的一个为了爬取网站数据、提取结构性数据而编写的应用框架。Scrapy 经常应用在包括数据挖掘、信息处理或历史数据存储等一系列的程序中。通常我们可以很简单地通过 Scrapy 框架实现一个爬虫,抓取指定网站的内容或图片。
Scrapy架构
Scrapy Engine(引擎):负责Spider、ItemPipeline、Downloader、Scheduler之间的通讯,包括信号、数据传递等。
Scheduler(调度器):负责接收引擎发送过来的Requests请求,并按照一定的方式进行整理排列、入队,当引擎需要时,交还给引擎。
Downloader(下载器):负责下载引擎发送的所有Requests请求,并将其获取到的Responses交还给引擎,由引擎交给Spider来处理。
Spider(爬虫):它负责处理所有Responses,从中分析提取数据,获取Item字段需要的数据,并将需要跟进的URL提交给引擎,再次进入Scheduler(调度器)。
Item Pipeline(管道):它负责处理Spider中获取到的Item,并进行后期处理(详细分析、过滤、存储等)。
Downloader Middlewares(下载中间件):是一个可以自定义扩展下载功能的组件。
Spider Middlewares(Spider中间件):是一个可以自定义扩展操作引擎和Spider中间通信的功能组件(比如进入Spider的Responses和从Spider出去的Requests)。
scrapy项目目录结构
一个爬虫项目的代码目录结构如下图。
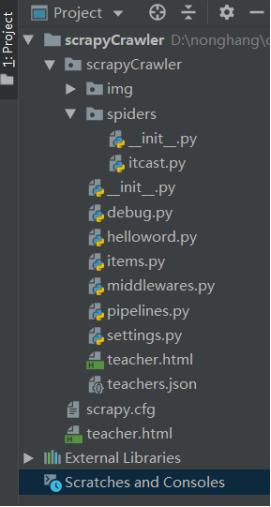
主要文件的作用是:
scrapy.cfg: 项目的配置文件。
scrapyCrawler: 项目的Python模块,将会从这里引用代码。
scrapyCrawler/items.py: 项目的目标文件。一般用于定义爬取数据的结构。
scrapyCrawler/pipelines.py: 项目的管道文件。一般用于处理爬取数据的存储。
scrapyCrawler/settings.py: 项目的设置文件。可以设置pipelines和middlewares的优先级、遵守的协议等等。
scrapyCrawler/middlewares.py:项目的中间件文件。可以在爬虫请求网页时进行额外操作,可以处理下载请求部分(下载器中间件(Downloader middlewares)),也可以处理解析部分(Spider中间件(Spider middlewares))。
scrapyCrawler/spiders/: 存储爬虫代码目录。
scrapyCrawler/spiders/itcast.py:项目的爬虫代码文件。用于解析网页并根据设定的规则获取数据。
scrapy爬取基本流程
爬取一次数据的基本流程:
1.向指定网页发起request请求
2.下载中间件中的扩展功能(如果有的话)
3.下载得到网页的html文档例如:
DOM TutorialDOM Lesson one
Hello world!
4.根据xpath或者正则表达式寻找需要爬取数据的位置。
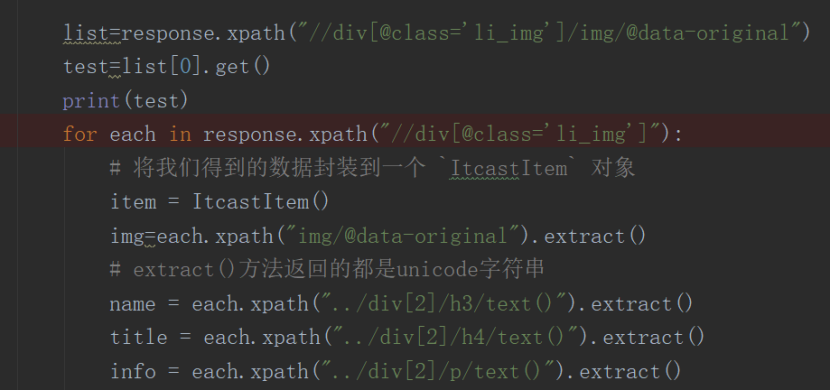
5.获取到数据后进行数据存储。
能够完成上述爬取流程的就是一个最基本的爬虫程序了,我们可以使用它来爬取一些简单的网页。但是马上我们就会发现,有一些网页的内容是无法爬取的。无法爬取的原因有很多种,但是最常见的原因是网站html文档的大部分内容由js动态加载生成。爬虫直接爬取只能得到静态页面,无法得到动态加载的部分。
解决此问题的两种方法:
1.分析网页的js加载方法,构造ajax请求获取动态加载的内容。
2.使用selenium控制浏览器进行访问,通过浏览器自行加载网页内容,这样能够爬取到动态加载的内容。
第一种比较麻烦,一般推荐使用第二种方法让浏览器自动加载页面,也就是Scrapy和Selenium结合使用。
Selenium
Selenium 是一个用于Web应用程序测试的工具。Selenium测试直接运行在浏览器中,就像真正的用户在操作一样。支持的浏览器包括IE(7, 8, 9, 10, 11)、Mozilla Firefox、Safari、Google Chrome、Opera等。Selenium 是一套完整的web应用程序测试系统,包含了测试的录制(Selenium IDE),编写及运行(Selenium Remote Control),以及测试的并行处理(Selenium Grid)。
Selenium的核心Selenium Core基于JsUnit,完全由JavaScript编写,因此可以用于任何支持JavaScript的浏览器上。
Selenium可以模拟真实浏览器,是一种自动化测试工具,支持多种浏览器,爬虫中主要用来解决JavaScript渲染问题。
在Scrapy中使用Selenium
Selenium支持Chrome、Firefox等浏览器。能够操作浏览器进行访问网页、点击标签、拖动滑块等操作。使用Selenium,需要安装使用的浏览器与对应浏览器版本的浏览器驱动。Scrapy结合Selenium进行抓取,采用Downloader Middleware来实现,在Middleware中的process_request()方法里面对每个抓取请求进行额外处理,启动浏览器并进行页面渲染,再将渲染后的结果构造一个HtmlResponse返回即可。
部分代码如下:
在middlewares.py中新建一个中间件SeleniumMiddleware:
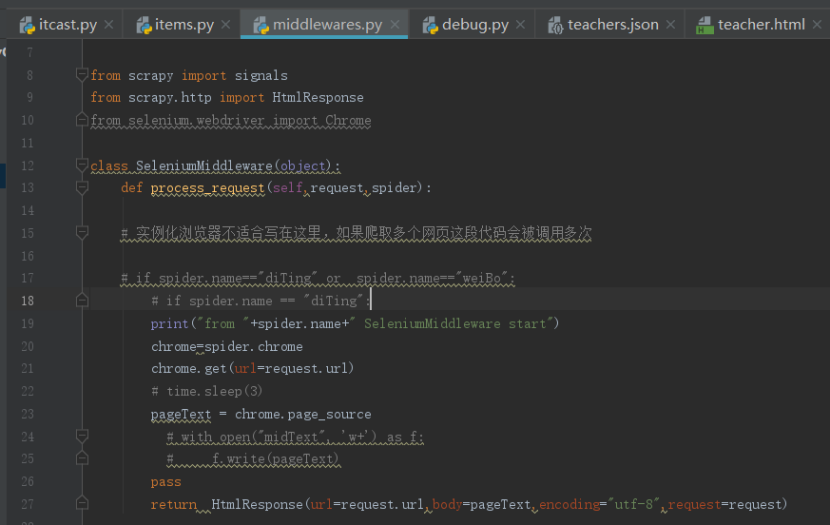
在settings.py中配置中间件SeleniumMiddleware:

在itcast.py中的init函数中实例化浏览器:
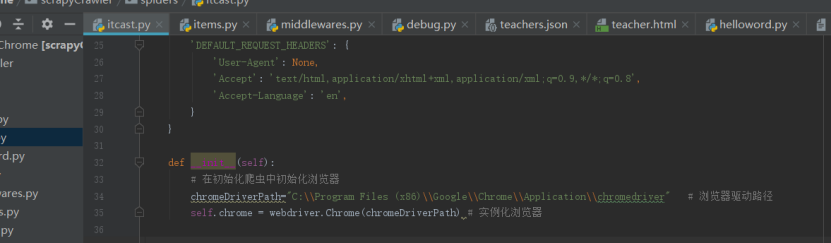
爬取完成后关闭浏览器:
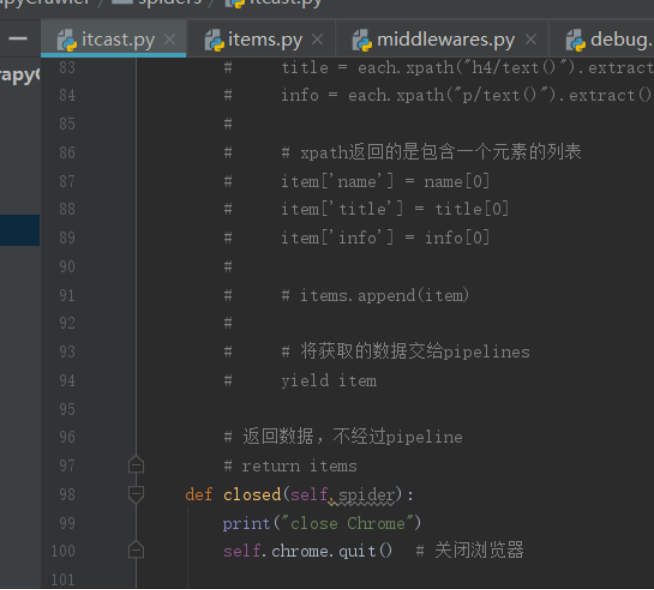
这样,每次爬取一个网页时,爬虫就会在浏览器中打开它,以此获取网页的全部内容,以便后续分析和爬取。
常见反爬虫机制与应对方法小结
当我们开始编写并使用基本的爬虫程序进行网站爬取的时候,总是会遇到很多爬虫程序无法正常工作的情况。这些情况通常包括:程序直接报错,在网络状况正常的情况下无法向指定网站发起访问;程序能够正常运行,但是无法爬取网站数据;程序前两次能爬取到数据,之后无法正常工作等。这种时候,除了爬虫程序本身的逻辑问题,还有可能是因为目标网站采取了反爬手段阻止了爬虫程序访问网站数据。下面对几种常见的反爬手段和应对方法进行总结。下面的内容都是在Scrapy爬虫框架下进行讲解的。
数据头User-Agent反爬虫
当我们使用浏览器访问网站的时候,浏览器会向网站发送http请求,来获取请求url中的内容。我们称为Request Headers,在这个头部信息里面包含了本次访问的一些信息,例如编码方式、当前地址、将要访问的地址等等。在这个头部有一个字段叫做User-Agent,这个字段主要用来说明这个请求来自哪种浏览器。
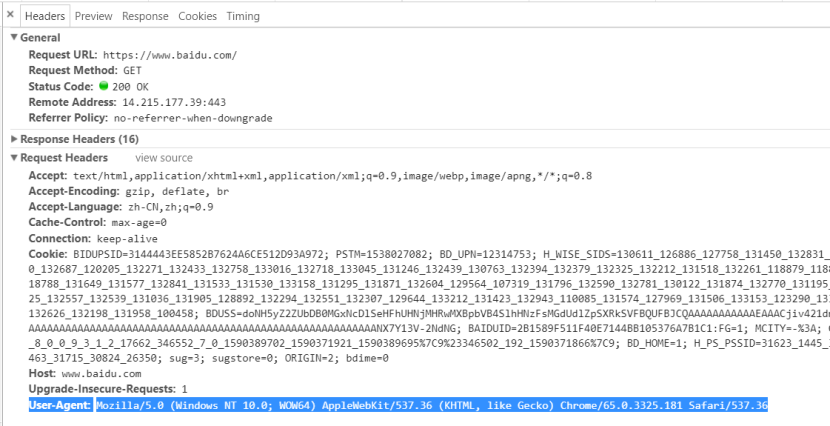
如果我们不做任何设置直接使用Scrapy的request请求去访问网站,这个请求的Request Headers中有一些字段是没有填写的。网站发现收到的User-Agent为空,那么它就有理由怀疑此次访问不是由浏览器发起的,因此拒绝访问。
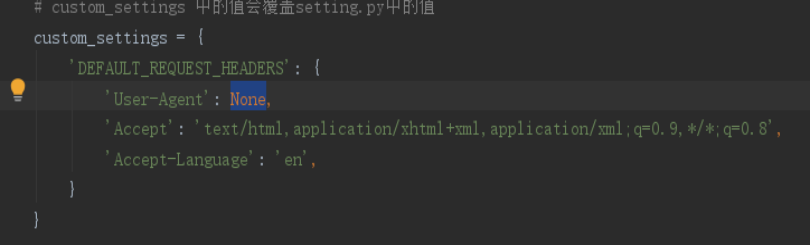
解决方法:设置爬虫中Request Headers中的User-Agent,最简单的就是直接去浏览器中把User-Agent部分复制进来。
 设置用户及IP访问频率限制
设置用户及IP访问频率限制
爬虫直接爬取网页的速度很快,可能一秒内会访问一个网页数次,会被判定为非人工访问。很多网站对于一个用户或者一个IP的访问频率都做了限制,还有一些网站会检查同一个IP或用户连续访问网站的时间间隔是否固定。
解决方法:需要设置爬虫访问频率和访问间隔时间,使用低的访问频率和随机的访问间隔。如果要提高效率,可以使用分布式爬虫并行进行爬取。同时还可以使用IP代理,使用多个IP同时爬取,也可以购买用户池使用大量小号同时爬取。
对于IP代理,当同时使用Selenium和需要输入用户名密码的IP代理时,浏览器不会直接在代理模式中打开。目前的一个解决方法是在本地存储一个浏览器的代理插件,每次进行IP代理爬取时,将代理信息写入代理插件中,并加载至浏览器中;另一种方法是在开着代理软件的情况下进行爬取。
使用js动态加载网页html文档
有的网站html文档的大部分内容由js动态加载生成。爬虫直接爬取只能得到静态页面,无法得到动态加载的部分。例如直接访问www.bilibili.com这个url只能得到几十行内容。
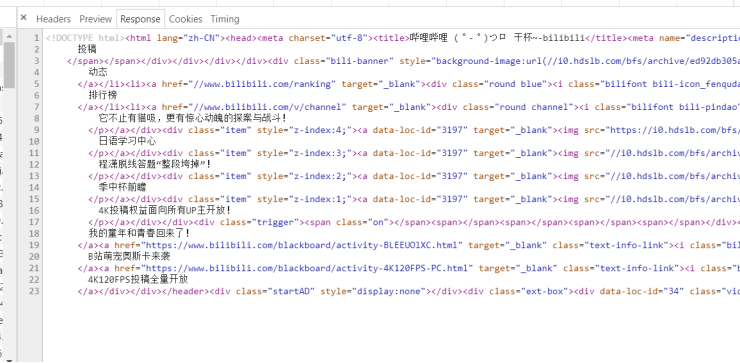
解决此问题的两种方法:
1.分析网页的js加载方法,构造ajax请求获取动态加载的内容。
2.使用Selenium控制浏览器进行访问,通过浏览器自行加载网页内容,这样能够爬取动态加载的内容。
第一种很难做到,不仅需要构造大量请求,而且如果网站后端接口发生变化,爬虫也可能失效。一般推荐使用第二种方法:让浏览器自动加载,即Scrapy与Selenium结合使用。
Scrapy结合Selenium进行抓取采用Downloader Middleware来实现,在Middleware中的process_request()方法里面对每个抓取请求进行额外处理,启动浏览器并进行页面渲染,再将渲染后的结果构造一个HtmlResponse返回即可,这个HtmlResponse中包含了网页中所有能在浏览器找到的内容。
用户登录和验证码验证
有些网站只有进行登录后才能查看完整内容。这种情况比较复杂,按照登录方式进行如下区分。
1.直接登陆:直接输入用户名密码点击登录按钮即可登录。这种情况可以直接用Selenium在浏览器中进行输入和点击操作。
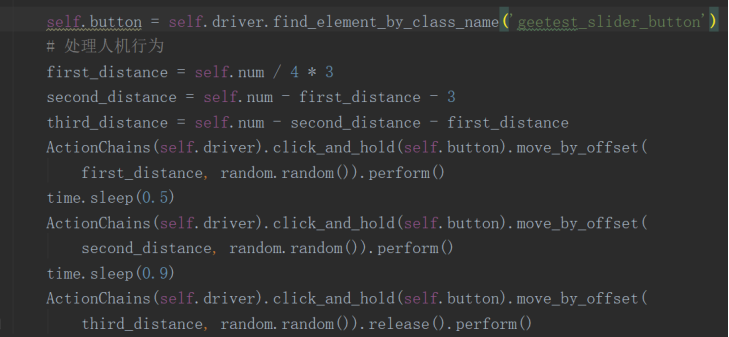
2.简单的拼图验证(例如b站):
主要流程:
1)爬虫获取完整的拼图背景图片;
2)爬虫获取有缺口的拼图背景图片;
3)对比两张图片的像素区别找到缺口位置;
4)分几段拖动拼图到缺口位置(模仿人的不规则拖动速度,不能一下拖到终点,也不能匀速拖到终点)。
3.使用Cookie登录:一次登录成功后,获取浏览器中的Cookie,在下次Selenium启动浏览器前,将cookie存入浏览器,即可免去登录。Cookie有时效,过一段时间可能失效。
4.手机号验证:在接收验证码的手机上安装应用Tasker。Tasker是一个让安卓系统根据用户定制的“配置文件”(Profiles),在特定的“背景”下(Contexts),执行指定“任务”(Tasks)的软件。除此之外,它还提供“可供点击”的(Clickable)或“定时运行”的(Timer)桌面“插件”(Widget)。
需要在Tasker中设置触发事件为短信,并设置短信过滤条件,之后调用post将符合过滤条件的验证码短信文本回传至爬虫。

5.识图认字验证:比较常见的是认字母数字汉字。这种情况不能简单地进行登录。目前一种方法是去买识别验证码的服务,一种是用神经网络进行训练识别。还没找到其他比较简单的方法。
以上就是Scrapy+Selenium爬虫以及一些常见的反爬手段和应对方法的分享。上述内容可以作为我们编写程序爬取普通网站时的参考。同时我们也可以看出反爬虫与爬虫之间,是验证人类操作和模仿人类操作的较量。站在模仿普通人浏览网页的角度可以有效帮助我们编写更有效的爬虫程序。

轮值总编:张纪峰
责任编辑:王咪咪
美编:杨超
技术支持:舒兆鑫

我们的开心 · 总编辑部
(e 语)

长按二维码 关注我们
- 快 乐 生 活 开 心 工 作 我 们 的 开 心微信号:abc_kx ■ 本文为“我们的开心”第3234期文章 ■ 转载本号文章请联系我们■欢迎来稿:请按“作品名-作者-部门”命名,发送到abckx@abchina.com













 148
148











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









