







 Eyeriss是MIT设计的一款以能效为中心的深度学习处理器,采用数据流架构,重点在于行固定RS计算规则。文章详细介绍了其创新设计,包括168个PE单元、四级存储架构、行固定RS数据流、RLC和PE数据门控,以及如何减少数据流动和利用数据统计提高能效。Eyeriss展现了在CNN处理中的高能效优势。
Eyeriss是MIT设计的一款以能效为中心的深度学习处理器,采用数据流架构,重点在于行固定RS计算规则。文章详细介绍了其创新设计,包括168个PE单元、四级存储架构、行固定RS数据流、RLC和PE数据门控,以及如何减少数据流动和利用数据统计提高能效。Eyeriss展现了在CNN处理中的高能效优势。

MIT的深度学习处理器Eyeriss一直以来是学术研究的标杆性处理器之一。Eyeriss处理器强调着能效优先的规则,这点与学术派的架构设计有着明显不同侧重。与传统的控制流处理器不同的地方是,Eyeriss也是一种数据流架构思想的处理器,核心的地方是对于PE计算单元设计了自主的行固定RS(Row stationary)计算规则。在其学术性上有着较为不错的研究价值。今天一起来探究一下出身名门的Eyeriss。
Eyeriss的主要创新设计有几下几点:
- 提出了利用168个PE单元的空间架构,该架构将存储分为4个层次。数据的流动有着显著的降低成本。
- 提出了行固定RS(Row stationary)的CNN的数据流。
- 在NOC方面,同时采用了多播和P2P单循环数据传输,用以确保支持RS数据流。
- 在CNN中含'0'的处理上采用了运行长度压缩(RLC)和PE数据门控。
接下来,让我们带着这四个创新特点,分析Eyeriss的架构优势:
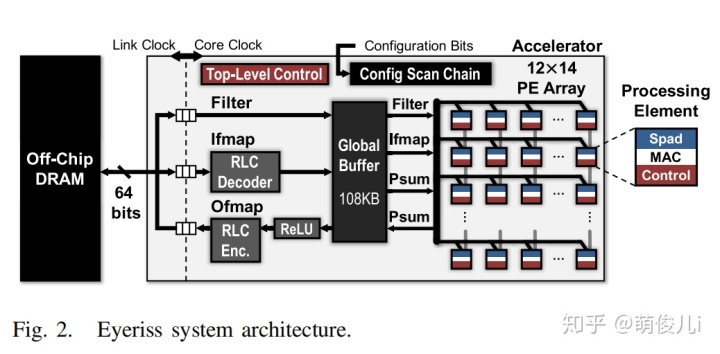
上图是Eyeriss的顶层设计架构。从虚线部分左右来看,其具有两个时钟域,用FIFO进行异步通信。
- 链接时钟 :负责与片外的DRAM进行通信,64bit
- 核心时钟 :负责左侧处理单元的时钟
核心时钟域包含12×14矩形的共计168个PE运算单元,108kB的GLB,RLC模块和ReLU模块。
从图中的PE连接关系可以看出,每个PE可以访问各自连接的三个部分,1,其周围(neighbor )的PE,2、PE本地的存储Spads,3、Global Buffer。
在设计中,存储单元的四个层次分别为(由高至低):DRAM,GLB,PE间的内存和PE内部的Spad。
在加速器的控制方面,总有两个层次的控制:
top-level的控制:
- 片外之间的控制信号,DRAM和GLB通过异步接口;
- 通过NoC在GLB和PE阵列之间的控制信号;
- RLC CODEC和ReLU模块的操作。
low-level的控制:
在每个PE单元中的运算控制,虽然每个PE单元的运算时钟都是在core clock下,但是他们却独自进行自己的运算,这与脉动阵列的架构有着不同。每个PE只需要等待所需要的数据(fmap或psum)到达,就开始进行按照PE设定的步骤开始自己单元的运算。
接下来的部分就是核心的设计思想,对于芯片的高能效部分,提出了两种主要设计思想:1)减少数据流动,2)利用数据统计,根据这两个关键的思想,分别提出了行固定式数据流和利用显式的数据统计(计算统计'0')
- 行固定式数据流RS(Row Stationary)
The RS dataf
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









