






1.bagging & boosting
bagging: 自举汇聚法。它是一种基于数据随机重抽样的分类器构建方法,是在原始数据集选择S次后得到S个新数据集的一种技术。新数据集和原数据集大小相等。也有一些更为先进的bagging算法,如随机森林。
boosting: boosting是一种与bagging很类似的一种技术,在前者中,不同的分类器是通过串行训练而获得的,每个新分类器都根据已训练出的分类器的性能进行训练。boosting是通过集中关注被已有分类器错分的那些数据来获得新的分类器。bagging中的分类器权重是相等的,而boosting中的分类器权重是不相等的,每个权重代表其对应分类器在上一轮迭代中的成功度。
2.XGBoost的学习
XGBoost是boosting算法的其中一种。Boosting算法的思想是将许多弱分类器集成在一起形成一个强分类器。因为XGBoost是一种提升树模型,所以它是将许多树模型集成在一起,形成一个很强的分类器。然后我们来深入探讨下该算法的思想和原理:
XGBoost算法思想
该算法思想就是不断地添加树,不断地进行特征分裂来生成一棵我们最终需要的树,每次添加一个树,其实是选择分类器,去学习一个新函数,去拟合上次预测的残差。当我们训练完成得到k棵树,我们要预测一个样本的分数,其实就是根据这个样本的特征,在每棵树中会落到对应的一个叶子节点,每个叶子节点就对应一个分数,最后只需要将每棵树对应的分数加起来就是该样本的预测值。接着我们假设有K棵树:可以得到
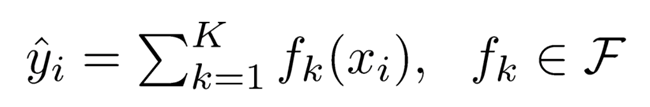
接着就可以得到XGBoost算法的目标函数即为:
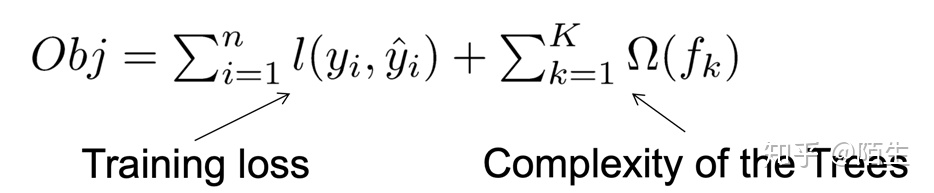
目标函数由两部分构成,第一部分用来衡量预测分数和真实分数的差距,另一部分则是正则化项。 新生成的树是要拟合上次预测的残差的,即当生成t棵树后,预测分数可以写成:
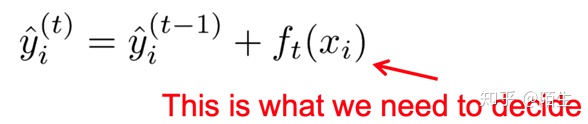
同时,可以将目标函数改写成:

很明显,我们接下来就是要去找到一个
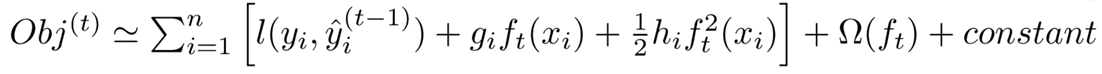
最终我们可以得到新的目标函数:
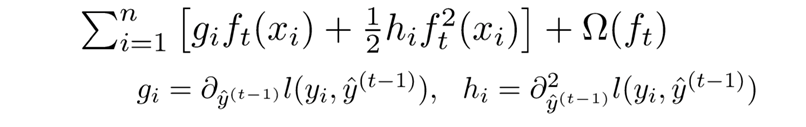
每个样本都最终会落到一个叶子结点中,所以我们可以将所以同一个叶子结点的样本重组起来,过程如下图:
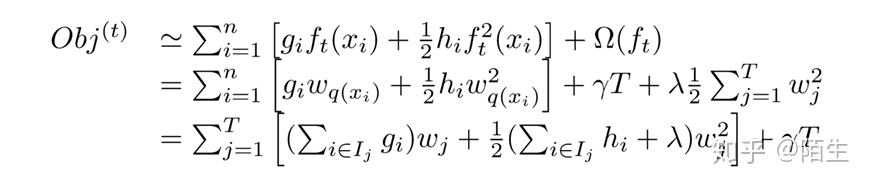
通过改写,我们可以将目标函数改写成关于叶子结点分数w的一个一元二次函数,直接使用顶点公式求解最优的w和目标函数值。因此,最优的w和目标函数公式为:
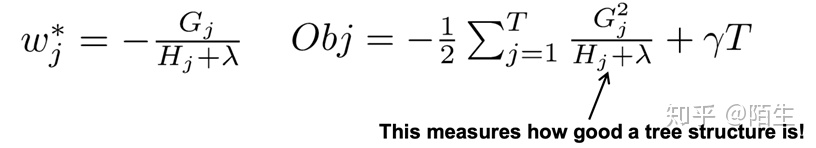
最后我们来看一下树的复杂度:
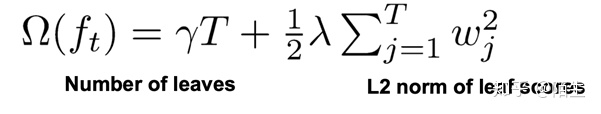
其中
3.代码实现抽取
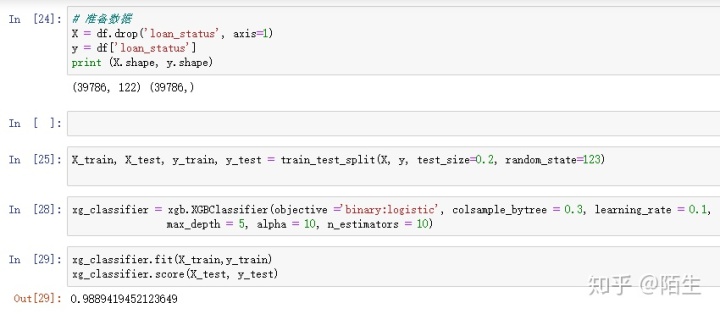
从核心代码可以看出xgboost算法使用十分方便,首先是准备数据,不可避免的要进行数据的清洗,得到所需的数据,调用方法进行训练和测试,最终得到分类的得分结果。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









