






一、XGBoost在Ensemble Learning中的位置
机器学习中,有一类算法叫集成学习(Ensemble Learning),所谓集成学习,指将多个分类器的预测结果集成起来,作为最终预测结果,它要求每个分类器具备一定的“准确性”和“差异性”。通俗理解,集成学习的思想就是“三个臭皮匠,顶个诸葛亮”,多个弱分类器联合起来变成强分类器。集成学习根据分类器之间的依赖关系,划分为Boosting和Bagging两大门派,XGBoost(由华盛顿大学的陈天奇等人提出,因XGBoost出众的训练速度和准确率,受到广泛关注和应用)属于Boosting算法,它是在GBDT基础上的优化算法,如下图:

二、XGBoost的基本思想和举例
XGBoost算法的基本思想跟GBDT类似,不断地通过特征分裂生长一棵树,每一轮学习一棵树,其实就是去拟合上一轮模型的预测值与实际值之间的残差。当训练完成,得到k棵树,如果要预测一个样本的分数,其实就是根据这个样本的特征,在每棵树中落到对应的一个叶子节点,每个叶子节点对应一个分数,最后只需将每棵树对应的分数加起来就是该样本的预测值。

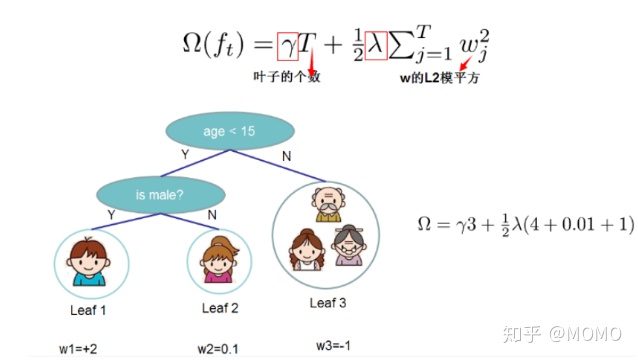
未完待续……
三、XGBoost在GBDT基础上做了哪些优化?
1、导数信息:GBDT只用到一阶导数信息,而XGBoost对损失函数做二阶泰勒展开,引入一阶导数和二阶导数。
2、基分类器:GBDT以传统CART作为基分类器,而XGBoost不仅支持CART决策树,还支持线性分类器,相当于引入L1和L2正则化项的逻辑回归(分类问题)和线性回归(回归问题)。
3、特征采样:XGBoost借鉴RF的做法,即类似RandomForestClassifier的max_features,支持列抽样,不仅能防止过拟合,还能降低计算量。
4、正则项:XGBoost的目标函数加了正则化项控制模型的复杂度,防止模型过拟合。
5、并行化:XGBoost支持并行,不是tree维度上的并行,而是特征维度上的并行,决策树最耗时的步骤是对特征的值排序,XGBoost在迭代之前,先进行预排序,将每个特征按特征值排好序,存为块结构,分裂结点时可以采用多线程并行查找每个特征的最佳分割点(计算增益最大的特征进行下一步分裂),极大提升训练速度。
6、缺失值:当样本的特征值存在缺失值时,XGBoost能自动学习出它的默认分裂方向。四、两种方法控制 XGBoost的过拟合(训练精度高而测试精度低)
方法1:直接控制模型的复杂度(max_depth,min_child_weight,gamma)
max_depth:每棵树的最大深度限制。
min_child_weight:子节点的最小权重,如果某个子节点权重小于这个阈值,则不会在分裂。
gamma:分裂所带来的损失最小阈值,大于此值,才会继续分裂。
方法2:增加随机性,使训练对噪声强健(subsample,colsample_bytree,减小步长eta且增加迭代次数num_round )
subsample:用于训练模型的子样本占整个样本集合的比例,能防止过拟合,取值范围为(0,1].
colsample_bytree:训练每棵树时用来训练的特征的比例,类似 RandomForestClassifier 的 max_features,在建立树时对特征采样的比例,缺省值为1,取值范围(0,1].
eta:每次迭代完成后更新权重时的步长,越小训练越慢,缺省值为0.3,取值范围为[0,1].
num_round :总共迭代的次数。五、XGBoost中偏差(Bias)与方差(Variance)的权衡
Bias-Variance是机器学习/统计学中一个重要的概念。当模型变得复杂时(例如树的深度更深),模型具有更强的拟合训练数据的能力,产生一个低偏差的模型,但是,复杂的模型容易过拟合,需要更多的数据来拟合。XGBoost中的大部分参数都是关于偏差和方差的权衡,最好的模型应该仔细地将模型复杂性(拟合能力)与其预测能力进行权衡。
六、使用XGBoost的示例代码
# step1:导入模块
import xgboost as xgb
# step2:读取数据
dtrain = xgb.DMatrix('demo/data/train.csv')
dtest = xgb.DMatrix('demo/data/test.csv')
# step3:指定参数
param = {'max_depth':2, 'eta':1, 'silent':1, 'objective':'binary:logistic' } # 二分类的逻辑回归问题,输出为概率值。
num_round = 2
# step4:训练
bst = xgb.train(param, dtrain, num_round)
# step5:预测
preds = bst.predict(dtest)参考资料:
XGBoost官网:https://xgboost.apachecn.org/#/
XGBoost20题:https://blog.csdn.net/weixin_38753230/article/details/100571499
XGBoost算法:https://www.cnblogs.com/mantch/p/11164221.html















 7万+
7万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









