 Pandas数据处理实战
Pandas数据处理实战




 本文介绍Pandas这一强大工具在数据处理中的应用,包括数据清洗、转换及分析等核心技能。Pandas能有效应对诸如重复数据、缺失值等问题,并提供灵活的数据结构如Series和DataFrame,便于进行统计分析和数据准备。
本文介绍Pandas这一强大工具在数据处理中的应用,包括数据清洗、转换及分析等核心技能。Pandas能有效应对诸如重复数据、缺失值等问题,并提供灵活的数据结构如Series和DataFrame,便于进行统计分析和数据准备。
『运筹OR帷幄』原创
作者:佘亮
编者按:
数据处理是数据分析的核心部分,通过爬虫或者实际生产过程中初步获取的数据通常具有很多的“垃圾数据”,比如重复数据或者值缺失,不连续数据等等。这时就需要对数据首先进行筛选,补全等“清洗”操作。
数据处理是数据分析的核心部分,通过爬虫或者实际生产过程中初步获取的数据通常具有很多的“垃圾数据”,比如重复数据或者值缺失,不连续数据等等。这时就需要对数据首先进行筛选,补全等“清洗”操作。除此之外,“清洗”好的数据也需要根据不同的用途来进行转换,以适应分析,预测或者可视化的需求。
数据的处理的软件包有很多,在python中主要应用Pandas来进行处理。Pandas是一个十分成熟的数据处理包,熟练掌握可以高效并且方便地将数据进行转换和清洗,本节主要整理了pandas的一些基本技能和实用技巧,为励志成为数据分析师的你铺路搭桥。
以下是本教程的总体提纲,这篇文章首先对pandas的基本操作进行介绍,其他内容敬请期待后续的文章。另附上我征稿通知的链接:数据科学 | 『运筹OR帷幄』数据分析、可视化、爬虫系列教程征稿
一 数据分析相关python包介绍
- 常用数据分析库NumPy, Pandas, SciPy, statssmodels, scikit-learn, NLTK的简介与安装
- 数据分析开发环境搭建
二 数据的导入与导出
- 读取csv数据
- 读取mysql数据
三 数据提取与筛选
- 常见的数据格式与形态
- Python对不同形式数据的读写
四 数据清洗处理
- 如何对数据进行清洗
- Pandas基本数据结构与功能
- Pandas统计相关功能
- Pandas缺失数据处理
- Pandas层次化索引
- Pandas DataFrame
五 高性能科学计算和数据分析的基础包Numpy
- NumPy的性能优势
- 数组对象处理
- 文件输入输出
- 线性代数相关功能
- 高效操作实践
六 统计分析
- 线性回归
- 逻辑回归
- SVM
- K紧邻算法
- 神经网络
- 机器学习库Scikit-Learn与应用
- 使用NLTK进行Python文本分析
- Python深度学习keras入门
Pandas入门
Pandas 是基于 NumPy 的一个开源 Python 库,它被广泛用于数据分析,以及数据清洗和准备等工作。数据科学家经常和表格形式的数据(比如.csv、.tsv、.xlsx)打交道。Pandas可以使用类似SQL的方式非常方便地加载、处理、分析这些表格形式的数据。搭配Matplotlib和Seaborn效果更好。
pandas可以满足以下需求:
- 具备按轴自动或显式数据对齐功能的数据结构。这可以防止许多由于数据未对齐以及来自不同数据源(索引方式不同)的数据而导致的常见错误、集成时间序列功能、既能处理时间序列数据也能处理非时间序列数据的数据结构、数学运算和简约(比如对某个轴求和)可以根据不同的元数据(轴编号)执行、
- 灵活处理缺失数据、
- 在实际构建任何模型之前,任何机器学习项目中的大量时间都必须花费在准备数据、
- 分析基本趋势和模式上。因此需要Pandas来进行处理。
下面我们开始今天的学习之旅。
Pandas的安装与导入
首先,在使用Pandas前,必须安装Pandas。如果你安装过Anaconda,就可以执行如下命令安装Pandas:
conda install pandas
如果没有安装Anaconda,也没有关系,可以使用Python的pip命令来安装:
pip install pandas
注意:pandas安装会用到numpy库,因此在安装pandas之前一定要安装好numpy。
导入:为了简便,这里使用pd作为pandas的缩写,因为pandas依赖numpy,所以在使用之前需要安装和导入numpy
import numpy as np
import pandas as pd
打印pandas的版本
pd.__version__
考虑如下的Python字典数据和Python列表标签:
data = {'animal': ['cat', 'cat', 'snake', 'dog', 'dog', 'cat', 'snake', 'cat', 'dog', 'dog'],
'age': [2.5, 3, 0.5, np.nan, 5, 2, 4.5, np.nan, 7, 3],
'visits': [1, 3, 2, 3, 2, 3, 1, 1, 2, 1],
'priority': ['yes', 'yes', 'no', 'yes', 'no', 'no', 'no', 'yes', 'no', 'no']}
labels = ['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j']
Pandas数据结构介绍
Pandas有两个数据结构:Series和DataFrame。
- Series是一种类似于以为NumPy数组的对象,它由一组数据(各种NumPy数据类型)和与之相关的一组数据标签(即索引)组成的。可以用index和values分别规定索引和值。如果不规定索引,会自动创建 0 到 N-1 索引。
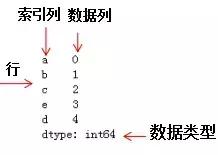
- DataFrame是一种表格型结构,含有一组有序的列,每一列可以是不同的数据类型。既有行索引,又有列索引。

pd.DataFrame:创建pandas矩阵
pd.Series 创建pandas列表
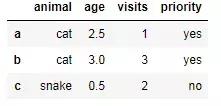
1.从具有索引标签的字典数据创建一个DataFrame df.
df = pd.DataFrame(data,index = labels)
返回DataFrame的前三行
df.iloc[:3]
df.head(3)
运行结果如下:
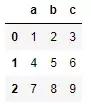
2.从numpy 数组构造DataFrame
df2 = pd.DataFrame(np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]]),columns=['a', 'b', 'c'])
df2
运行结果如下
3.通过其他DataFrame来创建DataFrame df3
df3 = df2[["a

















 78
78

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









