








 本文详细介绍了如何部署和配置Alertmanager,设置Prometheus与Alertmanager的交互,创建报警规则,并实现通过Prometheus-webhook-dingtalk将告警推送到钉钉群。涵盖了配置文件、告警路由、规则设置及Webhook应用等内容。
本文详细介绍了如何部署和配置Alertmanager,设置Prometheus与Alertmanager的交互,创建报警规则,并实现通过Prometheus-webhook-dingtalk将告警推送到钉钉群。涵盖了配置文件、告警路由、规则设置及Webhook应用等内容。
目录
2.1、配置Prometheus推送至alertmanager
4.2、部署prometheus-webhook-dingtalk接口
4.3、配置prometheus-webhook-dingtalk生成的推送地址
flannel+prometheus+kibana+alertmanager系列源码包:
https://download.csdn.net/download/weixin_39855998/51382258
Alertmanager是一个独立的告警模块。
-
接收Prometheus等客户端发来的警报
-
通过分组、删除重复等处理,并将它们通过路由发送给正确的接收器;
-
告警方式可以按照不同的规则发送给不同的模块负责人。Alertmanager支持Email, Slack,等告警方式, 也可以通过webhook接入钉钉等国内IM工具。
-
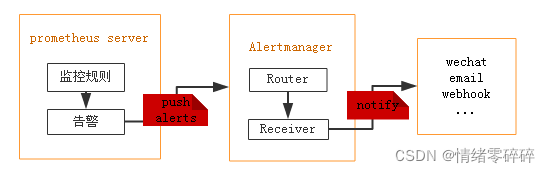
从上图可得知设置警报和通知的主要步骤是:
-
安装和配置 Alertmanager
-
配置Prometheus与Alertmanager对话
-
在Prometheus中创建警报规则
-
Alertmanager实现邮件和钉钉告警
1、Alertmanager部署和配置
1.1、alertmanager-config配置文件
$ cat alertmanager-config.yml
apiVersion: v1
data:
config.yml: |
# global: 全局配置,包括报警解决后的超时时间、SMTP 相关配置、各种渠道通知的 API 地址等等。
global:
# 当alertmanager持续多长时间未接收到告警后标记告警状态为 resolved
resolve_timeout: 5m
# 配置邮件发送信息
# 必须配置,类似虚拟发送源,smtp_auth_password配置三方认证码
smtp_smarthost: 'smtp.163.com:25'
smtp_from: 'haha163@163.com'
smtp_auth_username: 'haha163@163.com'
smtp_auth_password: 'hahahahhahaha'
smtp_require_tls: false
# 所有报警信息进入后的根路由,用来设置报警的分发策略
# route: 用来设置报警的分发策略,它是一个树状结构,按照深度优先从左向右的顺序进行匹配。
route:
# 接收到的报警信息里面有许多alertname=NodeLoadHigh 这样的标签的报警信息将会批量被聚合到一个分组里面
group_by: ['alertname']
# 当一个新的报警分组被创建后,需要等待至少 group_wait 时间来初始化通知,如果在等待时间内当前group接收到了新的告警,这些告警将会合并为一个通知向receiver发送
group_wait: 30s
# 相同的group发送告警通知的时间间隔
group_interval: 30s
# 如果一个报警信息已经发送成功了,等待 repeat_interval 时间来重新发送
repeat_interval: 1m
# 默认的receiver:如果一个报警没有被一个route匹配,则发送给默认的接收器
receiver: default
# 上面所有的属性都由所有子路由继承,并且可以在每个子路由上进行覆盖。
routes:
- {}
# receivers: 告警消息接受者信息,例如常用的 email、wechat、slack、webhook 等消息通知方式
receivers:
- name: 'default'
email_configs:
- to: '111100001@qq.com'
send_resolved: true # 接受告警恢复的通知
kind: ConfigMap
metadata:
name: alertmanager
namespace: monitor1.2、alertmanager其他资源清单文件
$ cat alertmanager-all.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: alertmanager
namespace: monitor
labels:
app: alertmanager
spec:
selector:
matchLabels:
app: alertmanager
template:
metadata:
labels:
app: alertmanager
spec:
volumes:
- name: config
configMap:
name: alertmanager
containers:
- name: alertmanager
image: prom/alertmanager:v0.21.0
imagePullPolicy: IfNotPresent
args:
- "--config.file=/etc/alertmanager/config.yml"
- "--log.level=debug"
ports:
- containerPort: 9093
name: http
volumeMounts:
- mountPath: "/etc/alertmanager"
name: config
resources:
requests:
cpu: 100m
memory: 256Mi
limits:
cpu: 100m
memory: 256Mi
---
apiVersion: v1
kind: Service
metadata:
name: alertmanager
namespace: monitor
spec:
type: ClusterIP
ports:
- port: 9093
selector:
app: alertmanager
---
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: alertmanager
namespace: monitor
spec:
rules:
- host: ale.haha.com
http:
paths:
- path: /
backend:
serviceName: alertmanager
servicePort: 9093[root@k8s-master k8s-primetheus]# kubectl get po -n monitor
NAME READY STATUS RESTARTS AGE
alertmanager-55d888f6d4-z9f94 1/1 Running 0 22m
grafana-d7c4c4bf7-w4scz 1/1 Running 1 7d
kube-state-metrics-59f9c568fc-99gb2 1/1 Running 2 8d
node-exporter-78ffd 1/1 Running 2 8d
node-exporter-gtccl 1/1 Running 2 8d
node-exporter-gw4mv 1/1 Running 2 8d
prometheus-64987d8b68-lqpnw 1/1 Running 0 46m
2、配置Prometheus与Alertmanager对话
是否告警是由Prometheus进行判断的,若有告警产生,Prometheus会将告警push到Alertmanager,因此,需要在Prometheus端配置alertmanager的地址:
2.1、配置Prometheus推送至alertmanager
# 编辑prometheus-configmap.yaml配置,添加alertmanager内容
$ vim prometheus-configmap.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: prometheus-config
namespace: monitor
data:
prometheus.yml: |
global:
scrape_interval: 30s
evaluation_interval: 30s
alerting:
alertmanagers:
- static_configs:
- targets:
- alertmanager:9093
...
$ kubectl apply -f prometheus-configmap.yaml2.2、热加载Prometheus
# 现在已经有监控数据了,因此使用prometheus提供的reload的接口,进行服务重启
# 查看配置文件是否已经自动加载到pod中
$ kubectl -n monitor get po -o wide
prometheus-dcb499cbf-pljfn 1/1 Running 0 47h 10.244.1.167
$ kubectl -n monitor exec -ti prometheus-64987d8b68-bfqq2 cat /etc/prometheus/prometheus.yml |grep alertmanager
# 使用软加载的方式,
$ curl -X POST 10.244.2.36:9090/-/reload3、prometheus配置报警规则
目前Prometheus与Alertmanager已经连通,接下来我们可以针对收集到的各类指标配置报警规则,一旦满足报警规则的设置,则Prometheus将报警信息推送给Alertmanager,进而转发到我们配置的邮件中。
3.1、配置prometheus加载告警规则配置
在哪里配置?同样是在prometheus-configmap中:
$ vim prometheus-configmap.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: prometheus-config
namespace: monitor
data:
prometheus.yml: |
global:
scrape_interval: 30s
evaluation_interval: 30s
alerting:
alertmanagers:
- static_configs:
- targets:
- alertmanager:9093
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
- /etc/prometheus/alert_rules.yml
# - "first_rules.yml"
# - "second_rules.yml"
scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets: ['localhost:9090']
...rules.yml我们同样使用configmap的方式挂载到prometheus容器内部,因此只需要在已有的configmap中加一个数据项目
3.1、配置告警规则
$ vim prometheus-configmap.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: prometheus-config
namespace: monitor
data:
prometheus.yml: |
global:
scrape_interval: 30s
evaluation_interval: 30s
alerting:
alertmanagers:
- static_configs:
- targets:
- alertmanager:9093
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
- /etc/prometheus/alert_rules.yml
# - "first_rules.yml"
# - "second_rules.yml"
scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets: ['localhost:9090']
... # 省略中间部分
alert_rules.yml: |
groups:
- name: node_metrics
rules:
- alert: NodeLoad
expr: node_load15 < 1
for: 2m
annotations:
summary: "{{$labels.instance}}: Low node load detected"
description: "{{$labels.instance}}: node load is below 1 (current value is: {{ $value }}"告警规则的几个要素:
group.name:告警分组的名称,一个组下可以配置一类告警规则,比如都是物理节点相关的告警
alert:告警规则的名称
expr:是用于进行报警规则 PromQL 查询语句,expr通常是布尔表达式,可以让Prometheus根据计算的指标值做 true or false 的判断
for:评估等待时间(Pending Duration),用于表示只有当触发条件持续一段时间后才发送告警,在等待期间新产生的告警状态为pending,屏蔽掉瞬时的问题,把焦点放在真正有持续影响的问题上
labels:自定义标签,允许用户指定额外的标签列表,把它们附加在告警上,可以用于后面做路由判断,通知到不同的终端,通常被用于添加告警级别的标签
annotations:指定了另一组标签,它们不被当做告警实例的身份标识,它们经常用于存储一些额外的信息,用于报警信息的展示之类的规则配置中,支持模板的方式,其中:
{{$labels}}可以获取当前指标的所有标签,支持{{$labels.instance}}或者{{$labels.job}}这种形式
{{ $value }}可以获取当前计算出的指标值
查看Alertmanager日志:
level=warn ts=2020-07-28T13:43:59.430Z caller=notify.go:674 component=dispatcher receiver=email integration=email[0] msg="Notify attempt failed, will retry later" attempts=1 err="*email.loginAuth auth: 550 User has no permission"说明告警已经推送到Alertmanager端了,但是邮箱登录的时候报错,这是因为邮箱默认没有开启第三方客户端登录。因此需要登录163邮箱设置SMTP服务允许客户端登录。
更新配置并软重启,并查看Prometheus报警规则。
3.3、查看Prometheus报警界面和邮箱
一个报警信息在生命周期内有下面3种状态:
-
inactive: 表示当前报警信息处于非活动状态,即不满足报警条件 -
pending: 表示在设置的阈值时间范围内被激活了,即满足报警条件,但是还在观察期内 -
firing: 表示超过设置的阈值时间被激活了,即满足报警条件,且报警触发时间超过了观察期,会发送到Alertmanager端
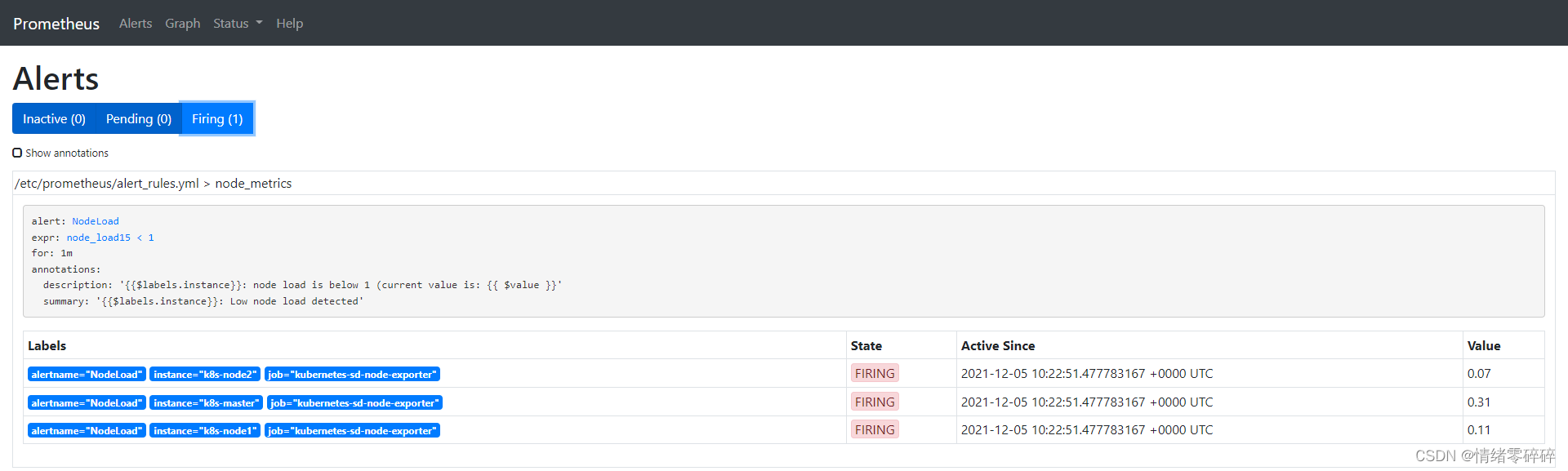
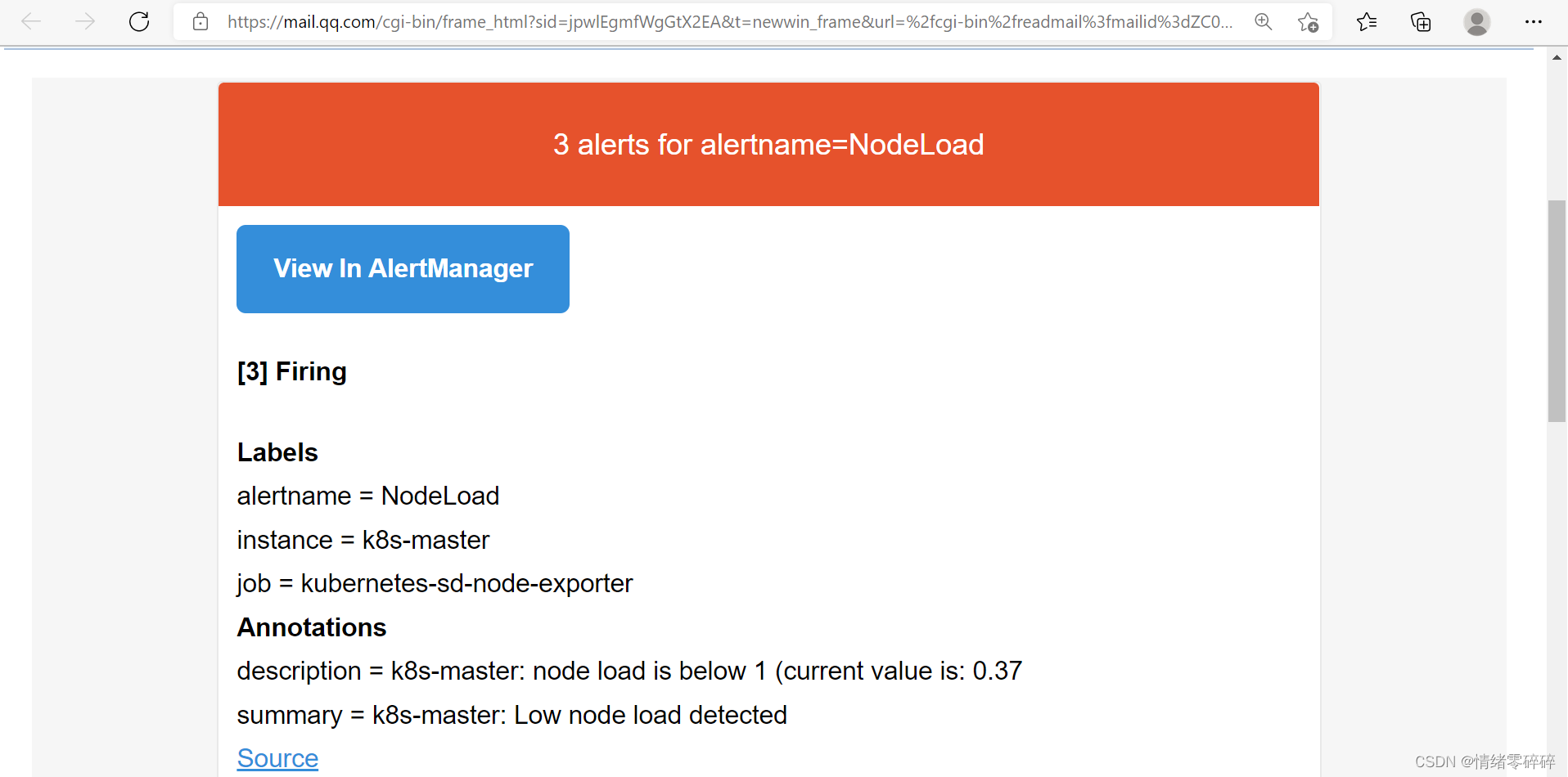
4、自定义webhook钉钉告警
Alertmanager的通知方式中支持Webhook,通过这种方式开发者可以实现更多个性化的扩展支持。
# 警报接收者
receivers:
#ops
- name: 'demo-webhook'
webhook_configs:
- send_resolved: true
url: http://demo-webhook/alert/send当我们配置了上述webhook地址,则当告警路由到demo-webhook时,alertmanager端会向webhook地址推送POST请求:
$ curl -X POST -d"$demoAlerts" http://demo-webhook/alert/send
$ echo $demoAlerts
{
"version": "4",
"groupKey": <string>, alerts (e.g. to deduplicate) ,
"status": "<resolved|firing>",
"receiver": <string>,
"groupLabels": <object>,
"commonLabels": <object>,
"commonAnnotations": <object>,
"externalURL": <string>, // backlink to the Alertmanager.
"alerts":
[{
"labels": <object>,
"annotations": <object>,
"startsAt": "<rfc3339>",
"endsAt": "<rfc3339>"
}]
} 因此,假如我们想把报警消息自动推送到钉钉群聊,只需要:
-
实现一个webhook,部署到k8s集群
-
接收POST请求,将Alertmanager传过来的数据做解析,调用dingtalk的API,实现消息推送
-
配置alertmanager的receiver为webhook地址
4.1、设置钉钉群聊机器人设置
每个群聊机器人在创建的时候都会生成唯一的一个访问地址:
https://oapi.dingtalk.com/robot/send?access_token=e54f616718798e32d1e2ff1af5b095c37501878f816bdab2daf66d390633843a
这样,我们就可以使用如下方式来模拟给群聊机器人发送请求,实现消息的推送:
curl 'https://oapi.dingtalk.com/robot/send?access_token=e54f616718798e32d1e2ff1af5b095c37501878f816bdab2daf66d390633843a' \
-H 'Content-Type: application/json' \
-d '{"msgtype": "text","text": {"content": "我就是我, 是不一样的烟火"}}'
4.2、部署prometheus-webhook-dingtalk接口
这个插件主要实现alertmanager默认的告警格式转换为钉钉的告警格式
YongxinLi/prometheus-webhook-dingtalk
镜像地址:timonwong/prometheus-webhook-dingtalk:master
二进制运行:
$ ./prometheus-webhook-dingtalk --config.file=config.yml
假如使用如下配置:
targets: webhook_dev: url: https://oapi.dingtalk.com/robot/send?access_token=e54f616718798e32d1e2ff1af5b095c37501878f816bdab2daf66d390633843a webhook_ops: url: https://oapi.dingtalk.com/robot/send?access_token=d4e7b72eab6d1b2245bc0869d674f627dc187577a3ad485d9c1d131b7d67b15b则prometheus-webhook-dingtalk启动后会自动支持如下API的POST访问:
http://locahost:8060/dingtalk/webhook_dev/send http://localhost:8060/dingtalk/webhook_ops/send这样可以使用一个prometheus-webhook-dingtalk来实现多个钉钉群的webhook地址
部署prometheus-webhook-dingtalk,从Dockerfile可以得知需要注意的点:
-
默认使用配置文件
/etc/prometheus-webhook-dingtalk/config.yml,可以通过configmap挂载 -
该目录下还有模板文件,因此需要使用subpath的方式挂载
-
部署Service,作为Alertmanager的默认访问,服务端口默认8060
配置文件:
$ cat webhook-dingtalk-configmap.yaml
apiVersion: v1
data:
config.yml: |
targets:
webhook_dev:
url: https://oapi.dingtalk.com/robot/send?access_token=e54f616718798e32d1e2ff1af5b095c37501878f816bdab2daf66d390633843a
kind: ConfigMap
metadata:
name: webhook-dingtalk-config
namespace: monitorDeployment和Service
$ cat webhook-dingtalk-deploy.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: webhook-dingtalk
namespace: monitor
spec:
selector:
matchLabels:
app: webhook-dingtalk
template:
metadata:
labels:
app: webhook-dingtalk
spec:
containers:
- name: webhook-dingtalk
image: timonwong/prometheus-webhook-dingtalk:master
imagePullPolicy: IfNotPresent
volumeMounts:
- mountPath: "/etc/prometheus-webhook-dingtalk/config.yml"
name: config
subPath: config.yml
ports:
- containerPort: 8060
name: http
resources:
requests:
cpu: 50m
memory: 100Mi
limits:
cpu: 50m
memory: 100Mi
volumes:
- name: config
configMap:
name: webhook-dingtalk-config
items:
- key: config.yml
path: config.yml
---
apiVersion: v1
kind: Service
metadata:
name: webhook-dingtalk
namespace: monitor
spec:
selector:
app: webhook-dingtalk
ports:
- name: hook
port: 8060
targetPort: http创建:
$ kubectl create -f webhook-dingtalk-configmap.yaml
$ kubectl create -f webhook-dingtalk-deploy.yaml创建后检查:
# pod状态检查
[root@k8s-master k8s-primetheus]# kubectl get po -n monitor
NAME READY STATUS RESTARTS AGE
alertmanager-55d888f6d4-z9f94 1/1 Running 0 74m
grafana-d7c4c4bf7-w4scz 1/1 Running 1 7d1h
kube-state-metrics-59f9c568fc-99gb2 1/1 Running 2 8d
node-exporter-78ffd 1/1 Running 2 8d
node-exporter-gtccl 1/1 Running 2 8d
node-exporter-gw4mv 1/1 Running 2 8d
prometheus-64987d8b68-lqpnw 1/1 Running 0 98m
webhook-dingtalk-64d84f5485-6tj9s 1/1 Running 0 62s
# 日志检查
# 重点是找到url:http://localhost:8060/dingtalk/webhook_dev/send用来配置到ale配置文件中
[root@k8s-master k8s-primetheus]# kubectl -n monitor logs -f webhook-dingtalk-64d84f5485-6tj9s
level=info ts=2021-12-05T12:00:38.679Z caller=main.go:60 msg="Starting prometheus-webhook-dingtalk" version="(version=2.0.0, branch=master, revision=4e77a3cc3e7a23fcb18b33826bce8d2904583465)"
level=info ts=2021-12-05T12:00:38.679Z caller=main.go:61 msg="Build context" (gogo1.16.7,userroot@337ecc9a2774,date20210819-13:17:15)=(MISSING)
level=info ts=2021-12-05T12:00:38.679Z caller=coordinator.go:83 component=configuration file=/etc/prometheus-webhook-dingtalk/config.yml msg="Loading configuration file"
level=info ts=2021-12-05T12:00:38.679Z caller=coordinator.go:91 component=configuration file=/etc/prometheus-webhook-dingtalk/config.yml msg="Completed loading of configuration file"
level=info ts=2021-12-05T12:00:38.680Z caller=main.go:98 component=configuration msg="Loading templates" templates=
ts=2021-12-05T12:00:38.680Z caller=main.go:114 component=configuration msg="Webhook urls for prometheus alertmanager" urls=http://localhost:8060/dingtalk/webhook_dev/send
level=info ts=2021-12-05T12:00:38.681Z caller=web.go:210 component=web msg="Start listening for connections" address=:8060
4.3、配置prometheus-webhook-dingtalk生成的推送地址
修改Alertmanager路由及webhook配置:
$ cat alertmanager-configmap.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: alertmanager
namespace: monitor
data:
config.yml: |-
global:
# 当alertmanager持续多长时间未接收到告警后标记告警状态为 resolved
resolve_timeout: 5m
# 配置邮件发送信息
smtp_smarthost: 'smtp.163.com:25'
smtp_from: 'earlene163@163.com'
smtp_auth_username: 'earlene163@163.com'
# 注意这里不是邮箱密码,是邮箱开启第三方客户端登录后的授权码
smtp_auth_password: 'GXIWNXKMMEVMNHAJ'
smtp_require_tls: false
# 所有报警信息进入后的根路由,用来设置报警的分发策略
route:
# 按照告警名称分组
group_by: ['alertname']
# 当一个新的报警分组被创建后,需要等待至少 group_wait 时间来初始化通知,这种方式可以确保您能有足够的时间为同一分组来获取多个警报,然后一起触发这个报警信息。
group_wait: 30s
# 相同的group之间发送告警通知的时间间隔
group_interval: 30s
# 如果一个报警信息已经发送成功了,等待 repeat_interval 时间来重新发送他们,不同类型告警发送频率需要具体配置
repeat_interval: 10m
# 默认的receiver:如果一个报警没有被一个route匹配,则发送给默认的接收器
receiver: default
# 路由树,默认继承global中的配置,并且可以在每个子路由上进行覆盖。
routes:
- {}
receivers:
- name: 'default'
email_configs:
- to: '654147123@qq.com'
send_resolved: true # 接受告警恢复的通知
webhook_configs:
- send_resolved: true
url: http://webhook-dingtalk:8060/dingtalk/webhook_dev/send重启alertmanager服务
重新创建pod或者热加载都可以
最后:
验证钉钉消息是否正常收到。
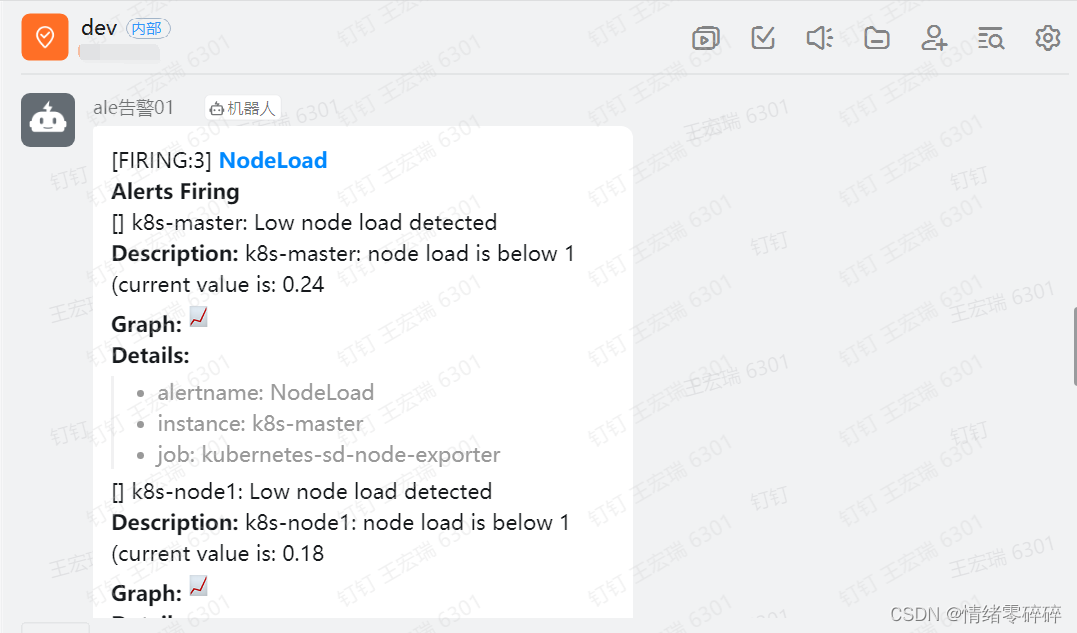
4.4、基于Label的动态告警处理
真实的场景中,我们往往期望可以给告警设置级别,而且可以实现不同的报警级别可以由不同的receiver接收告警消息。例如可以根据不同的告警级别发送至对应的钉钉群。
Alertmanager中路由负责对告警信息进行分组匹配,并向告警接收器发送通知。告警接收器可以通过以下形式进行配置:
routes: - receiver: ops group_wait: 10s match: severity: critical - receiver: dev group_wait: 10s match_re: severity: normal|middle receivers: - ops ... - dev ... - <receiver> ...
因此可以为了更全面的感受报警的逻辑,我们再添加两个报警规则
vim prometheus-configmap.yaml
......
alert_rules.yml: |
groups:
# warning状态告警:load和mem状态
- name: node_metrics
rules:
- alert: NodeLoad
expr: node_load15 < 1
for: 2m
labels:
severity: warning
annotations:
summary: "{{$labels.instance}}节点负载状态较高!"
description: "{{$labels.instance}}: node load is below 1 (current value is: {{ $value }}"
- alert: NodeMemoryUsage
expr: (node_memory_MemTotal_bytes - (node_memory_MemFree_bytes + node_memory_Buffers_bytes + node_memory_Cached_bytes)) / node_memory_MemTotal_bytes * 100 > 25
for: 2m
labels:
severity: warning
annotations:
summary: "{{$labels.instance}}内存占用率大于25%!"
description: "{{$labels.instance}}: Memory usage is above 40% (current value is: {{ $value }}"
- name: targets_status
rules:
- alert: TargetStatus
expr: up == 0
for: 1m
labels:
severity: error
annotations:
summary: "{{$labels.instance}}: 监控节点状态异常,请检查job任务配置是否正常!"
description: "{{$labels.instance}}: prometheus target down,job is {{$labels.job}}" 我们为不同的报警规则设置了不同的标签,如severity: error,针对规则中的label,来配置alertmanager路由规则,实现转发给不同的接收者。
[root@k8s-master k8s-primetheus]# cat alertmanager-config.yml
apiVersion: v1
kind: ConfigMap
metadata:
name: alertmanager
namespace: monitor
data:
config.yml: |
global:
# 当alertmanager持续多长时间未接收到告警后标记告警状态为 resolved
resolve_timeout: 5m
# 配置邮件发送信息
smtp_smarthost: 'smtp.163.com:25'
smtp_from: 'ccccccc@163.com'
smtp_auth_username: 'cccccccc@163.com'
smtp_auth_password: 'cXLDcccccc'
smtp_require_tls: false
# 所有报警信息进入后的根路由,用来设置报警的分发策略
route:
# 接收到的报警信息里面有许多alertname=NodeLoadHigh 这样的标签的报警信息将会批量被聚合到一个分组里面
group_by: ['alertname']
# 当一个新的报警分组被创建后,需要等待至少 group_wait 时间来初始化通知,如果在等待时间内当前group接收到了新的告警,这些告警将会合并为一个通知向receiver发送
group_wait: 30s
# 相同的group发送告警通知的时间间隔
group_interval: 30s
# 如果一个报警信息已经发送成功了,等待 repeat_interval 时间来重新发送
repeat_interval: 1m
# 默认的receiver:如果一个报警没有被一个route匹配,则发送给默认的接收器
receiver: default
# 上面所有的属性都由所有子路由继承,并且可以在每个子路由上进行覆盖。
routes:
- receiver: error_alerts
group_wait: 10s
match:
severity: error
- receiver: warning_alerts
group_wait: 10s
match_re:
severity: normal|warning
receivers:
- name: 'default'
email_configs:
- to: '101123456567@qq.com'
send_resolved: true # 接受告警恢复的通知
- name: 'error_alerts'
webhook_configs:
- send_resolved: true
url: http://webhook-dingtalk:8060/dingtalk/webhook_error/send
- name: 'warning_alerts'
webhook_configs:
- send_resolved: true
url: http://webhook-dingtalk:8060/dingtalk/webhook_warning/send
再配置一个钉钉机器人,修改webhook-dingtalk的配置,添加webhook_ops的配置:
$ cat webhook-dingtalk-configmap.yaml
apiVersion: v1
data:
config.yml: |
targets:
webhook_dev:
url: https://oapi.dingtalk.com/robot/send?access_token=aaaaaaaaaaaaaaaaa
webhook_ops:
url: https://oapi.dingtalk.com/robot/send?access_token=bbbbbbbbbbbbbbbbb
kind: ConfigMap
metadata:
name: webhook-dingtalk-config
namespace: monitor分别更新 webhook-dingtalk、Prometheus和Alertmanager配置,查看报警的发送。
正常状态显示应该为:
1、error钉钉群只接收监控节点异常的告警
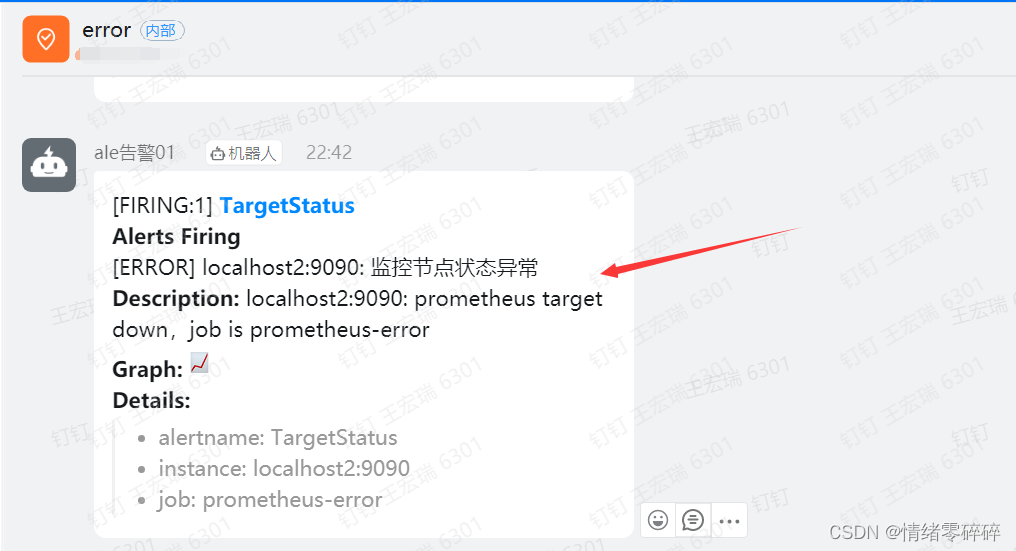
2、warning钉钉群只接收load和mem状态异常的告警
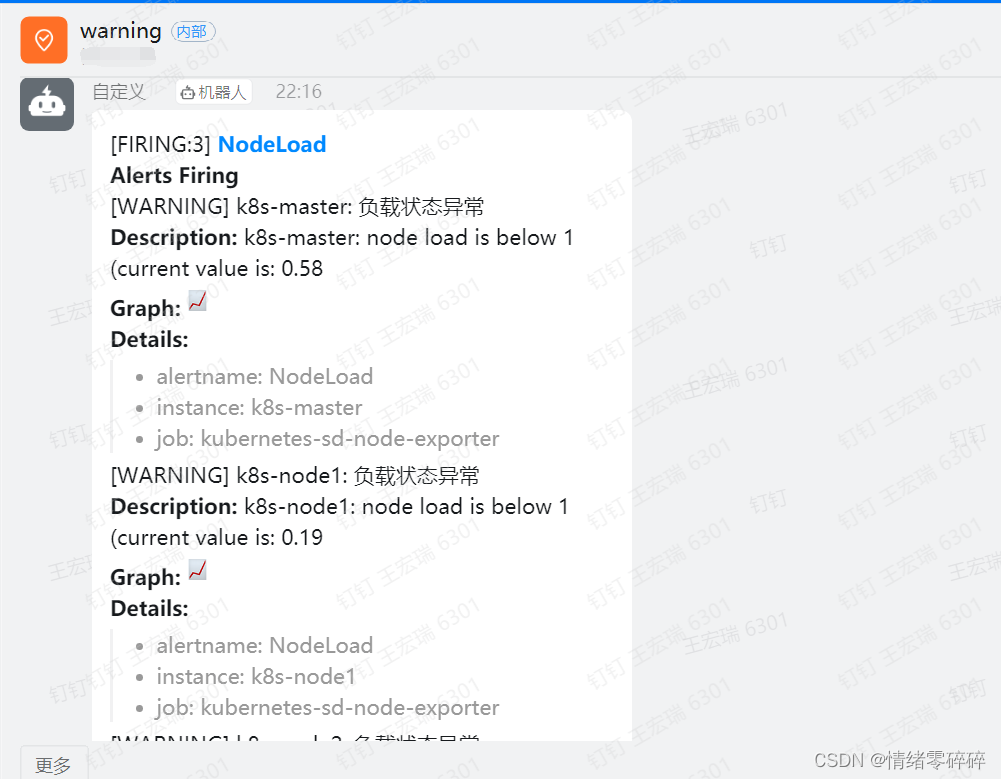
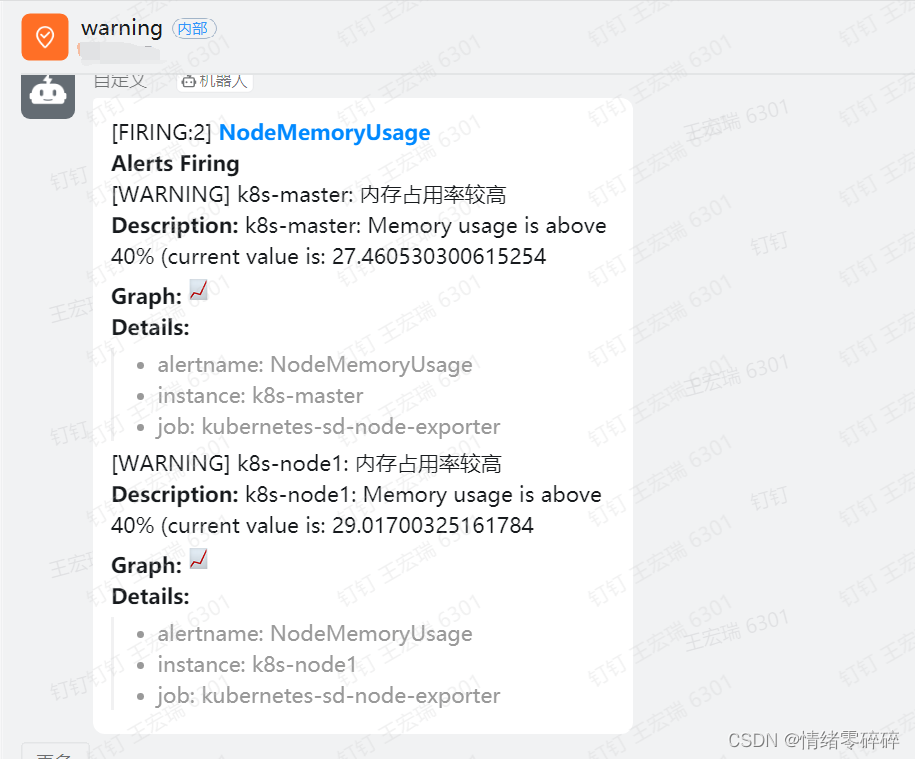
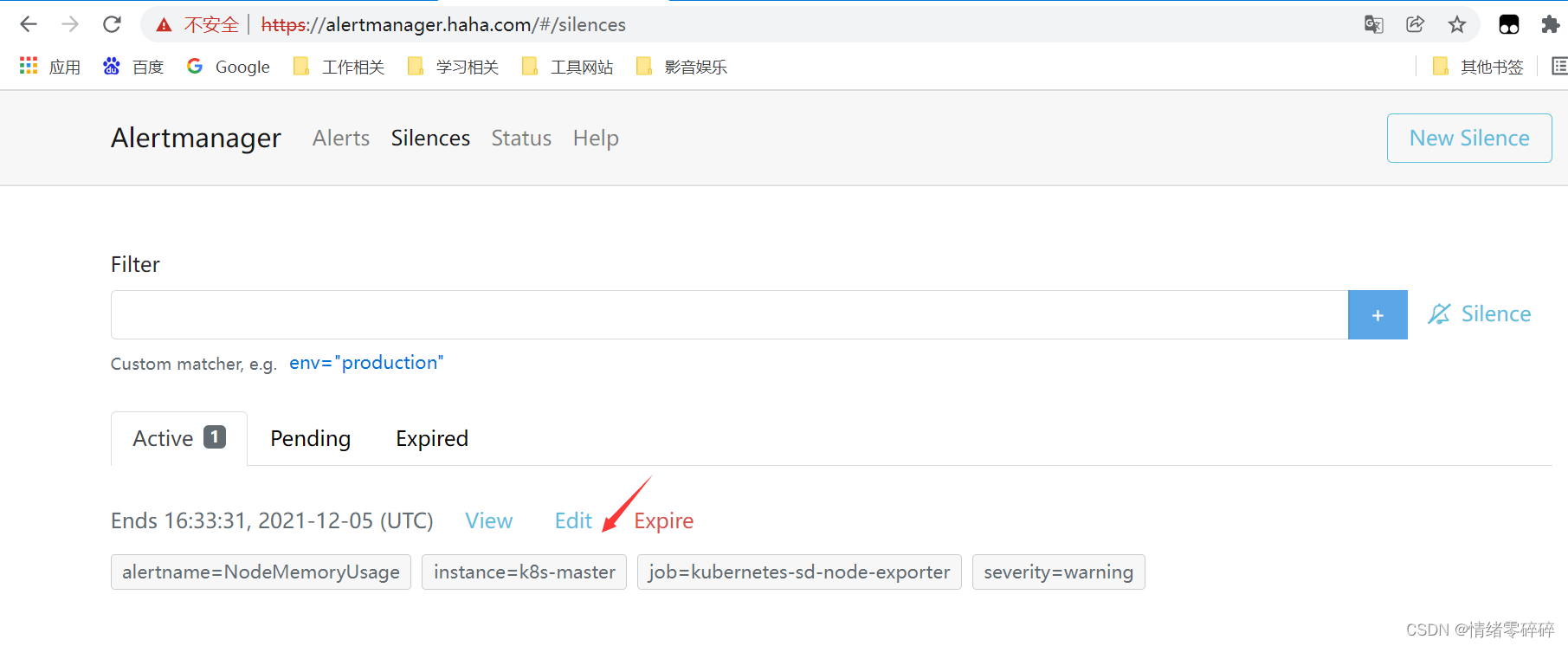
3、可以利用静默模式设定一段时间不接受某类告警
一般用于故障暂时无法处理或者系统重启时使用,设置master的mem
告警静默2小时,2小时内不会再收到此类告警




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











