





在之前的文章中介绍了NLP实际应用后,今天给大家介绍一下Python NLP相关的库。这些库可处理各种NLP任务,以及其他诸如情感分析,文本分类等任务。
Python中最著名的NLP库包括自然语言工具包(NLTK),Gensim和TextBlob。scikit-learn库还具有NLP相关功能。NLTK(http://www.nltk.org/)最初是出于教育目的而开发的,现在也广泛用于工业中。有一句话这么说的,“你不知道NLTK就说明你不懂NLP”。NLTK是用于构建基于Python的NLP应用程序的最著名最优秀的平台。我们可以通过sudo pip install -U nltk在Terminal中运行命令来安装NLTK。
NLTK带有50多个大型且结构良好的文本数据集,在NLP中称为语料库。语料库可用作单词出现的识别词典,以及模型学习和验证的训练库。一些有用且有趣的语料库包括Web文本语料库,Twitter示例,莎士比亚语料示例,情感极性,姓名语料库,Wordnet和路透社基准语料库。完整列表可在http://www.nltk.org/nltk_data中找到。在使用任何这些语料库资源之前,我们首先需要通过在Python中运行以下脚本来加载它:

将会弹出一个新窗口,询问我们要下载哪个软件包或特定语料库:

强烈建议安装popular这个软件包,因为它包含我们常用的所有重要语料库。安装软件包后,我们现在可以看一下其Names语料库:首先,导入语料库:
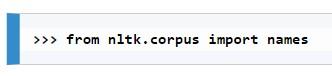
前十个names可以显示如下:

除了易于使用和丰富的语料库外,更重要的是,NLTK可以解决许多NLP和文本分析任务,其中包括:
- 分词:给定文本序列,分词是将其分成用空格分隔的片段。同时,通常会删除某些字符,例如标点符号,数字,表情符号。这些片段是用于进一步处理的所谓词。此外,在计算语言学中,由一个单词组成的词也称为unigrams,两个连续的单词组成的词称为bigrams, 三个连续的单词的trigrams和n个连续的单词称为n-grams。这在文献中经常看见,给出分词的示例如下:

- POS标记:我们可以应用现成的标记器,也可以组合多个NLTK标记器来自定义标记过程。直接使用内置的标记功能pos_tag,例如pos_tag(input_tokens)可以得到input_tokens的标记。但实际上,这实际上是来自预先构建的监督学习模型的预测。该模型基于由正确标记的单词组成的大型语料库进行训练的。
- 词干提取:词干提取是将词尾变化或派生的词还原为词根形式的过程。例如,machine是machines的词干,learn是learning和learned的词干。
Gensim:由Radim Rehurek开发的Gensim(https://radimrehurek.com/gensim/)近年来也受到欢迎。它最初设计于2008年,目的是生成给定文章的类似文章的列表,因此该库的名称为(generate similar to Gensim)。Radim Rehurek后来对其效率和可伸缩性进行了彻底的改进。同样,我们可以通过pip install --upgrade genism安装它。需确保已安装依赖项NumPy和SciPy。
Gensim以其强大的语义和主题建模算法而闻名。主题建模是发现文档中隐藏的语义结构的典型文本挖掘。普通英语的语义结构是单词出现的分布。这显然是一项无监督的学习任务。我们需要做的是输入纯文本,然后让模型找出抽象的主题。
除了强大的语义建模方法外,Gensim还提供以下功能:
- 相似性查询,检索与给定查询对象相似的对象
- 单词向量化,一种在保留单词共现特征的同时表示单词的创新方法
- 分布计算,使从数百万个文档中高效学习变得可行
TextBlob(https://textblob.readthedocs.io/en/dev/)是一个相对较新的库,建立在NLTK之上。它通过易于使用的内置函数和方法包装简化了NLP和文本分析。我们可以通过pip install -U textblob在终端中运行命令来安装TextBlob。
此外,TextBlob具有一些NLTK没有的功能,例如拼写检查和纠正、语言查询和翻译。
最后我想说的是,scikit-learn也提供了我们所需的所有文本处理功能,例如分词,以及全面的机器学习功能。
感谢您耐心看完,之后的文章会给大家介绍NLP的实例,发表这些东西的主要目的就是督促自己,希望大家关注评论指出不足,一起进步。内容我都会写的很细,并且按照文章中的代码自己也可以做出一样的结果,一个目的就是零基础也能懂,因为自己就是什么基础没有从零学Python的。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









