







python爬虫去除html中特定标签、去除注释、替换实体
前言:本文主要讲w3lib库的四个函数
html.remove_tags()
html.remove_tags_with_content()
html.remove_comments()
html.remove_entities()
文章目录
python爬虫去除html中特定标签、去除注释、替换实体
remove_tags
remove_tags_with_content
remove_comments
remove_entities
remove_tags
作用:去除或保留标签,但是仅仅是去除标签,正文部分是不做处理的
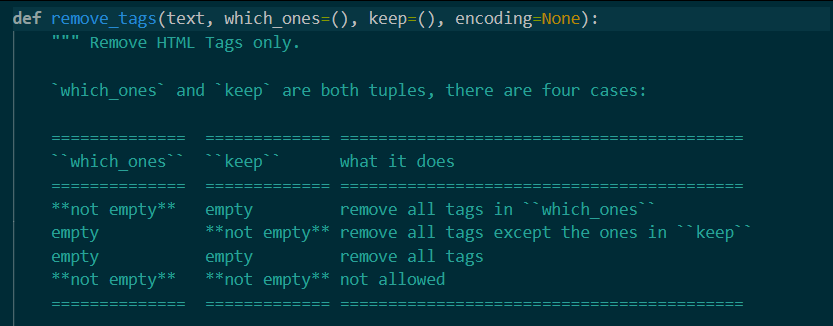
看其函数具有四个变量,
第一个是文本,即你需要传入的网页源码,必须是字符串
第二个是你要去除掉的标签,需要传入的参数类型是元组,原理是根据正则匹配去除的
第三个是你要保留的标签,需要传入的参数类型依旧是元组
第四个是编码
看备注我们可以得知,第二第三个参数总共有四种状态
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 567
567











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









