





由于个人业余时间喜欢看小说,自己又是个程序猿所以就想着从网上爬一些小说,开发一个免费的小说小程序,前期提交了几期后一切顺利,后来由于个人开发者权限不能开发小说类,所以有不少的优化功能上不了线......下面还是介绍一下开发过程吧,也算是对这次开发的一次总结。
项目预览地址:微信小程序搜索books,然后会有一个books书库的就是了,也可以扫描下面的小程序码

一、首先从前端微信小程序开发说起
1.小程序前端代码github地址:https://github.com/xml123/books
2.首先要在微信公众平台注册开发者账号,申请个人开发者资质,可以按照微信提供的文档一步一步来,这里没什么好说的
3.接下来就可以开发你的前端程序了,前端没什么难度,就是请求,渲染之类的,向后端提交数据之类的,感兴趣的可以看我的github代码,有任何问题都可以在github上提issues,我会积极回复大家。时间充裕一点后我也会回来丰富这一部分的内容的。
4.首先在微信公众平台,申请一个个人开发的小程序,获得AppID(AppID比较重要,在接下来的很多地方都将用到),然后下载一个小程序开发工具,新建项目选择小程序项目,选择代码存放的硬盘路径,填入刚刚申请到的小程序的 AppID,给你的项目起一个好听的名字,最后,勾选 "创建 QuickStart 项目" (注意: 你要选择一个空的目录才会有这个选项),点击确定,你就得到了你的第一个小程序了,点击顶部菜单编译就可以在微信开发者工具中预览你的第一个小程序。
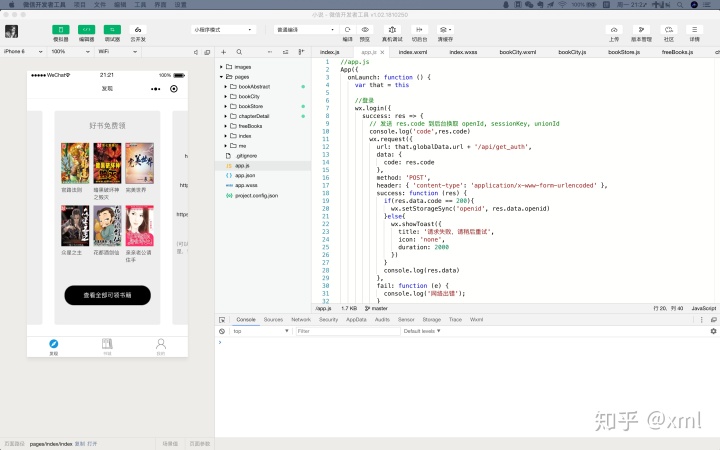
5.首先看app.json文件,这是小程序的总配置文件,可以配置小程序的顶部颜色,文字等等,可以配置底部的tabbar,配置路由等,在tabBar里配置底部tabbar,在pages数组里面配置页面,如下
{
"pages": [
"pages/index/index",
"pages/bookStore/bookStore",
"pages/me/me",
"pages/bookCity/bookCity",
"pages/bookAbstract/bookAbstract",
"pages/chapterDetail/chapterDetail",
"pages/freeBooks/freeBooks"
],
"window": {
"navigationBarBackgroundColor": "#fff",
"navigationBarTitleText": "books",
"navigationBarTextStyle": "black",
"enablePullDownRefresh": true,
"backgroundTextStyle": "dark"
},
"tabBar": {
"color": "#999999",
"selectedColor": "#222222",
"backgroundColor": "#ffffff",
"list": [
{
"pagePath": "pages/index/index",
"text": "发现",
"iconPath": "images/find.png",
"selectedIconPath": "images/find_select.png"
},
{
"pagePath": "pages/bookCity/bookCity",
"text": "书城",
"iconPath": "images/books.png",
"selectedIconPath": "images/books_select.png"
},
{
"pagePath": "pages/me/me",
"text": "我的",
"iconPath": "images/me.png",
"selectedIconPath": "images/me_select.png"
}
]
},
"networkTimeout": {
"request": 60000
}
}pages数组里面的页面需要自己在左侧pages文件夹下新建目录,然后在目录里新建page,就会自动生成路由和对应的.js、.json、.wxml、.wxss等文件。
6.然后介绍一下app.js文件,该文件中主要是配置全局的变量和一些方法,每次小程序加载时,首先会加载该文件中的生命周期函数,可以在该文件中获取授权或是获取openid等等参数,以供全局使用。
App({
onLaunch: function () {
var that = this
//登录
wx.login({
success: res => {
// 发送 res.code 到后台换取 openId, sessionKey, unionId
console.log('code',res.code)
wx.request({
url: that.globalData.url + '/api/get_auth',
data: {
code: res.code
},
method: 'POST',
header: { 'content-type': 'application/x-www-form-urlencoded' },
success: function (res) {
if(res.data.code == 200){
wx.setStorageSync('openid', res.data.openid)
}else{
wx.showToast({
title: '请求失败,请稍后重试',
icon: 'none',
duration: 2000
})
}
console.log(res.data)
},
fail: function (e) {
console.log('网络出错');
}
})
}
})
},
globalData: {
//url:'https://api2.fang88.com',//正式环境
// url:'https://apitest.fang88.com',//测试线上环境
url: 'https://api.brightness.xin',
urlImg: 'https://api.brightness.xin/static/image/',//图片前缀
// url: 'http://192.168.0.109:9000',//测试环境
// urlImg: 'http://192.168.0.109:9000/static/image/',//图片前缀
// urlImgend:'?x-oss-process=style/pic_64x64'
// urlImgend: '?x-oss-process=style/pic_100x100'
// urlImgend: '?x-oss-process=style/pic_x60'
// urlImgend: '?x-oss-process=style/index_pic'
urlImgend: '?x-oss-process=style/728_488_crop',
urlImgLayout: '?x-oss-process=style/mini_thumbnail'
// urlImgend: '?x-oss-process=style/475_680_crop'
// urlImgend: '?x-oss-process=style/640_400_crop'
}
})其中globalData中是全局变量的配置,url是自己的请求地址前缀,urlImg是图片地址前缀,剩下一些是oss相关东西,不需要的可以不用关注。然后在onLaunch函数中写了一个登录的方法,wx.login()是调用接口获取登录凭证(code)。通过凭证进而换取用户登录态信息,包括用户的唯一标识(openid)及本次登录的会话密钥(session_key)等。用户数据的加解密通讯需要依赖会话密钥完成。该方法为微信内置方法,具体使用方法可看小程序开发文档,wx.request()为小程序的请求函数,在该方法内请求自己在后端定义的接口即可。
7.对于app.wxss文件为全局的css文件,这里不再详细说明
8.下面讲一下具体的页面,以index页面为例,其他页面不再一一讲解,有问题可以评论提出来,大家一起讨论学习。
9.首先是index.json文件
{
"enablePullDownRefresh": false,
"navigationBarTitleText": "发现"
}其中enablePullDownRefresh是配置该页面是否开启当前页面的下拉刷新,默认是false,即不启用下拉刷新。navigationBarTitleText是指该页面顶部标题
10.主要看一下index.js文件,小程序的js运行机制以及使用方式有点像react和vue,都有自己的生命周期函数,以及元素渲染。
/**
* 页面的初始数据
*/
data: {
swiperIndex: 1, //当前所在轮播图索引
bannerOne:{}, //第一张banner上的内容
bannerTwo:[], //第二张banner上的内容
urlImg: getApp().globalData.urlImg, //全局使用的图片前缀
},首先是data对象,为页面的初始数据,供全局使用,也是index.wxml里动态渲染数据的来源,想要在index.wxml中使用什么数据,就要在这定义。
下面说一下小程序的几个生命周期函数吧,主要用到的有onLoad函数,页面加载时触发。一个页面只会调用一次,可以在 onLoad 的参数中获取打开当前页面路径中的参数。可以在该函数中获取在页面路径中传过来的参数,最重要的是该函数为异步加载函数,所以一定要小心使用,其中有很多坑。在index.js中,我在该函数中调用了getBannerOne()函数,getBannerOne()函数是向后端发送请求获取banner上的内容,因为banner上的内容只需要在该页面打开后加载一次,在onLoad函数中调用,如果你的请求中需要一些其他的请求后得到的参数,比如在一开始的app.js文件中获取的openid,那这里你就需要小心一些了,因为onLoad函数为异步函数,小程序打开后加载的第一个页面我定义的是index页面,此时小程序会同时加载app.js文件和index.js文件中的onLoad()函数,所以可能你在onLoad中使用的openid在app.js文件中还未获取到,就造成了错误。有两种解决方案,仅供参考。
1)如果不是一定需要在onLoad函数中加载的方法,可以放到onShow()函数中使用,该生命周期函数为同步方法,会在app.js文件加载完成后加载,会在页面显示/切入前台时触发。
2)使用es6的Promise对象方法,这里不再细说,有兴趣可以看阮一峰老师的ECMAScript 6 入门里的Promise。
然后是onReachBottom函数,是页面上拉触底的事件函数,在上拉加载更多做分页的时候经常会用到。
最最常用的便是这三个生命周期函数,其他的几个生命周期函数在用到的时候在小程序文档中查看一下使用方法即可。

(附Page 实例的生命周期图)
11.然后简单的说一下index.wxml文件吧,该文件主要是ui展示的代码了,可以在{{}}中使用index.js中data中的值,更多的可以看我的github,例
<view class="updateLi">
<image data-id="{{bannerOne.id}}" class="findImg" src="{{urlImg + bannerOne.bookImg}}" bindtap='toBook' />
<view class="bookName">{{bannerOne.title}}</view>
<view class="bookAuthor">{{bannerOne.author}}</view>
<view class="readCount">300人在读</view>
</view>12.最后吐槽一下小程序吧,坑很多,毕竟没开源,很多东西不支持,能支持的问题又很多,且行且珍惜
二、django后端技术
个人是前端出身,后来感觉python挺有意思的,所以就学了下python3,也只是学了一点皮毛而已,看了一遍Django的官网,然后就来写了这个小程序的后端,如有不对的地方,欢迎大佬指教......
1.首先还是先放上后端django的github地址:https://github.com/xml123/books_api
2.首先在电脑上安装python3和mysql,mac电脑自带python2和mysql,我项目中的版本是python@3.7.0、mysql@5.7.22
3.首先安装python的包管理工具pip,提供一个指导地址https://pip.pypa.io/en/latest/installing/#installing-with-get-pip-py
4.安装django
pip3 install Django5.搭建django工程,在指定文件夹下运行下面命令
sudo django-admin startproject booksApi
python3 manage.py runserver搭建成功后在项目根目录执行上面的第二行命令,启动成功后访问http://127.0.0.1:8000/可以看到页面信息提示,表示项目已经成功启动
注意:如果在浏览器输入 http://127.0.0.1:8000/ 后显示无法访问该网站,请检查是不是浏览器代理的问题。比如开启了某些 VPN 代理服务等,将它们全部关闭即可。
命令栏工具下按 Ctrl + c 可以退出开发服务器(按一次没用的话连续多按几次)。重新开启则再次运行python3 manage.py runserver。
6.配置数据库和django默认语言
mysql -u root -p #输入密码登录数据库
show databases; #查看已有数据库
create database books default character set utf8; #创建新数据库首先在命令行登录数据库,然后创建books数据库
#打开booksApi/booksAPi/settings.py 文件
#配置本地数据库
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.mysql',
'NAME': 'books',
'USER': 'root',
'PASSWORD': 'xxx',
'HOST': '127.0.0.1',
'PORT': '3306',
}
}打开booksApi文件夹下的settings.py文件,像上面一样配置本地数据库
#在booksApi/booksApi/settings.py文件找到下面的代码,并改成和下面的一样
LANGUAGE_CODE = 'zh-hans' #设置语言为中文
TIME_ZONE = 'Asia/Shanghai' #设置时区由于django默认语言是英文,我们改成中文,并设置时区
7.创建书籍应用
#booksApi/booksAPi/
python manage.py startapp books在项目根目录下运行上面程序创建books应用,books应用创建成功后,可以看到manage.py文件所在的目录下多了一个books文件夹
INSTALLED_APPS = [
'django.contrib.admin',
'django.contrib.auth',
'django.contrib.contenttypes',
'django.contrib.sessions',
'django.contrib.messages',
'django.contrib.staticfiles',
'books',
]然后打开booksApi文件夹下的settings.py文件,找到INSTALLED_APPS设置项,将 books 应用添加进去
8.创建models
django提供了一个抽象的模型 ("models") 层,一般来说,每一个模型都映射一个数据库表。我们可以在books文件夹下的models.py中创建自己的数据模型,我这里主要创建了分类、作者、小说、章节4个表。
9.迁移数据库
#booksApi/
python3 manage.py makemigrations
python3 manage.py migrate创建好自己的数据模型后在manage.py文件所在的目录执行上面两行命令,其中执行python3 manage.py makemigrations后,Django 在 books 应用的 migrations 目录下生成了一个 0001_initial.py 文件,这个文件是 Django 用来记录我们对模型做了哪些修改的文件。python3 manage.py migrateDjango 通过检测应用中 migrations 目录下的文件,得知我们对数据库做了哪些操作,然后它把这些操作翻译成数据库操作语言,从而把这些操作作用于真正的数据库。然后就可以从终端查看books数据库下的新建的表了。
同理我还创建了users应用,用来管理小说的用户数据
10.绑定url与视图函数
首先 Django 需要知道当用户访问不同的网址时,应该如何处理这些不同的网址(即所说的路由)。Django 的做法是把不同的网址对应的处理函数写在一个 urls.py 文件里,当用户访问某个网址时,Django 就去会这个文件里找,如果找到这个网址,就会调用和它绑定在一起的处理函数(叫做视图函数)。
下面在books文件夹下新建一个urls.py,在books/uls.py中写入以下代码
from django.urls import path
from . import views
app_name = 'books'
urlpatterns = [
path('', views.index, name='index'),
]我们首先从 django.conf.urls 导入了url函数,又从当前目录下导入了 views 模块。然后我们把网址和处理函数的关系写在了urlpatterns列表里。
注意:在项目根目录的 booksApi 目录下(即 settings.py 所在的目录),原本就有一个 urls.py 文件,这是整个工程项目的 URL 配置文件。而我们这里新建了一个 urls.py 文件,且位于 books 应用下。这个文件将用于 books 应用相关的 URL 配置。不要把两个文件搞混了。
11.编写视图函数
接下来就可以在books/view.py下编写对应的视图函数了
from django.http import HttpResponse
def index(request):
return HttpResponse("欢迎访问我的第一个小程序!")12.配置项目 URL
我们前面建立了一个 urls.py 文件,并且绑定了 URL 和视图函数index,但是 Django 并不知道。Django 匹配 URL 模式是在 booksApi 目录(即 settings.py 文件所在的目录)的 urls.py 下的,所以我们要把 books 应用下的 urls.py 文件包含到 booksApiurls.py 里去
from django.contrib import admin
from django.urls import path, include
urlpatterns = [
path('admin/', admin.site.urls),
path('', include('books.urls'))
]添加完后,再次运行python3 manage.py runserver 然后在浏览器访问http://127.0.0.1:8000/ 就可以看到自己编写的视图了......
13.编写前端请求api
同理在booksApi/books/urls.py中配置前端请求的api,如下
from django.urls import path
from . import views
app_name = 'books'
urlpatterns = [
path('api/get_all_books', views.getAllBooks, name='getAllBooks'), #查询所有书籍
path('api/get_you_like', views.getYouLike, name='getYouLike'), #猜你喜欢
path('api/get_hot_recommend', views.getHotRecommend, name='getHotRecommend'), #热门推荐
path('api/get_chapter', views.getChapter, name='getChapter'), #小说章节
path('api/get_chapter_detail', views.getChapterDetail, name='getChapterDetail'), #小说章节详情
path('api/get_abstract', views.getAbstract, name='getAbstract'), #小说简介
path('api/get_banner_one', views.getBannerOne, name='getBannerOne'), #首页banner推荐
]每一个path中方的第一个参数即为前端请求的api路径,然后在booksApi/books/view.py中编写api函数,举例如下,不再一一列出
#获取所有书籍信息
#@methord:POST
#@pageNum:页码
#@pageSize:每页数据总数
def getAllBooks(request):
if request.method == 'POST':
data_string = request.POST
try:
pageNum = data_string['pageNum']
pageSize = data_string['pageSize']
except Exception as e:
print(e)
print('获取前端传回的数据失败')
book_list = Book.objects.all().order_by('id')
paginator = Paginator(book_list, pageSize)
total = paginator.count
all_pages = paginator.num_pages
if int(pageNum) > all_pages:
books = []
else:
try:
books = paginator.page(pageNum)
except PageNotAnInteger:
books = paginator.page(1)
except EmptyPage:
books = paginator.page(paginator.num_pages)
arrayList = []
for item in books:
book_id = item.id
book_detail = Book.objects.filter(id=book_id)
arrayList.append({
'id':item.id,
'title':item.title,
'author':item.author.name, #关联表查询
'category':item.category.name,
'bookImg':item.book_img,
'abstract':book_detail[0].book_abstract
})
data = {
"code":'200',
"msg":'成功',
"data":arrayList,
"total":total
}
return HttpResponse(json.dumps(data,ensure_ascii=False), content_type="application/json", charset='utf-8',status='200',reason='success')
else:
return HttpResponse('It is not a POST request!!!')至此后端开发初步完成,当然还有很多可以优化的地方,比如添加日志、请求响应的优化等等,后期会不断优化更新......
三、python3爬虫技术
1.爬虫github地址:xml123/books_spider
2.该爬虫未使用任何框架,后期打算用scrapy框架重构一下爬虫
3.首先安装requirements.txt文件中的依赖,在终端该文件所在目录下执行
pip3 install -r requirements.txt4.该爬虫爬的是笔趣阁的书籍
http://www.biquyun.com/0_1/仔细观察书籍地址不难发现,每一本书籍都是后缀的0_1在变化,所以首先获取书籍的url
def get_level_one_url():
bigone_url_list = []
for i in range(0, 20):
if i == 0:
half_url = r'http://www.biquge.com.tw/%s_' % (i)
for j in range(1, 1000):
url = half_url + str(j)
bigone_url_list.append(url)
else:
half_url = r'http://www.biquge.com.tw/%s_%s' % (i, i)
for j in range(1, 1000):
if i == 19:
if j < 768:
url = splicing_bigone_url(half_url, j)
bigone_url_list.append(url)
else:
url = splicing_bigone_url(half_url, j)
bigone_url_list.append(url)
return bigone_url_list
# 拼接一级页面URL
def splicing_bigone_url(half_url, j):
str_num = str(j)
len_num = len(str_num)
if len_num == 1:
str_num = "00" + str_num
elif len_num == 2:
str_num = "0" + str_num
url = half_url + str_num + '/'
return url该函数返回一个书籍列表的数组,然后遍历该数组,获取每一本书籍的基础信息(作者、分类、简介等等)
5.获取到书籍后通过解析html可以得到一个该书籍的章节列表
# 获取书本的说明信息和各个章节的URL
def get_info_and_chapter_url(one_book_url):
# 本书目录信息
book_info = {}
# 得到URL的HTML文件
try:
book_html_text = get_html_text(one_book_url)
# 得到书本的url
book_info['url'] = one_book_url
# 得到书的标题
title_res = html_parser(book_html_text, '//*[@id="info"]/h1/text()')
print('booksName',title_res[0])
except:
print('解析html出错')
return
if len(title_res):
title = title_res[0]
book_info["name"] = title
else:
return
# 得到书的分类
book_kind_list = html_parser(book_html_text,
'//*[@id="wrapper"]/div[@class="box_con"]/div[@class="con_top"]/text()')
if len(book_kind_list) > 2:
book_kind = str(book_kind_list[2]).split('>')[1].replace(" ", '')
book_info["kind"] = book_kind
else:
book_info['kind'] = ''
# 得到书的简介
book_abstract = html_parser(book_html_text, '//*[@id="intro"]/p[1]/text()')
if len(book_abstract):
book_info["abstract"] = book_abstract[0]
else:
book_info["abstract"] = ''
# 得到书本的封面图
book_img_list = html_parser(book_html_text, '//*[@id="fmimg"]/img/@src')
if len(book_img_list):
book_half_img = book_img_list[0]
# print('name',name)
print('book_half_img',book_half_img)
# book_img = r"http://www.biquge.com.tw" + book_half_img
# 将远程图片下载到本地,第二个参数就是要保存到本地的文件名
#book_img = book_half_img
book_info["img"] = book_half_img
else:
book_info['img'] = ''
# 得到书本的作者信息
book_author_list = html_parser(book_html_text, '//*[@id="info"]/p[1]/text()')
if len(book_author_list):
book_author_str = str(book_author_list[0]).split(":")[1]
book_info['author'] = book_author_str
else:
book_info['author'] = ''
# 得到文章章节链接和章节名
chapter_list = []
chapter_nodes = html_parser(book_html_text, '//*[@id="list"]/dl/dd/a')
for one in chapter_nodes:
tmp = {}
# 得到章节节点的标题
chapter_name_res = one.xpath("text()")
if len(chapter_name_res):
chapter_name = chapter_name_res[0]
tmp["chapter_name"] = chapter_name
# 得到章节的url
chapter_href_res = one.xpath("@href")
if len(chapter_href_res):
chapter_href = r"http://www.biquge.com.tw" + chapter_href_res[0]
tmp["chapter_href"] = chapter_href
chapter_list.append(tmp)
# 重新组合信息
book_info['chapter'] = chapter_list
return book_info通过不断遍历章节列表来获取每一章节信息,存入数据库。
6.该爬虫是使用基础python3语法写的,上面有详细的注释,这里不再一一详细讲解,有任何问题,欢迎评论一起交流学习。















 4168
4168

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









