





【熔断器Spring Cloud Hystrix】
主要内容
- 什么是灾难性的雪崩效应
- 如何解决灾难性雪崩效应
- Hystrix简介
- 降级
- 熔断
- 请求缓存
- 请求合并
- Hystrix-dashboard
- Feign的降级处理
一、什么是灾难性的雪崩效应

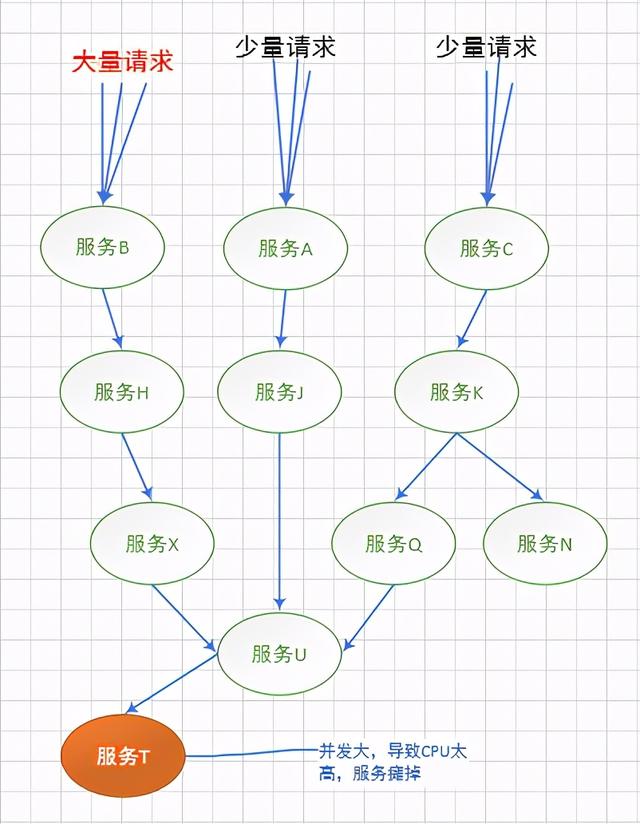
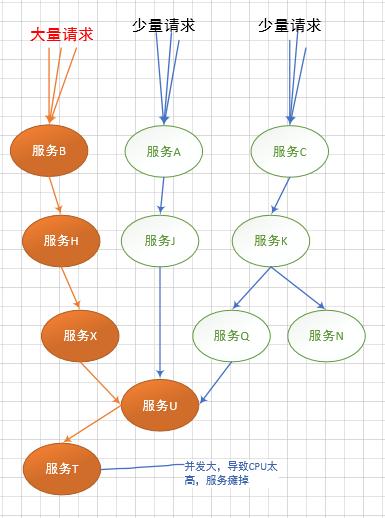
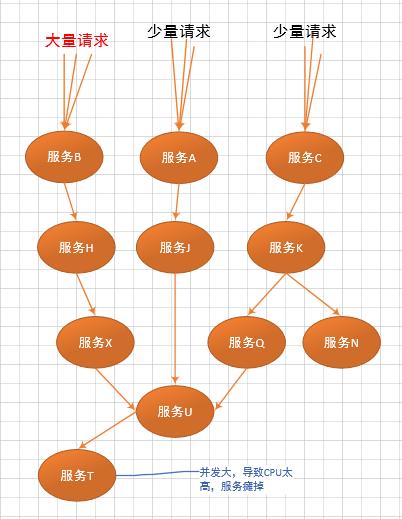
造成灾难性雪崩效应的原因,可以简单归结为下述三种:
- 服务提供者(Application Service)不可用。如:硬件故障、程序BUG、缓存击穿、并发请求量过大等。
- 重试加大流量。如:用户重试、代码重试逻辑等。
- 服务调用者(Application Client)不可用。如:同步请求阻塞造成的资源耗尽等。
雪崩效应最终的结果就是:服务链条中的某一个服务不可用,导致一系列的服务不可用,最终造成服务逻辑崩溃。这种问题造成的后果,往往是无法预料的。
解决灾难性雪崩效应的方式通常有:降级、熔断和请求缓存、请求合并。
二、如何解决灾难性雪崩效应
降级
超时降级、资源不足时(线程或信号量)降级,降级后可以配合降级接口返回托底数据。实现一个fallback方法, 当请求后端服务出现异常的时候, 可以使用fallback方法返回的值.
保证:服务出现问题整个项目还可以继续运行。
熔断
当失败率(如因网络故障/超时造成的失败率高)达到阀值自动触发降级,熔断器触发的快速失败会进行快速恢复。
通俗理解:熔断就是具有特定条件的降级。所以在代码上熔断和降级都是一个注解
保证:服务出现问题整个项目还可以继续运行。
缓存
提供了请求缓存。服务A调用服务B,如果在A中添加请求缓存,第一次请求后走缓存了,就不在访问服务B了,即使出现大量请求时,也不会对B产生高负载。
请求缓存可以使用Spring Cache实现。
保证:减少对Application Service的调用。
请求合并
提供请求合并。当服务A调用服务B时,设定在5毫秒内所有请求合并到一起,对于服务B的负载就会大大减少,解决了对于服务B负载激增的问题。
保证:减少对Application Service的调用。
三、Hystrix简介
Hystrix [hɪst'rɪks],中文含义是豪猪,因其背上长满棘刺,从而拥有了自我保护的能力。本文所说的Hystrix是Netflix开源的一款容错框架,同样具有自我保护能力。为了实现容错和自我保护。
在Spring cloud中处理服务雪崩效应,都需要依赖hystrix组件。在Application Client应用的pom文件中都需要引入下述依赖:

四、降级
降级是指,当请求超时、资源不足等情况发生时进行服务降级处理,不调用真实服务逻辑,而是使用快速失败(fallback)方式直接返回一个托底数据,保证服务链条的完整,避免服务雪崩。
解决服务雪崩效应,都是避免application client请求application service时,出现服务调用错误或网络问题。处理手法都是在application client中实现。我们需要在application client相关工程中导入hystrix依赖信息。并在对应的启动类上增加新的注解@EnableCircuitBreaker,这个注解是用于开启hystrix熔断器的,简言之,就是让代码中的hystrix相关注解生效。
1. 新建ApplicationServiceDemo
1.1 配置pom.xml

1.2 新建配置文件
新建application.yml

1.3 新建控制器
新建com.bjsxt.controller.DemoController

1.4 新建启动类
新建com.bjsxt.DemoApplication

2. 新建DemoFallback
新建项目DemoFallback作为Application Client
2.1 编写pom.xml

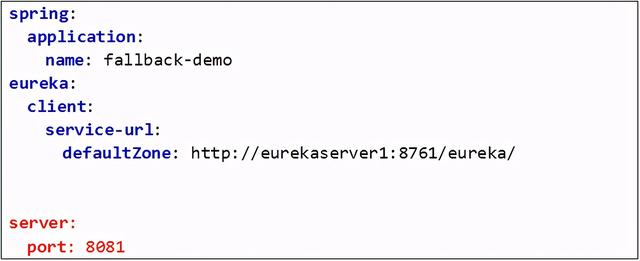
2.2 新建配置文件
新建application.yml
注意不要端口号冲突
2.3 新建配置类
新建com.bjsxt.config.RibbonConfig
此处使用@LoadBalancer方式快捷配置负载均衡。

2.4 新建service及实现类
新建com.bjsxt.service.DemoService及实现类。
实现类中@HystrixCommand的fallbackMethod配置的就是降级方法。
myFallback方法:
参数:和test的参数是相同的。
返回值:和test中调用的application-service-demo/demo控制器方法返回值相同


2.5 新建控制器
新建com.bjsxt.controller.FallbackController

2.6 新建启动类
2.7 访问
在浏览器输入http://localhost:8081/demo

3. 测试降级
停止ApplicationServiceDemo项目。再次访问

五、熔断
当一定时间内,异常请求比例(请求超时、网络故障、服务异常等)达到阀值时,启动熔断器,熔断器一旦启动,则会停止调用具体服务逻辑,通过fallback快速返回托底数据,保证服务链的完整。
熔断有自动恢复机制,如:当熔断器启动后,每隔5秒,尝试将新的请求发送给Application Service,如果服务可正常执行并返回结果,则关闭熔断器,服务恢复。如果仍旧调用失败,则继续返回托底数据,熔断器持续开启状态。
降级是出错了返回托底数据,而熔断是出错后如果开启了熔断将会一定时间不在访问application service
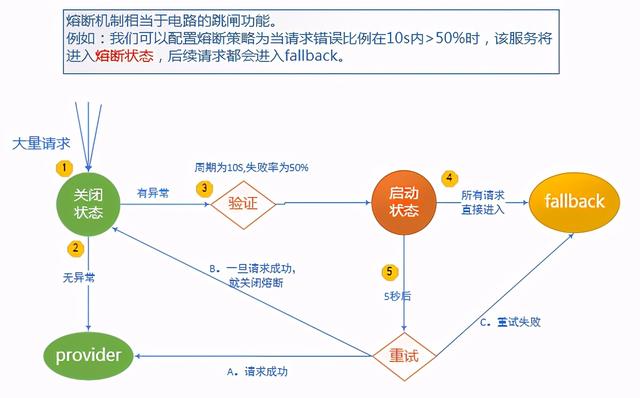
1. 属性
熔断的实现是在调用远程服务的方法上增加@HystrixCommand注解。当注解配置满足则开启或关闭熔断器。
@HystrixProperty的name属性取值可以使用HystrixPropertiesManager常量,也可以直接使用字符串进行操作。
注解属性描述:
CIRCUIT_BREAKER_ENABLED
"circuitBreaker.enabled";
是否开启熔断策略。默认值为true。
CIRCUIT_BREAKER_REQUEST_VOLUME_THRESHOLD
"circuitBreaker.requestVolumeThreshold";
单位时间内(默认10s内),请求超时数超出则触发熔断策略。默认值为20次请求数。
EXECUTION_ISOLATION_THREAD_TIMEOUT_IN_MILLISECONDS
execution.isolation.thread.timeoutInMilliseconds
设置单位时间,判断circuitBreaker.requestVolumeThreshold的时间单位,默认10秒。单位毫秒。
CIRCUIT_BREAKER_SLEEP_WINDOW_IN_MILLISECONDS
"circuitBreaker.sleepWindowInMilliseconds";
当熔断策略开启后,延迟多久尝试再次请求远程服务。默认为5秒。单位毫秒。这5秒直接执行fallback方法,不在请求远程application service。
CIRCUIT_BREAKER_ERROR_THRESHOLD_PERCENTAGE
"circuitBreaker.errorThresholdPercentage";
单位时间内,出现错误的请求百分比达到限制,则触发熔断策略。默认为50%。
CIRCUIT_BREAKER_FORCE_OPEN
"circuitBreaker.forceOpen";
是否强制开启熔断策略。即所有请求都返回fallback托底数据。默认为false。
CIRCUIT_BREAKER_FORCE_CLOSED
"circuitBreaker.forceClosed";
是否强制关闭熔断策略。即所有请求一定调用远程服务。默认为false。
2. 代码示例
在原有降级代码上修改@HystrixCommand如下。
关闭ApplicationSeviceDemo项目,访问DemoFallback控制器,刷新5次后会发现页面加载快了,这时就开启熔断了。此时打开ApplicationServiceDemo,发现依然返回托底数据。到达30秒后再次访问才能正常访问ApplicationServiceDemo中内容。
注意:单位时间时间内容请求数必须达到5个(无论成功还是失败)才能满足条件。

海量Java学习资料,大厂面试题,项目练习题,统统免费提供,只要关注,那就会有收获~笔芯~














 743
743











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









