






Dig101: dig more, simplified more and know more
string 这么简单,我想你也一直是这样想的,没关系,我也没打算把它搞复杂。
别着急,我们先从 string 的拼接操作 + 开始
文章目录
0x01 string 对 "+" 拼接的优化
0x02 string 也是一种切片
0x03 string 不能修改
0x04 string 和[]byte,[]rune 的相互转化
rune => string
byte => string
string => rune
string => byte
0x05 零拷贝实现[]byte 转 string
0x06 string 的拼接效率
0x01 string 对 "+" 拼接的优化
如下代码, s2, s3, s4 具体执行时有啥不同
s1 := "x"
s2 := s1 + "y" + "x" + "z"
s3 := s1 + "y" + s1 + "z" + s1
s4 := s1 + "y" + s1 + "z" + s1 + "z"
println(s2, s3, s4)
乍一看都是字符串拼接感觉没啥不同,但是当我们用go tool compile -m来打印编译优化时发现
字面量拼接会在编译时就合并到一起"y" + "x" + "z" => "xyz"
$ go tool compile -m plus.go
plus.go:21:6: can inline plus
plus.go:23:11: s1 + "yxz" does not escape
plus.go:24:28: s1 + "y" + s1 + "z" + s1 does not escape
plus.go:25:33: s1 + "y" + s1 + "z" + s1 + "z" does not escape
再使用-S打印汇编调用 concat 相关
$ go tool compile -S plus.go|grep concat
0x0068 00104 (plus.go:20) CALL runtime.concatstring2(SB)
0x00eb 00235 (plus.go:21) CALL runtime.concatstring5(SB)
0x01e1 00481 (plus.go:22) CALL runtime.concatstrings(SB)
rel 105+4 t=8 runtime.concatstring2+0
rel 236+4 t=8 runtime.concatstring5+0
rel 482+4 t=8 runtime.concatstrings+0
发现这三个拼接调用了不同的 concatstring 方法
其实当string相加是:
- 编译器先优化掉字面量拼接后
- 再将剩余待拼接
string作为一个切片参数传入concatstring相关函数- 当切片长度为 2-5 之间则调用数组参数的
concatstring2-concatstring5 - 否则调用切片参数的
concatstrings
- 当切片长度为 2-5 之间则调用数组参数的
- 如果所有待拼接
string总长度小于 32, 则会初始化一个栈上的tmpBuf,来避免堆上内存分配。
具体代码调用点如下,感兴趣可以自行查看下
// cmd/compile/internal/gc/walk.go 中 addstr
// 调用 runtime/string.go 中 concatstrings
// tmpBuf用来拼接处理过程中优化分配小字符串对象
const tmpStringBufSize = 32
type tmpBuf [tmpStringBufSize]byte
func concatstrings(buf *tmpBuf, a []string) stringfunc concatstring2(buf *tmpBuf, a [2]string) string
...0x02 string 也是一种切片
如果你查看过concatstrings的内部调用,你会发现有切片的操作
func concatstrings(buf *tmpBuf, a []string) string
...s, b := rawstringtmp(buf, l)for _, x := range a {
copy(b, x)
b = b[len(x):]
}
...
}
//具体看内部 rawstring 方法,你能发现 b 从何而来
func rawstringtmp(buf *tmpBuf, l int) (s string, b []byte) {
if buf != nil && l <= len(buf) {
b = buf[:l]
s = slicebytetostringtmp(b)
} else {
s, b = rawstring(l)
}
return
}
type stringStruct struct {
str unsafe.Pointer
len int
}
func rawstring(size int) (s string, b []byte) {
p := mallocgc(uintptr(size), nil, false)
stringStructOf(&s).str = p
stringStructOf(&s).len = size
// 这里的 slice 有没有熟悉的感觉
*(*slice)(unsafe.Pointer(&b)) = slice{p, size, size}
return
}
重点就是*(*slice)(unsafe.Pointer(&b)) = slice{p, size, size}
所以 string 底层不过是cap和len一样的[]byte罢了
0x03 string 不能修改
s:="abc"
// 可以换底层数据
s="xyz"
// 不能直接修改底层数据
s[0]='b'
// Error: cannot assign to s[0]
那一般怎么改局部字符呢, 有两类利用[]byte和[]rune
s := "abc好"
// 1.替换byte
bs := []byte(s)
bs[0] = 'x'
println(string(bs))
// 2.替换中文
rs := []rune(s)
rs[3] = '啊'
println(string(rs))
0x04 string 和[]byte,[]rune 的相互转化
那么对于上边的转化,我们可以依次分析一下,会有一些有趣的地方
rune => string
每个 rune 底层是int32,是用来 utf8 字符表示的编码点(Unicode code point),4 个 byte(uint8)大小
转化前内部先开辟[]byte, 再调用 func encoderune(p []byte, r rune)判断r底层的[]byte大小, 依次实现拷贝写入。
这里如果你仔细查看encoderune函数, 诸如 _ = p[1],_ = p[2] ...
其实是一种边界检查的优化:消除边界检查[1]。感兴趣的同学可以自行查看
byte => string
直接基于[]byte的首地址和长度构造string结构体,并拷贝内容到数据指向
string => rune
直接开辟[]rune, 遍历string为[]rune赋值
因为 string 遍历等价于对[]rune(string)的遍历
另外 string 不可修改,所以转换中不需要检测数据竞争(race detect)
string => byte
直接开辟[]byte, 利用copy([]byte, string)拷贝
0x05 零拷贝实现[]byte 转 string
上边的转化方式都有拷贝,有一种不需要拷贝就可以将[]byte转为string出现在如下函数
// 有些编译器会对以下操作中的转string使用优化
// - m[T1{... Tn{..., string(k), ...} ...}] and m[string(k)]
// - ""
// - string(b)=="foo"
func slicebytetostringtmp(b []byte) string {
...
return *(*string)(unsafe.Pointer(&b))
}
原理就是利用 string 底层是[]byte,所以直接做指针转换。
但是有注意点,转换后不能修改,否则 string 不可被修改的原则就被破坏了。属于特定使用场景了。
string拼接类库strings.Builder的String方法就利用这一点零拷贝优化转化速度
0x06 string 的拼接效率
针对长(long: 256b)、短string(short: 16b)在少量和大量拼接的 benchmark,代码见concat_benchmark[2]
对于sprint和sprintf和strings.Join压测代码都是提前构建好全部待拼接 string 列表 其他三个是遍历拼接
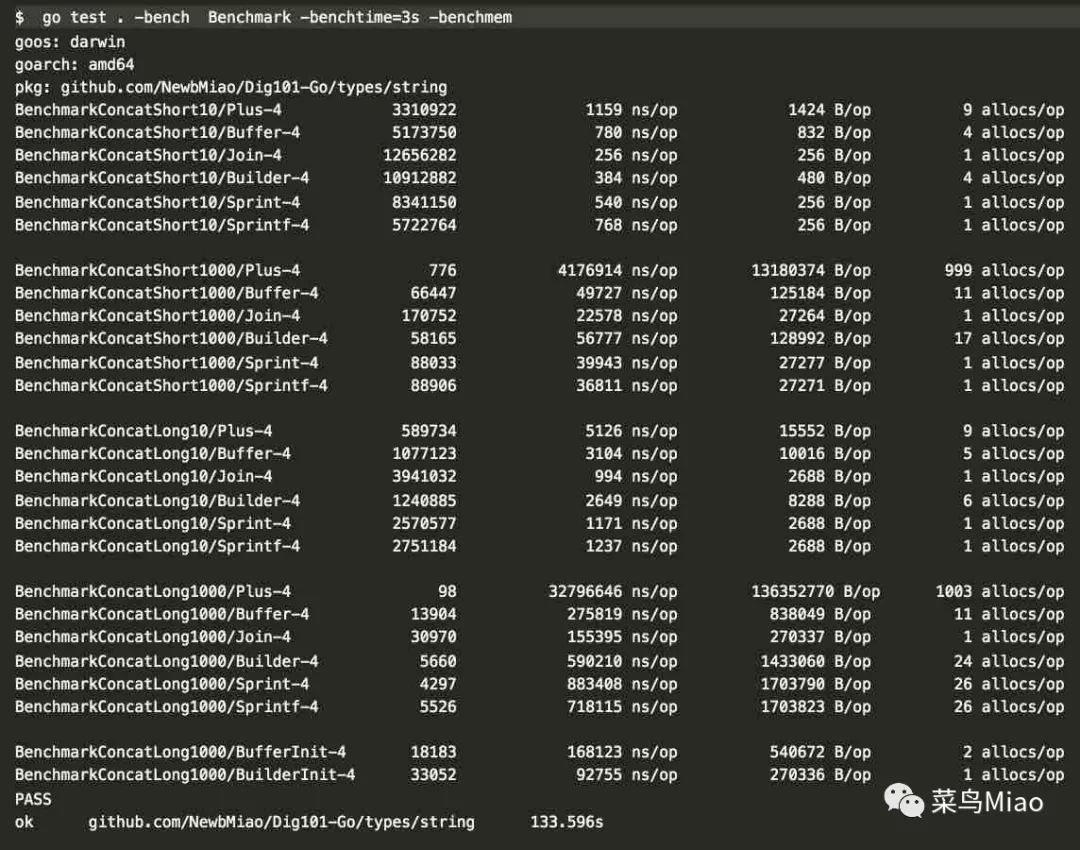
压测结果分析如下:
提前构造好参数情况下
sprint和sprintf差别不大strings.Join效率最佳(其底层使用strings.Builder这个我们后边对比时再讲)
遍历拼接情况下
+性能差距会越来越大- 少量拼接次数下:
strings.Builder比bytes.Buffer快, 大量了就不行了
可是官方宣称strings.Builder在结果为 string 情况下效率更好啊。
仔细看我们发现strings.Builder对应的每次操作 alloc 数比 buffer 的多很多,可能是内存分配过多影响了效率。查看压测代码,都是遍历前bf.Reset()重置。
再看源码
// Reset resets the buffer to be empty,
// but it retains the underlying storage for use by future writes.
// Reset is the same as Truncate(0).
func (b *Buffer) Reset() {
b.buf = b.buf[:0]
b.off = 0
b.lastRead = opInvalid
}
// Reset resets the Builder to be empty.
func (b *Builder) Reset() {
b.addr = nil
b.buf = nil
}
原来Buffer只是将大小设置为 0,没清空内容,而Builder直接清空了内容
也对,Builder利用了零拷贝优化转化 string 的效率,是不允许修改的。
这也是为啥其内部写操作之前会调用b.copyCheck()去检测是否存在拷贝。
除此之外,其实Buffer和Builder还有优化的空间:就是减少内存分配次数
他们底层都使用了[]byte,且都有Grow(size int)方法,避免多次内存不够去reslice扩容, 详见代码:concatIterWithGrowInit
如此优化后,benchmark 的数据能和官方说的对上了,Builder变快了,而且他们每次操作的 alloc 次数都变成了 1.

好了,就到这里,希望我没把它搞复杂。
参考资料
[1]消除边界检查: https://go101.org/article/bounds-check-elimination.html
[2]concat_benchmark: https://github.com/NewbMiao/Dig101-Go/blob/master/types/string/concat_test.go
推荐阅读
深挖Go系列之灵活的slice
喜欢本文的朋友,欢迎关注“Go语言中文网”:

Go语言中文网启用微信学习交流群,欢迎加微信:274768166,投稿亦欢迎














 1247
1247











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









