





需求:kettle抽取线上数据到另外一个数据库实例(目标数据源),然后用帆软(finereport)拉取展示目标数据的数据,原则上报表一般不允许拉取线上数据库,防止大批量数据导致线上实例报警影响现网业务。
现存问题:线上正常企业,共6000+企业的数据(非正常企业6万多家,冻结数据等等),包括已经付费的企业。现存问题,拉取数据缓慢,经百度和同事等等一系列的咨询,以及观察kettle日志得知 job是串行的 一个企业运行完之后才会运行另外一个企业,所以服务器上运行的速度极其缓慢,定时任务开启每天晚上0晨执行,结果9个多小时,只运行了600多家企业,被领导喷的体无完肤。。。。
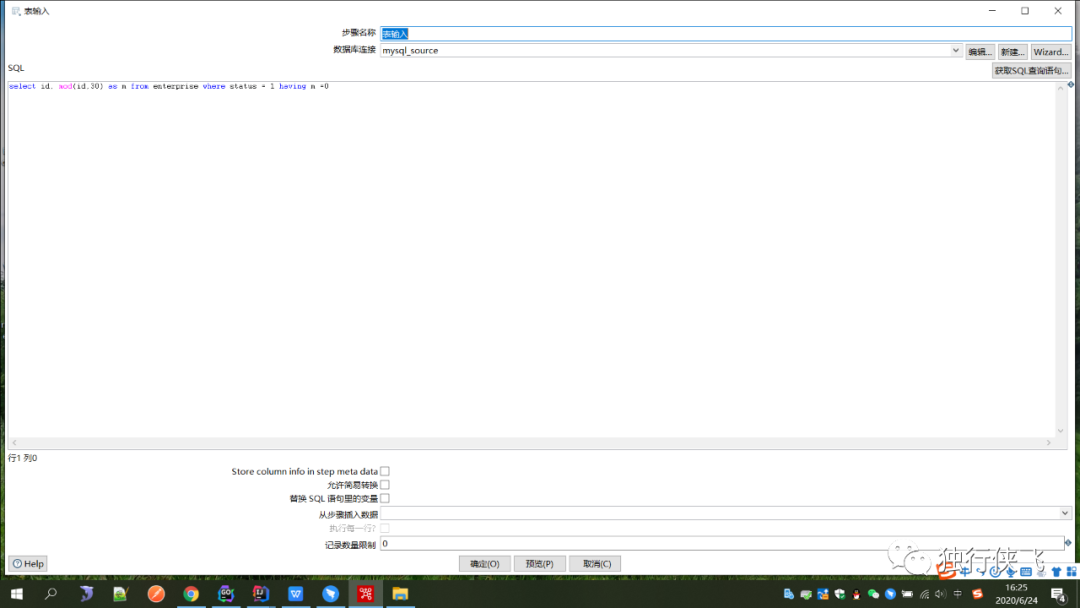
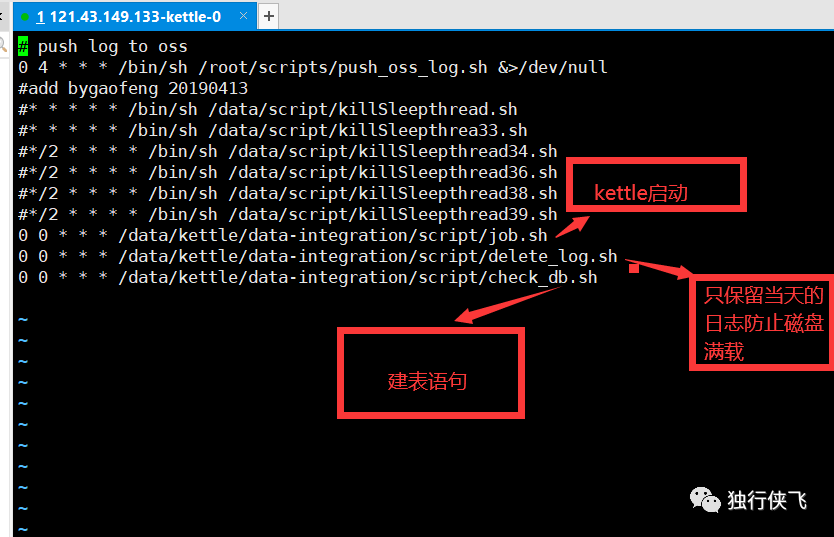
对应的解决方案:对企业做分片处理 以及kettle并发执行对企业表的id对30取模,这样就能均匀的讲企业数据分散为30个数据段,对30个数据段做并发处理,也就是启动30个线程并发同时执行,服务器取三台,每台服务器上跑10条线如图所示。
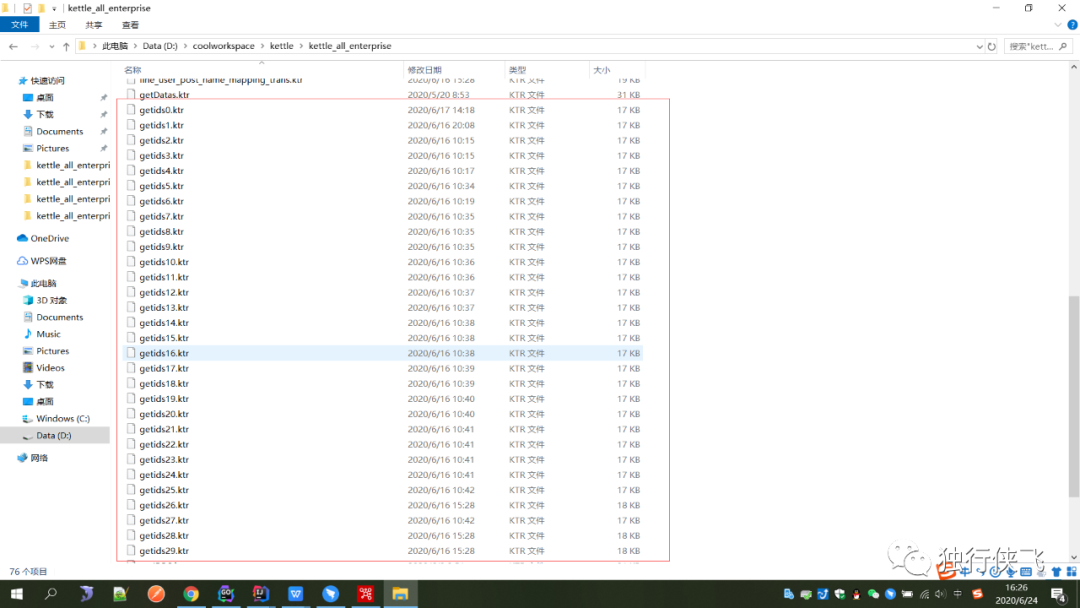
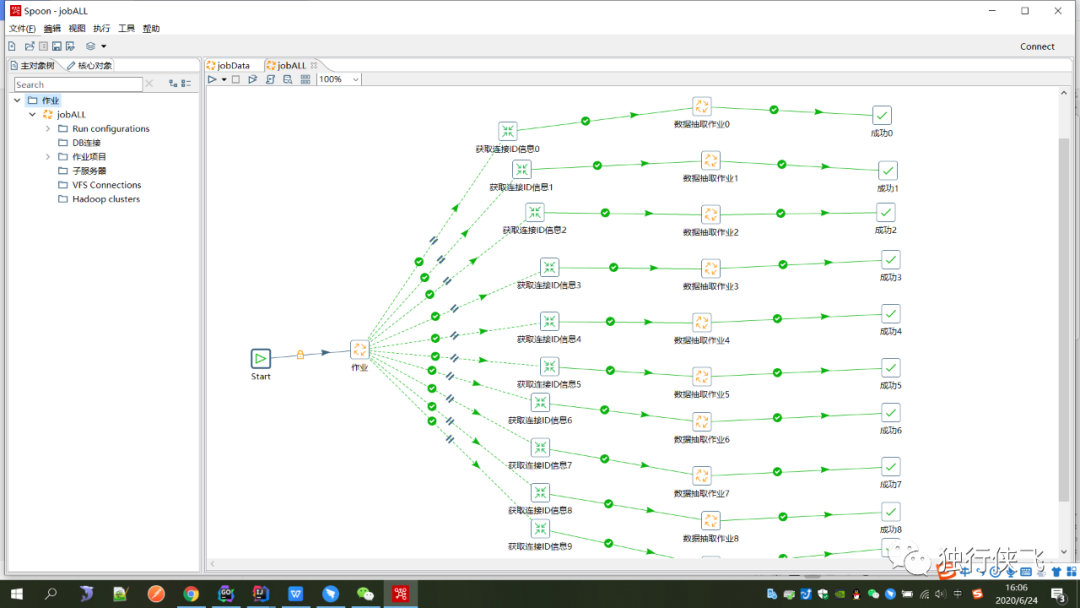
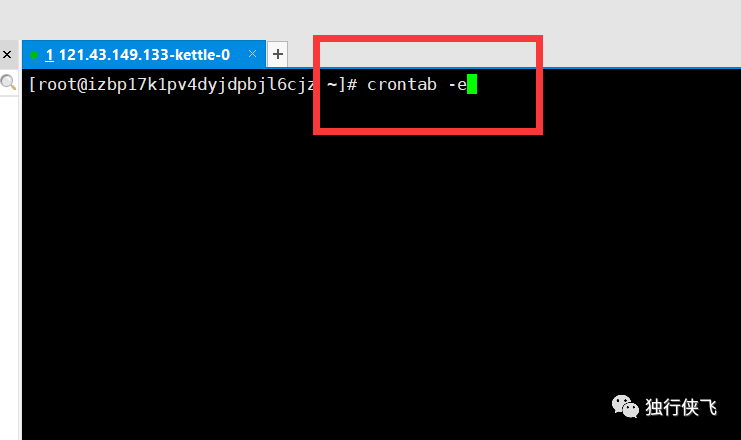
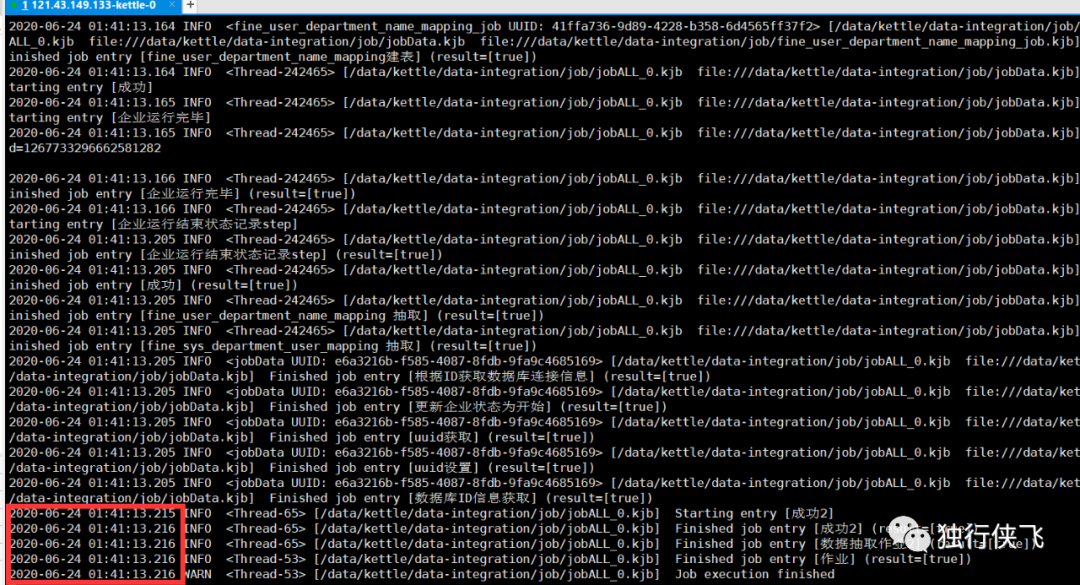
每天晚上0晨任务启动,观察日志基本都是运行2个小时不到,数据就能全部运行完毕。linux定时任务:使用crontab 将启动命令放入即可。
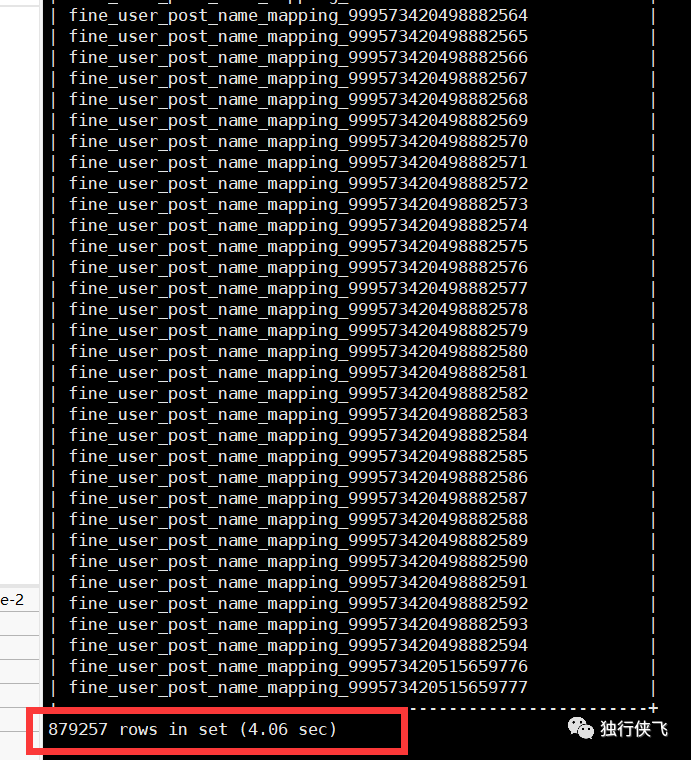
对目标数据源的监控共87万左右张表(show tables)
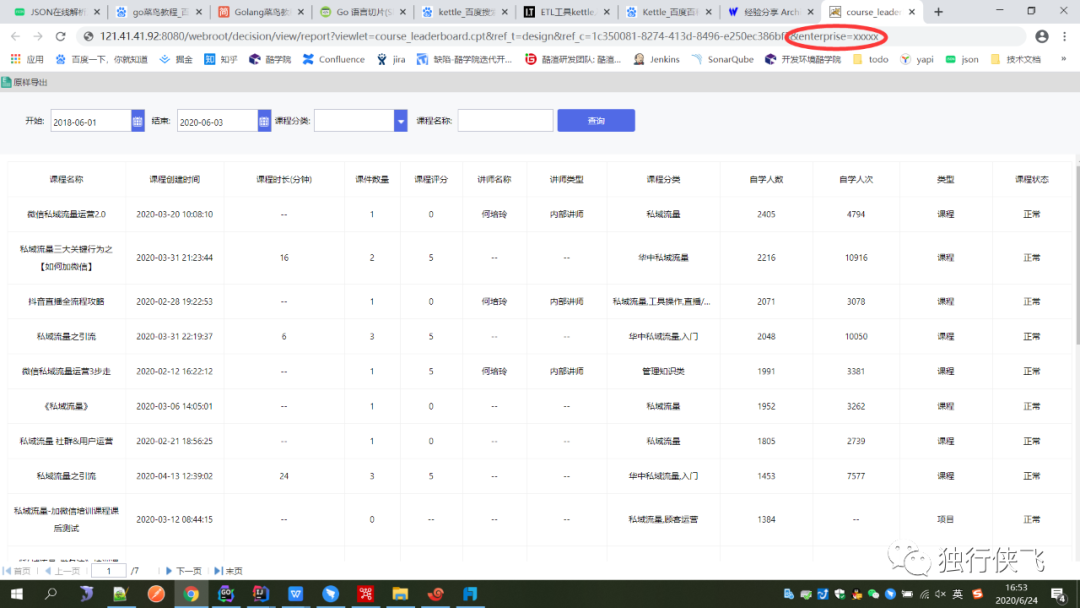
最后一步 帆软展示需要动态传参 只需要在浏览器中拼接参数即可
 最后一张长屏图结尾
最后一张长屏图结尾















 2092
2092











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









