






方差分析(Analysis of Variance,ANOVA)就是用于检验两组或两组以上的均值是否具有显著性差异的数理统计方法。有单因素方差分析和多因素方差分析。
1 基本原理
在方差分析中,把要分析的变量称为响应变量,对响应变量取值有影响的其它变量称为因素,因素的不同取值称为水平。
1.1 方差分析的模型
以一个单因素的例子进行分析。

四种用于缓解手术后疼痛的药品,研究它们的治疗效果是否存在显著性差异。
分析:
将每一种药品的治疗效果当作一个总体,我们要检验四个总体的均值是否相等,记四个总体的均值为
以符号表示为:
其中
其中
1.2 方差分析的基本思想
所有样本响应变量的方差称为全部平方和(Total Sum of Squares,
我们将由因素不同水平间差异引起的、可以由模型中因素解释的部分方差称为模型平方和(Model Sum of Squares,
其中,
即 全部平方和=模型平方和+误差平方和
~~~每个观测与所有样本均值计算的方差和=每一水平均值*这一水平下的观测数目与所有样本均值的方差和+每个观测与对应的水平均值计算的方差和。~~~
在方差分析中,如果由因素不同水平引起的差异占显著比例,那么可以推断该因素对响应变量的差异具有显著作用。如果抽样过程本身引起的差异占显著比例,那么可以推断该因素对响应变量的差异不具有显著作用,用F来衡量。
其中,s为水平个数,n为所有水平下样本容量的总和;(s-1)为模型的自由度,(n-s)为误差自由度的自由度。上式中分子分母分别称为模型均方和误差均方。
R方用于衡量模型能解释响应变量方差比例的大小,取值在(0,1),值越大意味着能解释的比例越大,模型对数据拟合的越好。反之,趋近于0,模型几乎不能解释响应变量方差。
方差分析步骤:
1)建立原假设和备择假设;
2)给定显著性水平
3)计算F统计量的值
4)根据(s-1)和(n-s)确定一个F分布,有F分布的概率密度函数和
5)
1.3 方差分析的假设
- 每组观测服从正态分布
- 每组观测的方差相等,即方差齐性
- 观测间独立
2 单因素试验的方差分析
2.1 TTEST过程、ANOVA过程和GLM过程区别
方差分析可以通过PROC TTEST、PROC ANOVA、PROC GLM实现。具体采用哪一个过程步,可参考以下场景。
1)单因素两水平,三者的计算结果一致。
2)单因素,水平数
3)因素的个数
2.2 使用ANOVA进行方差分析
语法如下:
PROC ANOVA <选项>;
class 变量;
model 响应变量=因素;
by 变量;
means 因素;
run;<选项> 包括data= 指定输入数据集,outstat=知道输出数据集,plots 要求ODS图像选项是打开的。
class 必须在model语句之前,指定用于方差分析模型的分类变量。
model 指定用于方差分析的因素和响应变量
by ,anova会对by语句中的每一个变量进行分析,by必须提前作升序排序。
例如拿上面提到的缓解手术后疼痛的药品的例子:
data relifeTime;
input medicine $ hours @@;
datalines;
A 7 A 5 A 3 A 1
B 6 B 5 B 3 B 3
C 7 C 9 C 9 C 9
D 4 D 3 D 4 D 3
;
run;
proc anova data=relifeTime;
class medicine;
model hours=medicine;
run;
因素药品水平为4,总观测值为16.
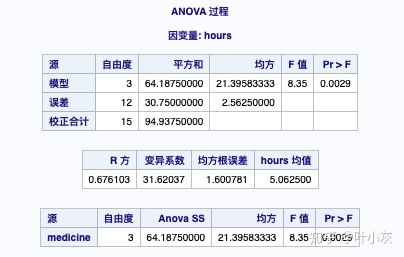
模型自由度=3,校正合计自由度为15,误差自由度为12。F值为8.35,具有显著性。p值为0.0029,拒绝原假设。我们可以认为,4款药品在延缓手术后疼痛的时间上具有显著性差异。
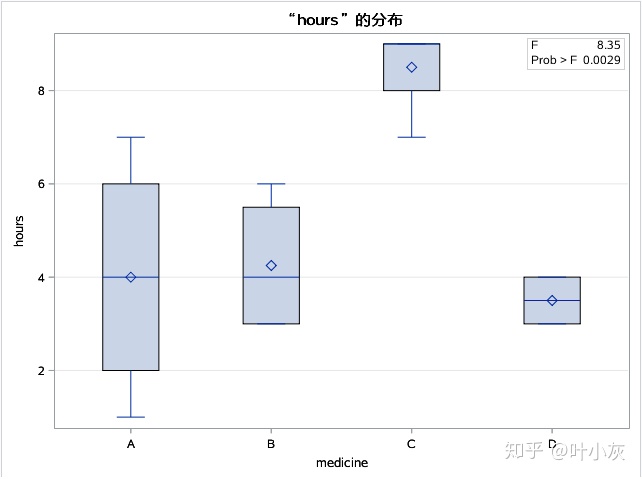
2.3 使用GLM过程进行方差分析
在ANOVA分析中,我们是假设3个条件是满足的。但实际是需要我们去验证的。我们现在假设每个病人术后延缓疼痛的时间相互独立,可以利用GLM过程对其余两个假设进行检验。
GLM不仅可以用来进行方差分析,还可以进行多元回归分析、协方差分析多项式回归等。
PROC GLM <选项>;
class 变量;
model 响应变量=因素;
LSMEANS;
means 因素;
run;其中,选项有alpha=、data=、outstat=、plots=。
LSMEANS:指定变量的最小二乘均值。
例子:
libname ex 'F:SASnote';
data ex.relifeTime;
input medicine $ hours @@;
datalines;
A 7 A 5 A 3 A 1
B 6 B 5 B 3 B 3
C 7 C 9 C 9 C 9
D 4 D 3 D 4 D 3
;
run;
ods graphics on;
proc glm data=ex.relifeTime plots(only)=diagnostics;
class Medicine;
model Hours=Medicine;
means Medicine /hovtest;
run;
quit;
ods graphics off;
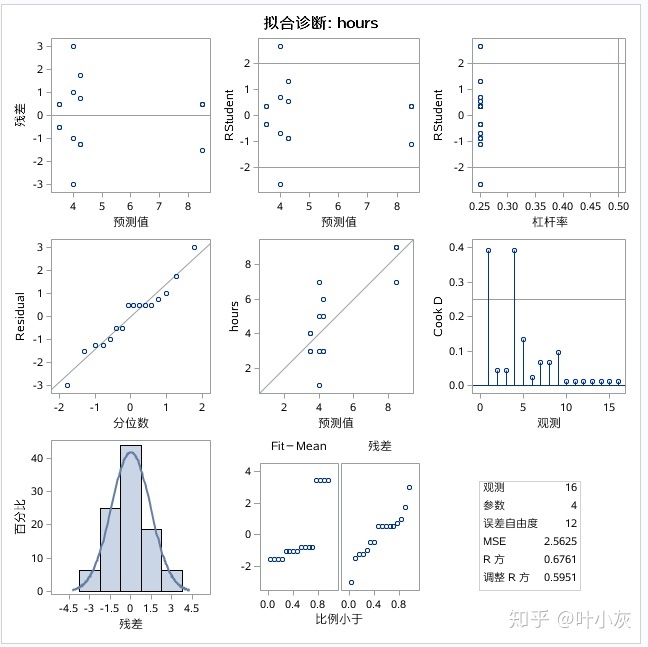
上述代码中PROC GLM语句中的PLOTS选项生成了拟合诊断图。根据Q-Q图和残差图看出,原始数据呈近似正态分布。
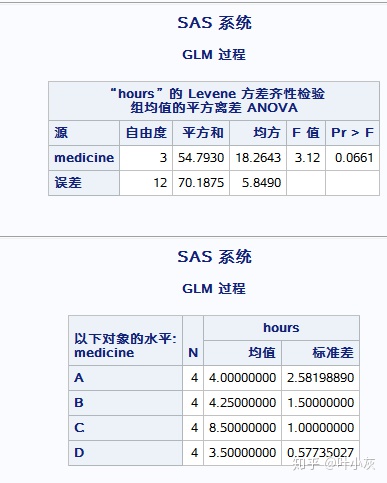
代码中 means Medicine /hovtest; 用于检验方差是否相等,即方差齐性检验。p值=0.0661,大于默认的0.05,因此我们接受原假设,认为方差是相等的。至此,方差分析的其余两个假设条件验证满足。
整个模型的输出结果如下图:
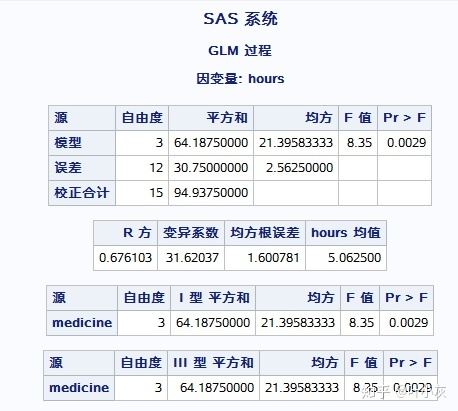
分析:可看出p值=0.0029,小于0.05,因此我们拒绝原假设,即认为这4种药物在延缓术后疼痛上具有显著性差异。除了Ⅰ型平方和和Ⅲ型平方和,还有Ⅱ和Ⅳ型平方和。一般以Ⅲ型作为主要参考依据。
3 显著因素下的水平间差异检验
3.1 LSMEANS与MEANS语句的区别
means和lsmeans在对均值的计算上存在一定的区别。
例子:

A、B两种新药,在不同医院进行临床试验,数据收集如上图。means和lsmeans计算结果如下:

从MEANS角度看,药B比药A要好,但是从lsmeans看,两款药效果一样。一般情况下,若数据是均衡的,二者的计算结果相等。从使用的角度看,当数据不均衡时,使用lsmeans方法。另外lsmeans也用于某个因素下水平间差异的检验。例如,已知某一因素作用显著,可通过lsmeans分析该因素两两水平间的差异。
3.2 利用LSMEANS语句进行水平差异检验
LSMEANS 因素 <选项>方差分析中,常见的选项有两种,PDIFF和SLICE。前者用于两两影响,后者用于多因素。一个PROC GLM中可以指定多个LSMEANS语句。

控制选项误差的方法有两种。一种控制两两比较的误差(CER),一种控制整个实验的误差(EER)前者可选择
LSMEANSpdiff=all adjust=t后者可选择
LSMEANSpdiff=all adjust=tukey 或者 LSMEANSpdiff=control adjust=dunnett例子:
因素medicine 的确是一个显著性因素,共有4个水平:A B C D,欲分析两两比较的药效。
ods graphics on;
proc glm data=ex.relifetime;
class medicine;
model hours=medicine;
lsmeans medicine/pdiff=all;
run;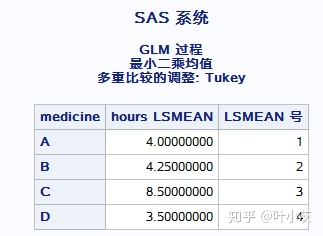
提交代码,首先可看到每个组的LSMEANS信息。
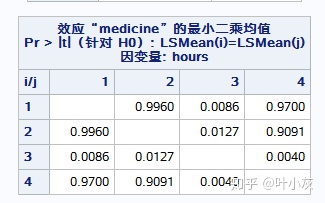
根据上面的LEMEAN号,做出4*4矩阵表。由于
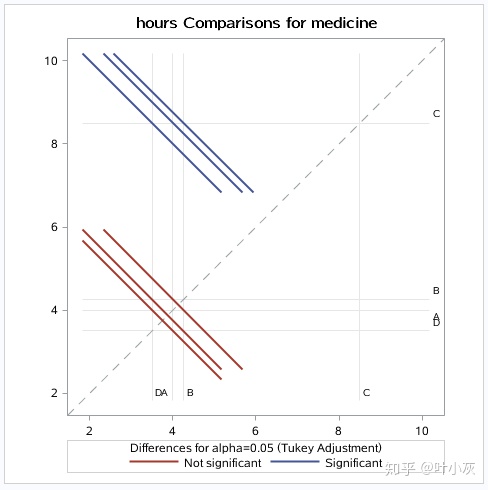
代码中pidff=all,要求ods选项是打开的,生成上面置信区间图。斜向上的虚线为差异为0的参考线。斜向下的实线代表了class变量下两个不同水平的均值。本例中有4个不同水平,可以组成6对不同水平的组合。实线与虚线没有交点,认为存在显著性差异。有交点,认为没有显著性差异。
4 双因素实验的方差分析
4.1 双因素实验概述
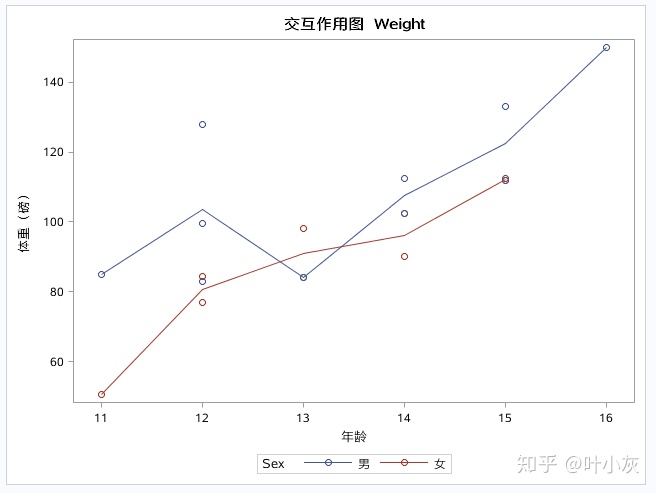
与单因素分析不同,双因素方差分析中因素间可能会有交互作用。如果没有交互作用,可独立分析。如果有交互作用,需要进一步分析:
- 在因素A的某个水平下,因素B对响应变量的作用
- 在因素B的某个水平下,因素A对响应变量的作用
- 在所有因素(AB)的组合中,哪两组的差异最大

4.2 利用GLM过程对不均衡数据进行分析
例子:sashelp.class 包含了学生的姓名、性别、身高。分析年龄和性别是否是影响体重的显著因素,并对显著因素中的水平(水平组合)的差异性进行分析。
1)假设学生数据符合方差分析的假设条件。
2)显著性水平0.05
proc means data=sashelp.class N mean;
class Age Sex;
var height;
run;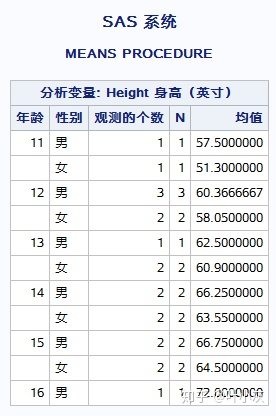
首先通过描述性统计信息,发现这不是一个均衡的数据,故我们采用GLM来实现分析。
proc glm data=sashelp.class ;
class Age Sex;
model weight=Age Sex Age*sex;
run;
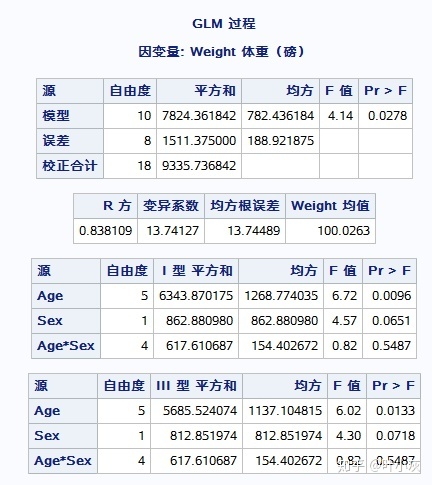
不同年龄和性别组合有11组,故模型的自由度为11-1=10,观测值为19,故校正合计自由度为19-1-18。误差自由度为8。
3)F=4.14,p=0.0278,可初步判断因素对体重有显著性作用,但哪个因素还需具体分析。源Age*Sex的作用是判断二者是否有交互作用,p值=0.5478>0.05,可认为没有交互作用。而源Age的p值=0.0133<0.05,可认为Age是一个显著性因素,源Sex的p值=0.0718>0.05,不是显著性因素。
可进一步分析Age的水平间差异性,提交以下代码:
lsmeans age/pidff=all adjuest=tukey;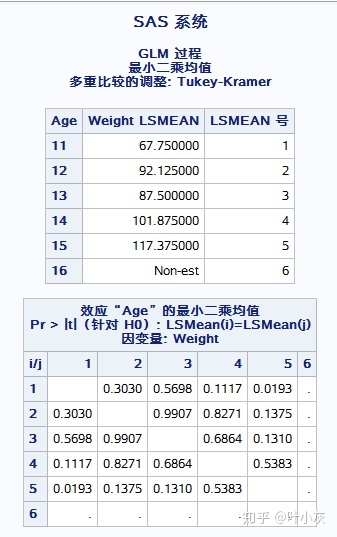
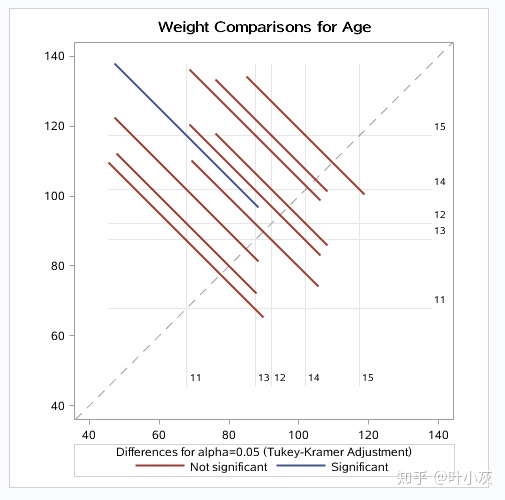
如图,水平Age15和Age11存在显著性差异。
4.3 有交互作用因素的方差分析
例子:ex.fruit记录了在不同湿度和温度下某种植物的产出。数据如下;
data ex.fruit;
input humidity $ temperature $ output_lbs @@;
datalines;
A1 B1 58.2 A1 B1 52.6
A1 B2 56.2 A1 B2 41.2
A1 B3 65.3 A1 B3 60
A2 B1 49.1 A2 B1 42.8
A2 B2 54.1 A2 B2 50.5
A2 B3 51.6 A2 B3 48.4
A3 B1 60.1 A3 B1 58.3
A3 B2 70.9 A3 B2 73.2
A3 B3 39.2 A3 B3 40.7
;
RUN;进行交互性分析
proc glm data=ex.fruit;
class humidity temperature;
model output_lbs=humidity temperature humidity*temperature;
run;
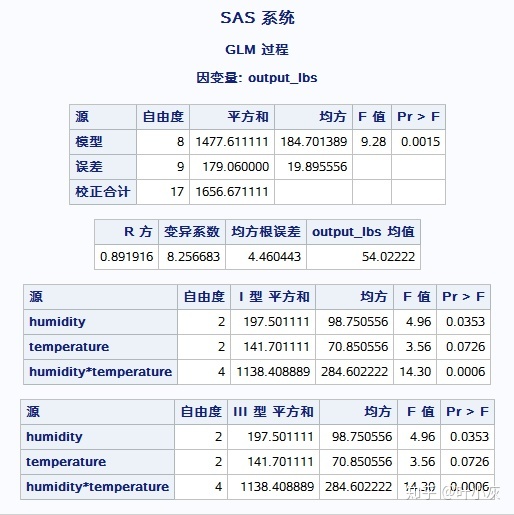
两个因素各有3个水平,共9中组合,故模型的自由度为9-1=8。18个观测值,故校正合计自由度为18-1=17。故误差自由度为17-8=9。F=9.28,p值=0.0015<0.05,两个因素或者组合对产出具有显著性作用。
由各个源的p值可以看出,humidity和humidity*temperature是显著因素。
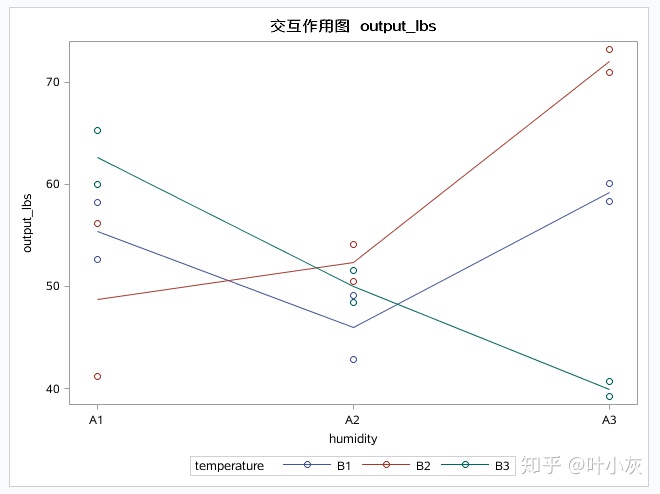
lsmeans humidity*temperature/slice=humidity;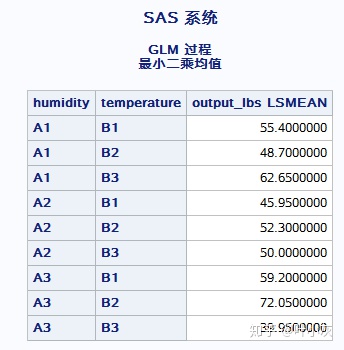
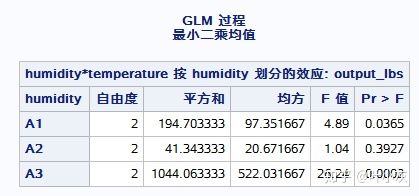
可看出,在A1和A3的湿度下,温度对产出具有显著性影响;在A2的湿度下,温度对产出无显著性影响。















 5103
5103











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









