





SQL 中需要针对关键字执行的优化包括 3 个:
- exist / in
- order by
对应的优化方法:
exist / in 有 2 种优化方式:
- 主查询的数据集大,则使用 in
- 子查询的数据集大,则使用 exist
order by 有 5 种优化方式:
- 根据情况,选择使用单路排序、双路排序
- 单路排序调整 buffer 的容量大小
- 避免使用 select * ... 语句
- 复合索引不跨列使用
- 保证排序的一致性
代码实例
实例 1:
目的:order by 单路排序,调整 buffer 的容量大小
总结:有可能不是一次 IO,超出 buffer 后可能会被强制双路。
如果 buffer 中可以放下排序字段,则一次单路即可。
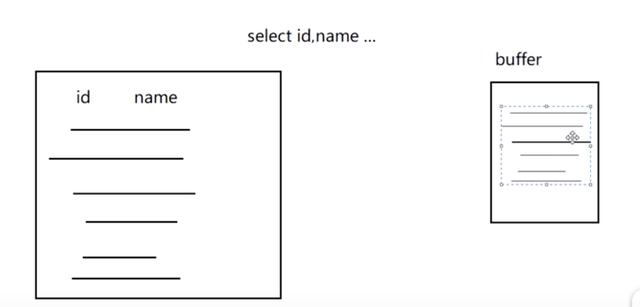
如果数据量超大, buffer 中放不下排序字段,则会被强制双路。
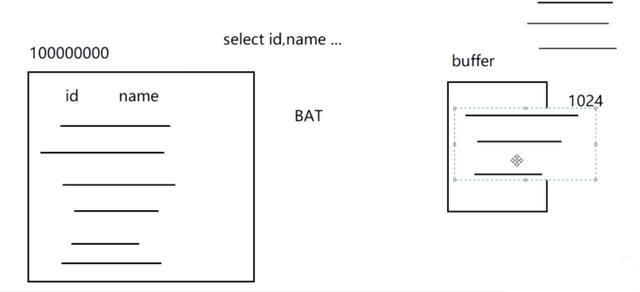

实例 2:
目的:order by 双路排序
第一次排序,排 id 字段
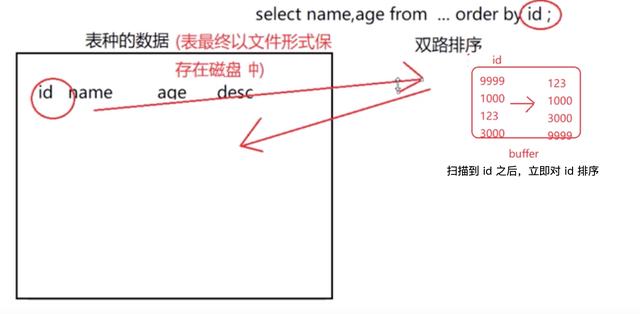
第二次排序,排 name, age 字段
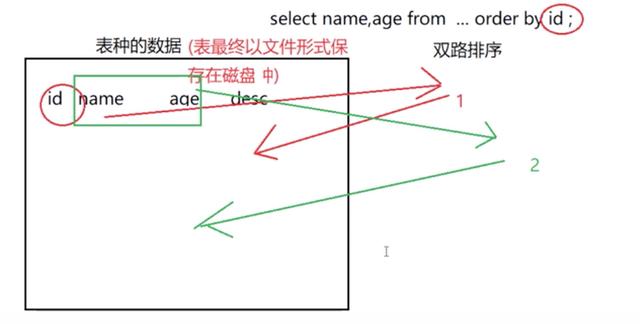
总结:
单路排序比双路排序占用更大的内存。
提高处理效率的方式是主动调整 buffer 的大小。
实例 3:
目的: order by 排序一致性
order by a desc, c desc避免字段有的是升序,有的是降序
order by a asc, c desc实例 4:
目的: order by 避免使用 select *
使用明确的字段指定:
select a, b, c, d from ...替代模糊的:
select * from ...实例 5:
目的: exist 使用
select tname from teacher where exists (null)实例 6:
目的: in 使用
select * from A where id in (1, 3, 5)














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









