






 本文介绍了如何使用SPSS进行实证分析,包括描述性分析、信度效度分析、相关分析和回归分析。强调了在问卷设计、数据处理和假设检验中的关键步骤,帮助理解自变量对因变量的影响。
本文介绍了如何使用SPSS进行实证分析,包括描述性分析、信度效度分析、相关分析和回归分析。强调了在问卷设计、数据处理和假设检验中的关键步骤,帮助理解自变量对因变量的影响。

解读论文写作与发表策略
助您成功发表
关注实证分析主要包括描述性分析、信度效度分析、相关分析、假设检验(回归分析)。在分析之前我们首先要懂得SPSS的分析原理。学过高数的基本都知道假设检验的原理,SPSS软件的基本原理就是假设检验,即先假设H0:A对B没有影响条件成立,分析得出的结果P(sig.)<0.001/0.01/0.05,则假设不成立,即A对B具有显著性影响。

用SPSS分析的问卷有是李克特五级量表或七级量表,生手建议设计五级单因素的量表。问卷数据收集完成后,首先要剔除无效问卷(所有问题答案全选一种选项的或存在矛盾的答案等问卷),保证数据的准确性。分析步骤如下:
录入的问题及数据打开SPSS软件,在变量视图界面内输入问题及设置值,一般设置值为1非常不同意,2不同意,3不一定,4同意,5非常同意。同理输完一篇问卷即可。如下图:
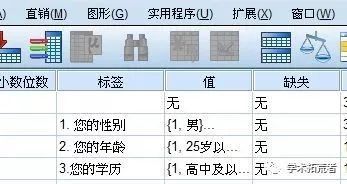
描述性分析主要是对被调查者的基本信息进行描述,如性别、学历、年龄、工作年限、居住地等等,这类问题一般放置在一份问卷的开头(也有放置在结尾,个人设计问卷时比较喜欢放置于开头)。描述性分析主要对问卷的均值、标准差进行分析,均值相同时,比较标准差,标准差越小,表示越稳定。
步骤如下图:
1、点击分析-----描述统计----描述----选择变量----点击选项----选择你需要描述的项(平均值、方差…..)。
2、分析----描述统计----频率---选择项,则可以得出频率频数。
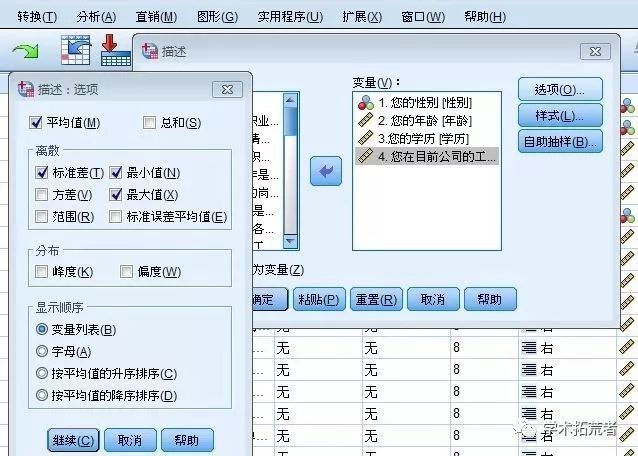
最后将自己需要的数据进行汇总了列成表格或图表(饼图/柱形图等)的表示,图表的项有频数、频率、均值、标准值等,并辅以文字说明,使结果一目了然。(注:以下图表及数据仅作为案例解释说明,数据不具有准确性和真实性)

信度分析主要是通过SPSS分析验证设计的问卷是否可靠,问卷题目之间是否具有良好的相关性进行分析,被调查者的答案是否存在矛盾,是否可靠等等。
问卷分析的步骤如下:点击分析----标度----可靠性分析-----选择项----确定即可
得出的结果如下:

结果分析:一般来说,问卷是否可靠主要看Alpha(a系数),a<0.7则表示设计的问卷信度不可靠,0.7
在进行下面分析时先说一下问卷的设计。实证分析的论文中比较简单的模型大概可能是:研究对象的影响因素(自变量)会影响研究对象的效果(因变量),A H B ; 即论文假设H为自变量A对因变量B会产生一定的影响。一般可以找出四五个影响因素设计为自变量,每一个影响因素可以设计3—7个问题进行调查。所以在进行可靠性分析的时候可以对每一个影响因素(自变量)的题目数(项数)分析一次,看是否每一个自变量的设计的问题都具有较好的信度。(若某一因素项数信度不够好,首先可以通过调整题目中的表达措词、修改或增加关键词来提高信度,若某道题目修改调整后信度仍然过低则可以删除这一道题目达到提高整篇文章的信度)。
效度分析和因子分析通俗来说,效度分析是检验问卷题目与研究目的是否相一致,即不能研究顾客对某产品的满意度,问卷设计的问题则是调查某产品的市场覆盖率。
一般分为内容效度和结构效度,内容效度是指题项与所测变量的适合性和逻辑相符性(我们在设计问卷时一般都要参考或引用前人的问卷,因此内容效度不存在问题,当然如果设计的一份全新的问卷则需要重点分析内容效度)。结构效度是指题项衡量所测变量的能力,实证分析一般着重分析结构效度,可以通过进行探索性因素分析(Exploratory factor analysis,EFA)检验来证明量表的结构有效性。
分析步骤如下:分析----降维----因子----将左边所有变量选到右边变量框中----描述---选择初始解和KMO---点击继续-----提取-----在提取里选择主成份和碎石图---继续----旋转----选择最大方差法。
如下图:
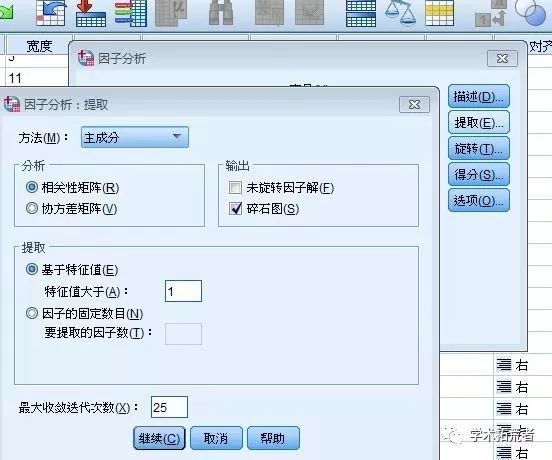
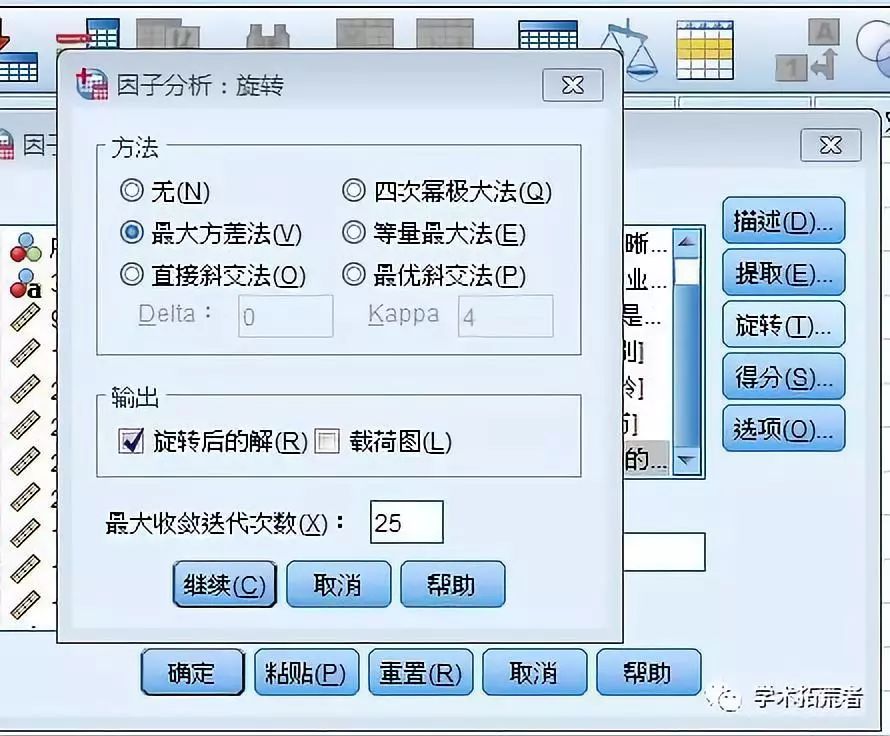
得出结果如下:
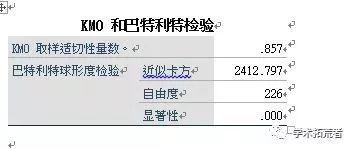
结果分析:效度分析结果主要看KMO值和sig.(显著性),若KMO>0.7,则说明问卷中设计的自变量之间具有一定的联系,问卷是有效的;sig.<0.001说明该问卷符合做因子分析,下一步则可以进行因子分析(EFA)。
因子分析结果如下(仅抽取部分比较重要的图解释):
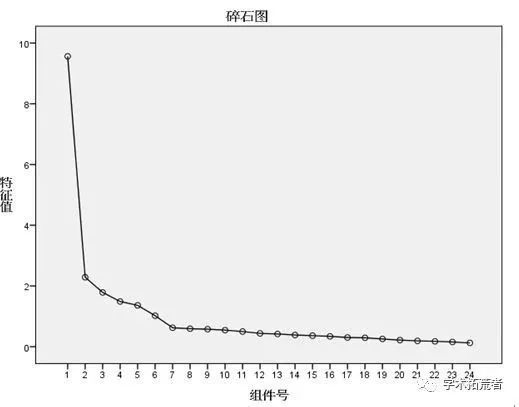
看碎石图的关键就是找拐点,也就是找图中陡坡和缓坡的临界点(特征值明显较大的因子),趋于平缓前的点有几个则说明这份问卷可以分为几个因子(当然还要结合特征值、总方差解释等图考察)。如上图看出从第7个点开始趋于平缓,即前面有6个点属于陡坡上的点,初步可以说明这份问卷设计的因素可以分为6个因子。
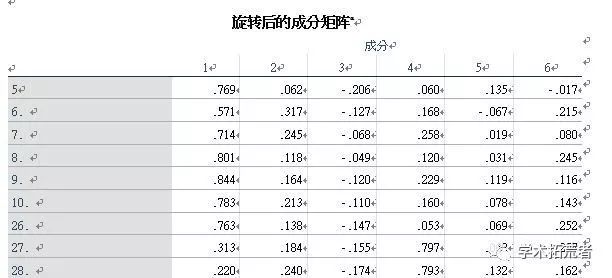
旋转后的成分矩阵的作用是知道那几道题可以归为一个因子,上面截取一部分作为说明(左侧的数字为问卷中的题项,题目内容已删除)。上图可以看到一共6个成分因子,其中问卷题目5、6、7、8、9、10、26可以第一个因子(成分1对下的数字0.769、0.571、0.714…….均大于0.5,即各个测量题项的最大因素负荷均大于0.5,且交叉载荷均小于0.4则可作为一个因子);同理题目27、28则可以作为一个因子,成为4对下的数字为0.797、0.793…….。
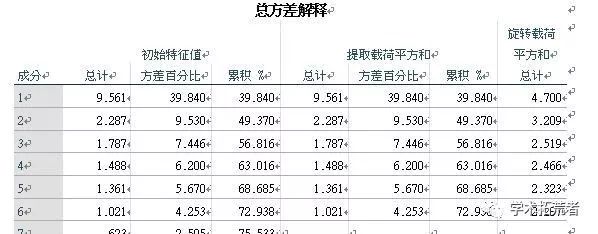
总方差解释图主要看累计百分比的项。如上图6个因子在整份问卷中的总解释能力(累计百分比)达到了72.938%(总解释能力>50%可以说明筛选出来的因子有良好的代表性,当然实际操作中一般>80%的问卷因子解释能力比较好)。所以整份问卷基本可以提取出6个因子作为主要变量,其余的为次要变量。
通过上面三个图的分析,可以确定这一份问卷一共可以提取出6个因子(6个自变量)。
相关分析在进行相关分析前首先要取各个因子的平均值(如上面7道题目作为因子1,因子1的平均值就是取7道题目的维度平均。得出6个因子的维度平均值后进行相关分析。
步骤如下:分析----相关----双变量-----将左边的变量选到右边-----在皮尔逊和双变量前打勾----确定。
如下图
得出的结果如下:
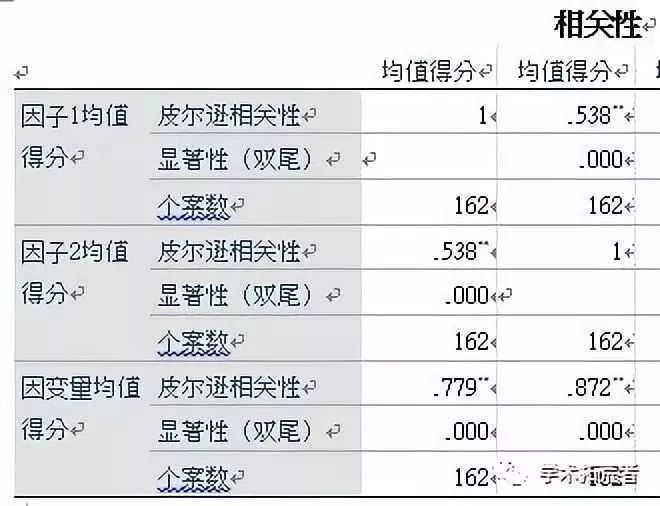
上图中,假设前面两个为因子1、因子2(自变量),第三个为因变量。相关性是检验自变量与因变量的关系。可以看出因子1与因变量的相关系数为0.779,且sig.<0.001,说明自变量(因子1)与因变量呈正相关。(相关系数的取值范围介于-1~1之间,绝对值越大,表明变量之间的相关越为紧密)。
回归分析回归分析需要看的图有模型摘要图、ANOVA、系数图等等。
步骤如下:分析----回归----线性-----选择自变量和因变量----点击统计----选择德、共线性等(看自己需要知道什么就选什么,不一定要选共线性诊断等)---继续----图----选择XY变量-----继续---保存----继续---确定。
如下图:
得出结果为:

模型摘要图主要看R方和德宾值(D-W),调整后的R方为0.684说明自变量对因变量的可解释程度为68.4%(R方代表的是自变量对因变量的解释能力,R方与调整后的R方越接近说明数据越稳定)。D-W值是检验自变量之间是否存在自相关,上图中D-W>2表示问卷中的几个自变量无自相关性,(D-W值的范围记得不是很清楚了,见谅…..)。
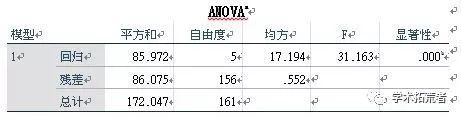
即方差分析表,ANOVA表的一个作用就是验证假设(A对B不产生影响)是否成立,一般只看sig.值即可,上图sig.<0.01,说明拒绝原假设,至少有一个对因变量产生显著性影响。
下一步看系数表,系数表则说明有几个自变量对因变量产生显著性影响。如下图:
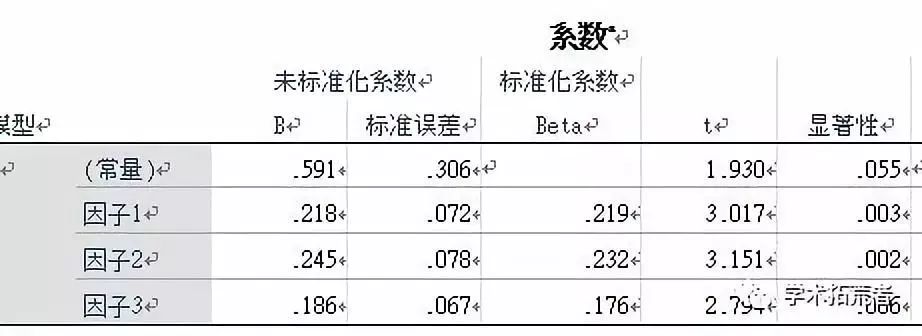
上图中回归系数b是通过样本及回归模型通过SPSS计算得出的,是反映当自变量x的变动引起因变量y变动的量。主要看显著性,因子1、2、3的sig.<0.05,说明3个因子均对因变量产生显著性影响。
从上面可以看出,相关性分析是检验自变量与因变量之间是否具有相关性(正向或反向相关),回归分析则说明了自变量对因变量是否具有显著性影响。
当然上面提到的步骤和图大部分是我感觉论文需要用的,还有很多像散点图等一些小细节很多也没有写,一个是因为篇幅有限,一个也是因为时间也过去大半年了,有很多也记得不是很清楚了,上面写的内容基本是我去年写论文后学到的,很多都是个人的理解,仅供参考。希望大家毕业季顺利!

来源:知乎(隔壁那少年)版权为原作者所有
编辑:学子

开始报名啦 | 第五期核心期刊论文写作高级实战研讨会
点击下图,了解详情



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









