





断更了几天, 忙着别的事情去.....今天终于好好坐下, 继续写分享.
这一期主要内容是, 利用TableGroup分组 & 最终合并查询;
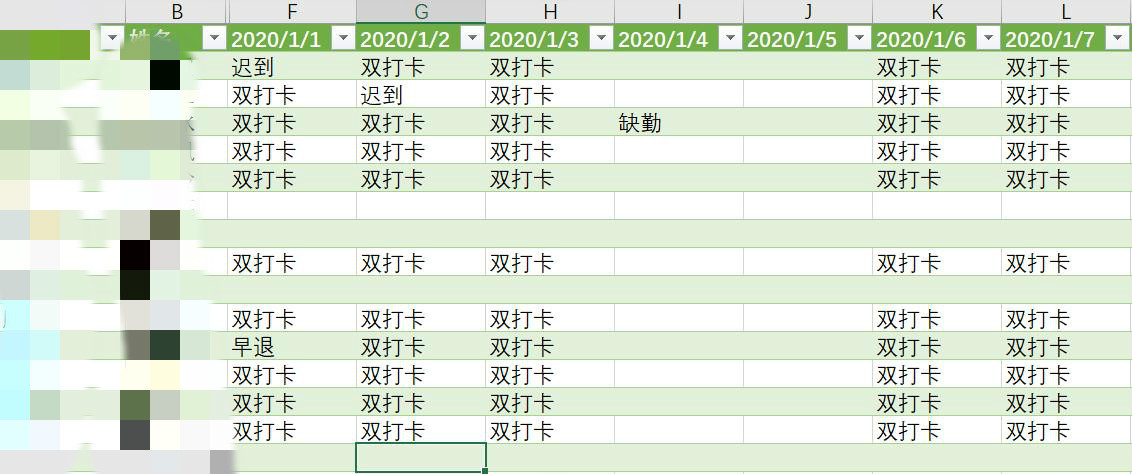
一. 数据反馈
前几天, 妹纸发来消息说数据不对, 数据有丢失; 听她详细一说, 原来没用统计零打卡人员的数据. 后来我仔细检查了数据, 原来我将出勤数据作为最终合并查询的主体, 最后得出的统计结果, 很自然没有零打卡的人员数据.
我哄了几句抱怨的妹纸, 然后拍拍心口保证很快完成任务(赶忙拉回妹纸的信心....).
好了, 说正题, 首先确立的要求: 统计的最后结果和人力表上的数据一致, 那么, 最终合并查询的主体是人力表.
在最终合并查询前, 我们先处理以下几个步骤:
1.对出勤记录进行数据清洗, 然后作为主体与出勤要求合并查询; 利用TableGroup分组, 汇总每个员工每天的出勤情况; 以考勤日期作为依据, 对打卡状态进行透视;
2.以人力表为主体, 并与第2步得出的统计表进行最终合并;
二.合并查询打卡记录
将上一篇文章已整理好的出勤要求和人力表合并, 初步统计出勤人员的打卡记录.
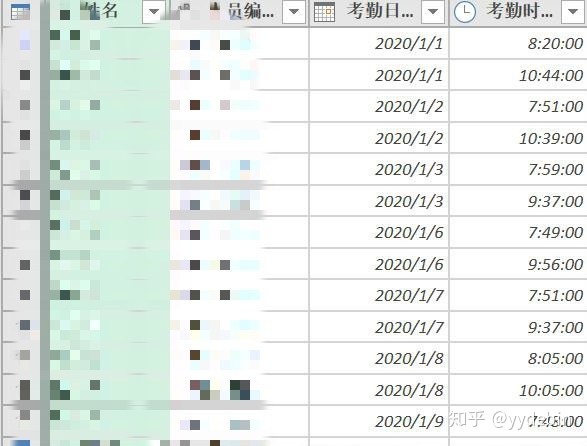
跟上一篇文章处理时间类似, 新增辅助列将考勤时间转化为具体的数字;
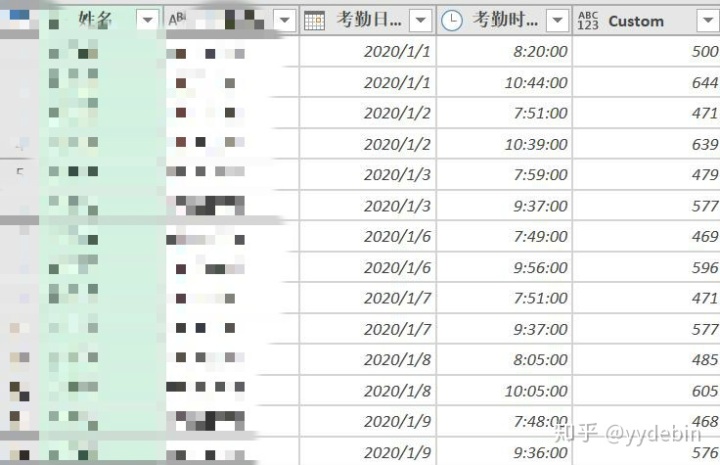
数据清洗和整理后, 准备进行出勤记录与人力表的合并查询:
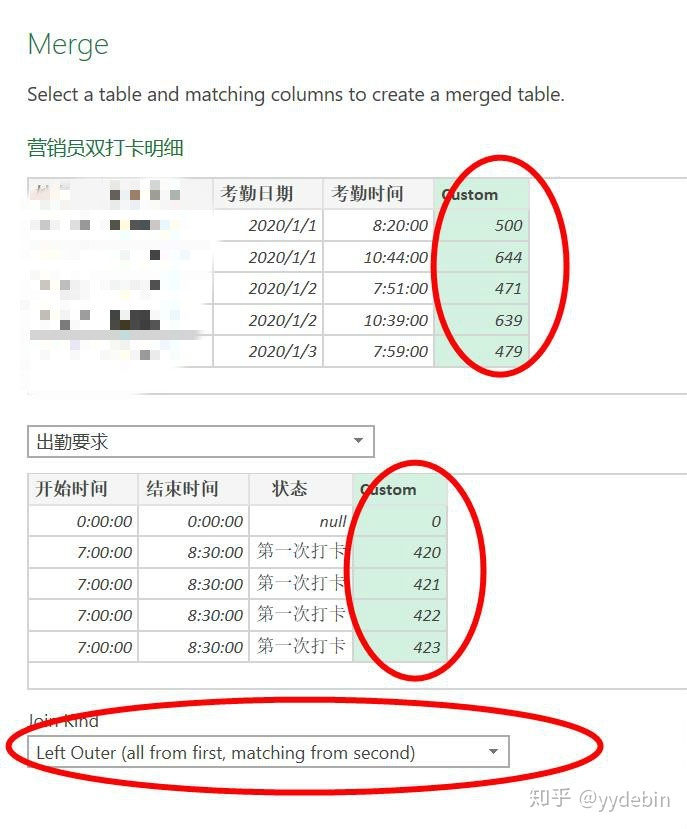
Join kind选择 Left Outer, 也就是仅匹配两个表匹配列中, 相同的数值;
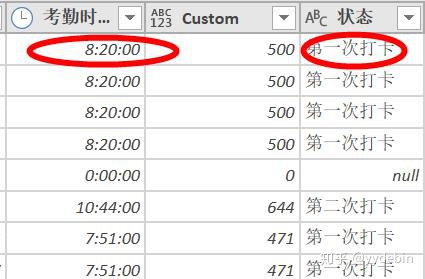
删除Custom辅助列(前一步骤), 排序整理数据;
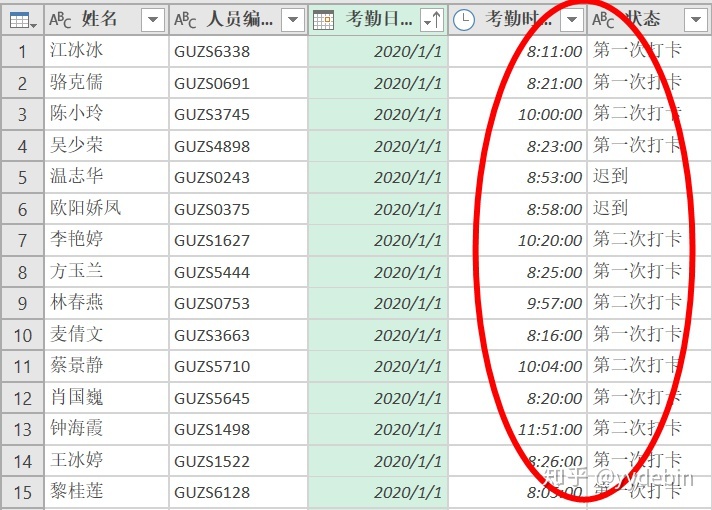
三. 员工每天打卡汇总思路
先回顾一下, 汇总员工每天打卡状态的要求:
1.当日打卡记录有且只有"第一次打卡",状态为"早退";
2.当日打卡记录有"第一次打卡"和"第二次打卡",状态为"双打卡";
3.当日打卡记录有"迟到"记录的,状态为"迟到"(另一侧面说明, 员工有打卡记录);
4.当日没有打卡记录的,状态为"缺勤";
好了, 这时候需要TableGroup函数, 来解决以上的汇总问题.
关于TableGroup函数语法具体阐述, 知乎上很多大神都有独特的解释; 在这里我分享一下对这个函数的理解:
首先, 这个函数的对象是Table, 然后分组的依据key是需要统计的Column(也就是说, 这些Column是不需要动的);
其次, aggregated column对象是list, 而这个list可以通过自定义的函数aggregated;简单说就是绑定分组后, 拆分出来最小单位,可以通过aggregated操作(最关键的地方);
最后, 操作的list需要全表格匹配,因此默认选择globalkind;
四.运用TableGroup函数汇总
按照步骤, 第一步,先选择分组的key:
"人员编号", "姓名","考勤日期";
选择依据: "人员编号"列作为最终合并查询的连接, "姓名"列作为查询关键字保留, "考勤日期"列汇总当天的出勤状态;
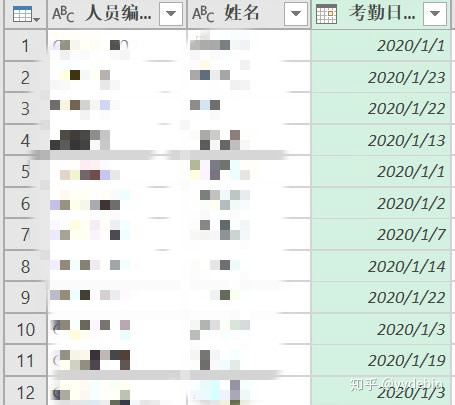
第二步, 操作对象是"打卡状态"列, 对aggregated list部分, 进行函数定义:
重申一遍, 前一步选择的key, 已将aggerated list绑定; 换句话说, 接下来定义的函数, 只对绑定的list操作;
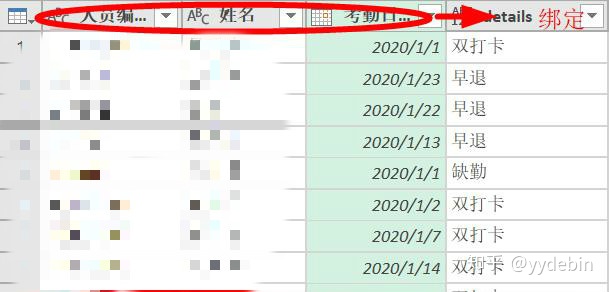
然后, 定义操作aggregated的函数: if...else...than.....函数和List.ContainAll函数;
思路流程图:
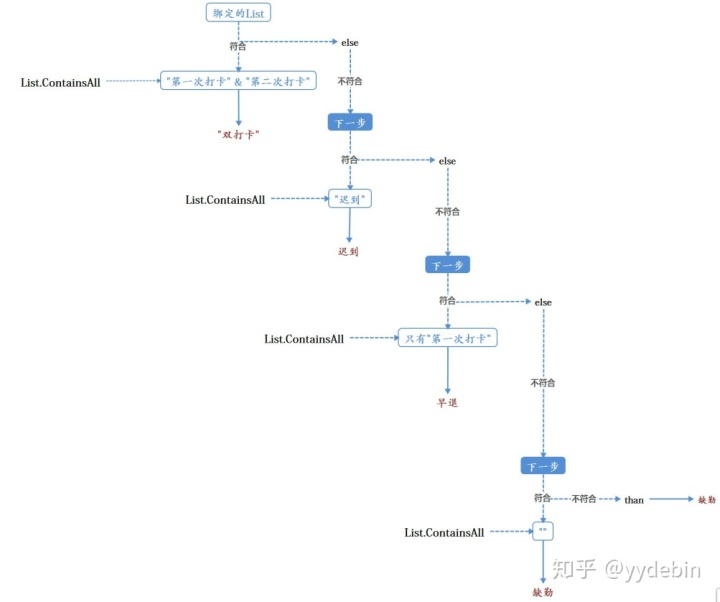
说明一下, 思路的安排:
1.优先考虑List.ContainsALL安排"双打卡"匹配, 筛选后的list数据只剩下"第一次打卡", "迟到"和null值;
2.其次, 再用List.ContainsALL筛选"迟到"的匹配, 那么剩下的List数据只剩下"第一次打卡"和null值;
3.最后, List.ContainsALL筛选"第一次打卡", 定义为"早退"状态; 那么, 余下的数据统一定义为"缺勤";
代码如下:
分组的行 = Table.Group(#"Sorted Rows", {"人员编号", "姓名", "考勤日期"},
{{"details", each
if List.ContainsAll([状态],{"第二次打卡","第一次打卡"}) then "双打卡" else
if List.ContainsAll([状态],{"迟到"}) then "迟到" else
if List.ContainsAll([状态],{"第一次打卡"}) then "早退" else
if List.ContainsAll([状态],{}) then "缺勤"
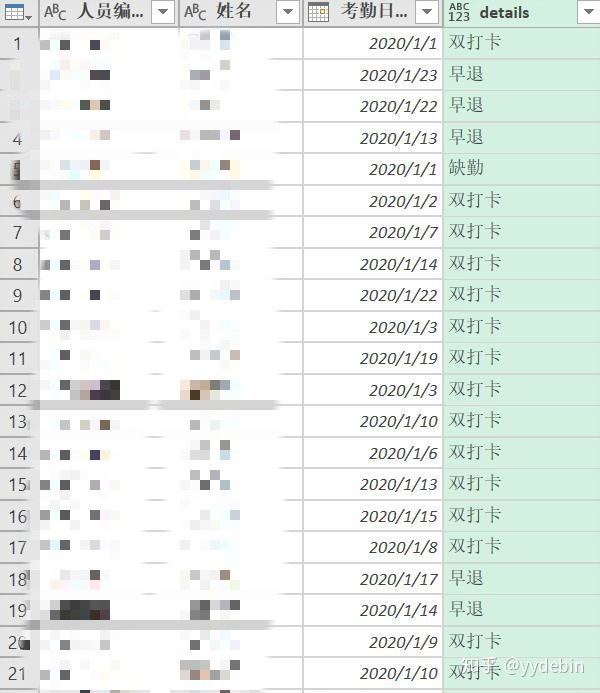
else "缺勤"}})分组后的效果:
五. 与零打卡人员合并查询
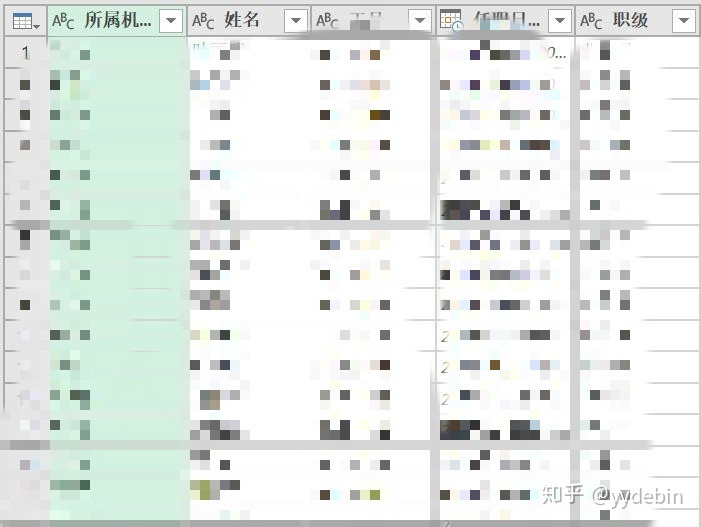
复制人力表, 新建查询;保留需要列后,作为我们最终汇总表的主体:
合并查询, 注意选择Full Outer, 保留主体表原有所有行;(换句话说, 匹配不到的行会产生null值).

展开合并查询后, 保留需要的数据
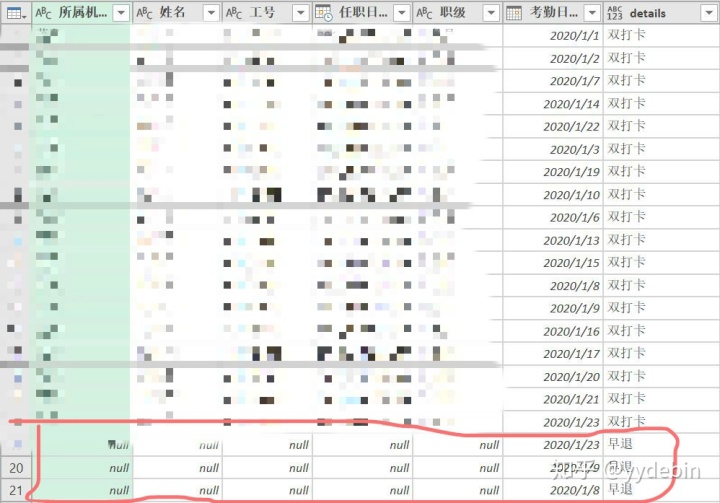
由于部分员工零打卡,"考勤日期"列存在null值,没有进行下一步的透视(power query会报错, 说系统没办法对null值操作);
因此,我想到的解决方法是, 把"考勤日期"的null值统一替换为"2020/12/31"(方便后续步骤删除):
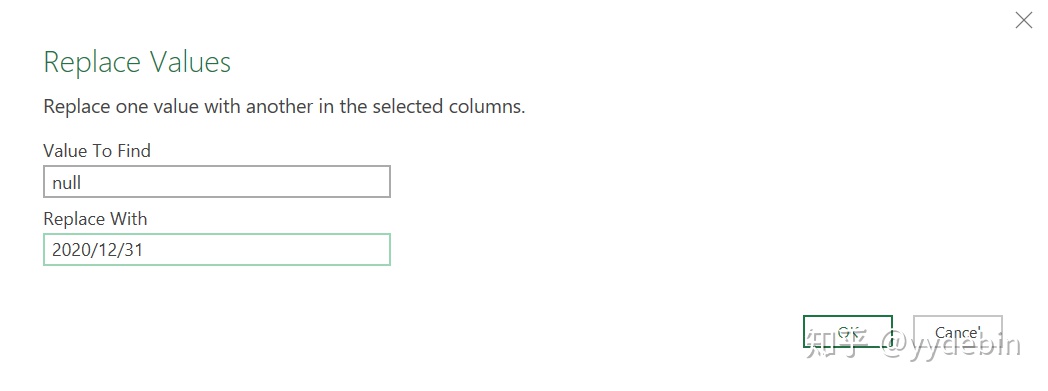
按日期次序, 对"考勤日期"列排序(影响最终结果顺序):
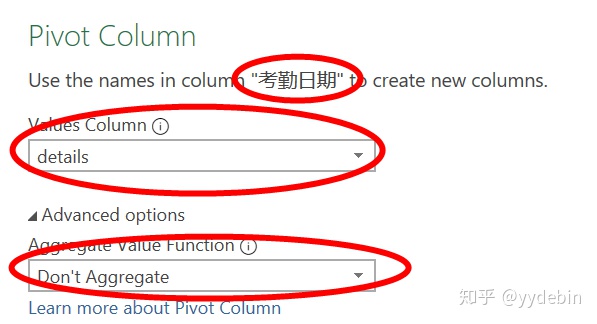
完成以上步骤后, 进行最后的透视工作(Advanced options选择Don't aggregated):
删除"2020/12/31"列数据, 获得最后的结果:
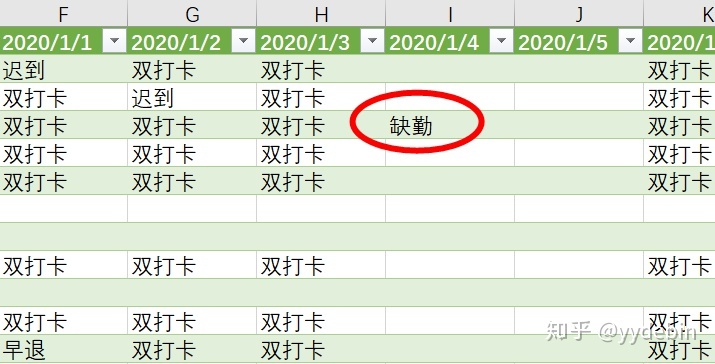
到这里为止, 所有要求都完满达成~~~
六. 后续
用三期文章分享出勤问题的解决, 确实篇幅稍长; 原本想着记下思维过程(当然讨好妹纸才是动力的来源......), 方便为日后遇到同类的问题提供思路; 后来感悟到, 知识需要复盘巩固, 不然容易丢失;power query基础知识, excel学过的多重if嵌套, 对英文版说明和理解, 还有参考知乎上各位大神的思路......综合运用各项知识, 获得最终效果那一刻的成就感是难以言喻的; 因此, 我打算以后按照这样的思路, 每学到新的知识记录并复盘, 分享到知乎上, 说不定是另类的快乐.(本人并不期待能有多少赞赏和评论, 仅作为记录一种手段, 这个是从妹纸上学回来的..)
顺便说一下, 本人还在学习日语和法语中(自学差不多一年多,总算入门.....), 日后有空会分享其他感兴趣领域的文章~















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









