





 点击上方“蓝字”带你去看小星星
点击上方“蓝字”带你去看小星星

表1 jobinfo数据变量说明
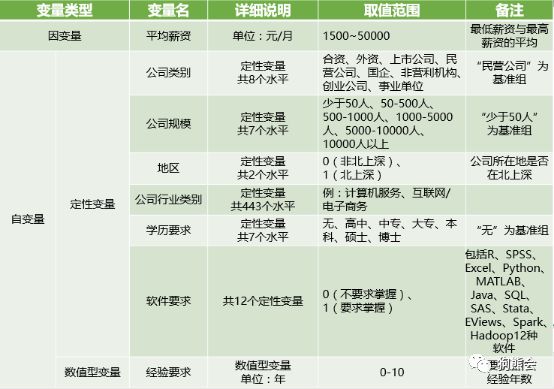
做好数据分析,首先要确定好目标,比如分析数据分析岗位,关心的是招聘薪酬主要都受哪些因素影响,以及能不能根据自身条件预测自己能不能拿到高薪等。由此就确定了target因变量是岗位薪酬(平均薪资),自变量则是各种可能的影响因素(包括软件要求、经验要求、公司属性等),而分析目标就是通过建立因变量与自变量之间的多元线性回归模型,估计模型系数,检验系数显著性以确定自变量是否对因变量有影响,并将自变量新值代入模型预测因变量新值。
2、数据预处理确定分析目标以及使用线性回归模型以后,要进行数据预处理。数据预处理就是整理数据、使之变成可以直接建模分析的数据格式,在线性回归时就是数据矩阵。一般来说,数据矩阵的因变量可以是分类变量或定量变量,自变量可以是0-1定性变量或定量变量。
为了得到数据矩阵,对于jobinfo.xlsx,需要进行以下几步预处理:
(1)每个数据岗位的“职位描述”变量是一段文本,无法直接作为数据矩阵中的自变量。从中提取该岗位对于软件能力的要求:根据“职位描述”是否要求R,SPSS,Excel,Python,MATLAB,Java,SQL,SAS,Stata,EViews,Spark,Hadoop这12种软件的应用能力,生成12个0-1定性变量(每种软件1个),其中0代表不要求掌握相应软件,1代表要求掌握相应软件。
(2)每个数据岗位的“地区”变量是多水平变量(岗位来自许多地区)。参照经验,地域能否影响薪酬的关键是工作岗位是否在北上深等几个特大城市;因此,根据提供该岗位的公司所在地是否在北上深,重新生成1个0-1定性变量“地区”:0代表所在地不是北上深,1代表所在地是北上深。
(3)每个数据岗位的公司类别、公司规模、公司行业类别、学历要求等4个变量是多水平变量,例如学历变量包括X= 无、中专、大专、高中、本科、硕士、博士等7个水平。对于多水平变量需要将多水平变量用虚拟变量表示,基准水平为“无”,具体解决方案示例如图1所示。

图1 解决方案示意图
友情提示:步骤(3)会由线性回归建模代码lm()自动执行,无需另外编码。
注意:此处p水平变量只能表示成p-1个0-1定性变量,否则会出现多重共线性。当X1~X6全部为0时,就意味着岗位的最高学历要求为无,因此6个0-1变量便能表示7个学历水平。反而如果使用p个0-1变量表示,则p个0-1变量之和一定为1(每个岗位的最高学历要求有且仅有7个水平中的1个),将会造成多重共线性问题。
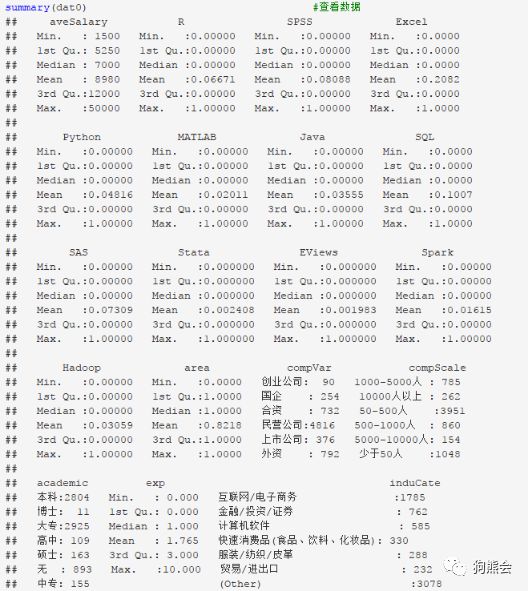
友情提示:在完成数据预处理后记得使用summary()命令看看生成的新数据集,判断一下数据情况是否符合预处理时的预想。示例如下所示。
在正式建立模型前,需要进行描述性分析,判断X与Y相关性的方向。
(1)单变量分析。以因变量平均薪资为例,展示其直方图如图2所示。
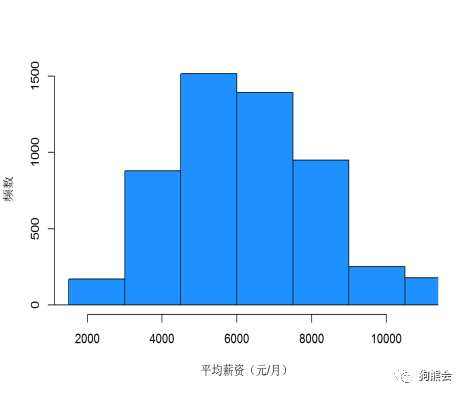
图2 平均薪资直方图
从图2中可以看出,平均薪资的中位数约为7000元,最小值不到2000元,最大值则超过了10000元。不过平均薪资超过10000元的工作岗位比例极小,可以说屈指可数。在原始数据中查看:
•最小值:1500元/月
规模为1000-5000人的民营公司。
不要求掌握任何软件,没有经验要求。
•最大值:50000元/月
规模为50-500人的金融/投资/证券行业公司。
地点在北上深,要求6年工作经验。
(2)自变量与因变量关系分析。如果自变量为定性变量,同时因变量为数值型变量,那么可以通过绘制箱线图来观察X与Y之间的关系。这里以变量“学历”为例展示箱线图(见图3)。在应聘数据分析相关岗位时,随着学历的上升,平均薪资也在上升。
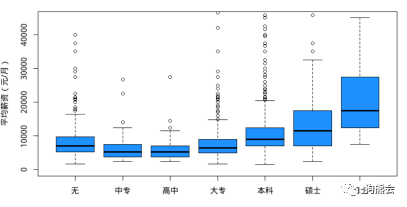
图3 不同学历水平的平均薪资分组箱线图
在原始数据中,“工作经验”为取值较为离散的连续型自变量。将“工作经验”划分为0~3年、4~6年、6~10 年三个经验水平,并展示岗位薪资关于经验水平的箱线图(见图4)。从整体趋势上来看,要求的经验越丰富,岗位平均薪资便越高。
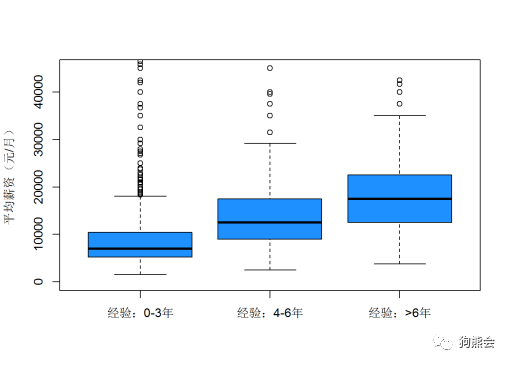
图4 不同工作经验的平均薪资分组箱线图
4、多元线性回归描述性分析之后,就知道了X与Y的相关性方向。接下来要做的是,通过命令算出了回归模型的结果。使用如下lm()命令,就可以直接得到建模结果以及模型整体评价的相关指标。

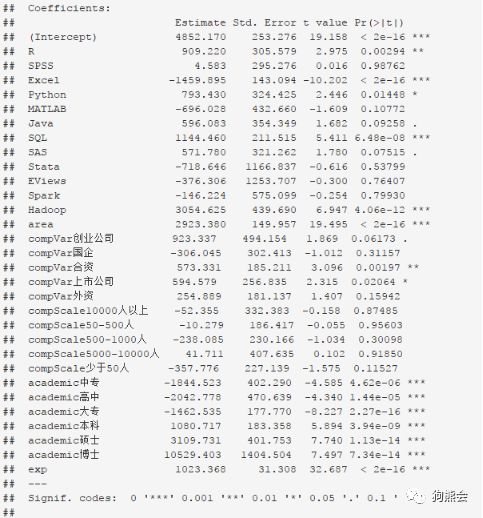

(1)模型系数解读
回归系数直接反映了自变量对于因变量的影响。线性回归模型的系数基本含义是,在控制其他自变量不变的条件下,某个自变量每变化1个单位,导致的因变量变化的平均值。下面来探索上面的回归结果如何解读。
1)自变量为数值型变量时,按以上原则直接解释其回归系数即可:比如由自变量exp(经验)对应的系数为1023.4可知,在控制其他因素下,对数据分析人员的工作经验年限要求每多一年,相应岗位的薪资就平均高出1023元/月。
2)自变量为0-1定性变量时,线性回归模型系数可以进一步解释为自变量取分类“1”时,因变量的值平均比自变量取分类“0”时高多少。比如自变量area(岗位是否在北上深)对应的系数为2923.38,说明在北上深的岗位,薪资平均比不在北上深的岗位高出2923.38元。
3)自变量为多分类自变量时,线性回归模型系数可以解释为自变量取该分类时,因变量的值平均比基准水平高多少。比如自变量academic(岗位要求的教育水平),其基准水平为“无”,academic博士对应的系数为10529.4,说明要求博士的岗位薪资平均比无教育水平要求的岗位高10529元。
(2)模型检验
1)模型整体显著性检验:F检验把所有的X打包在一起,判断所有X与Y之间的线性关系是否显著。检验结果中F统计量对应的p值远小于0.05,说明该模型整体线性关系在0.05显著性水平下是显著的。
2)模型整体的拟合效果:多元线性回归中,调整R方用来刻画模型整体效果。调整R方的大小受限于两个因素:模型训练误差越小,调整R方越大;引入模型的自变量个数越少,调整R方越大。调整R方指标体现了线性回归模型“刻画精准但避免过拟合”的基本思想。此处Adjusted R-squared=0.3093,希望回归诊断、改进模型可以使之增大。
3)各个系数显著性检验:即使F检验显示模型整体上是显著的,但总有一些鱼龙混杂的X存在。所以需要找到到底哪些变量是显著的,哪些变量是不显著的。回归结果中带特殊标记的变量为显著变量:“***” 的变量表示其在0.001显著性水平下显著,同理“**”表示0.01显著,“*”表示0.05显著,“.”表示0.1显著。那么不带这些特殊标志的变量就是非显著变量。
5、多元线性回归结果诊断接下来就是对结果进行诊断,根据直接得到的模型结果,看看数据是不是符合模型假设,不符合的话要对数据加以处理、调整,也即观察数据的特性,调整数据以适合选用的模型。

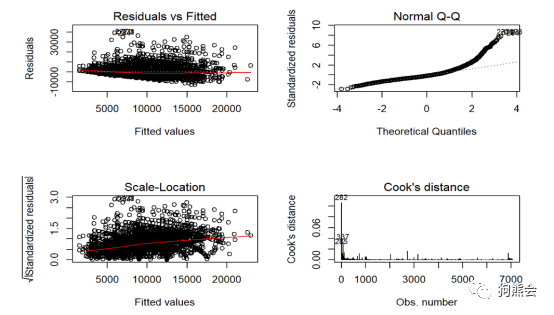
图5 模型诊断图
1. 模型检查
线性回归模型有一个重要假设就是残差与整个X向量应该是独立的,那么如何检验这个假设是否成立呢?通过绘制X变量与残差的散点图,判断残差与X变量之间是否有关系是否能解决呢?问题是,X变量往往是一组,而不是一个,绘制哪些X变量呢?如果对X变量加权,得到一个新的指标,判断该指标与残差的关系是否可行呢?但问题又来了,如何赋权?我们知道,Y的拟合值是通过X的加权组合而得到的,那么用Y的拟合值来作为这个指标即可,由此残差图(拟合值与残差之间的散点图)就产生了。
接下来就要确定什么样的残差图是有“病”的。先来看看几个可能出现的典型“病”状。如图6所示,残差的均值随着拟合值的变化呈现系统性规律变化,说明模型设定有问题,可能是自变量的二次项被遗漏了。
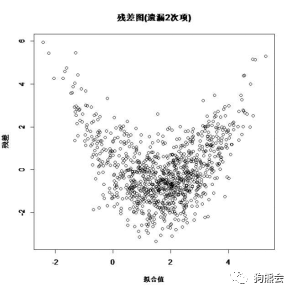
图6 遗漏2次项的残差图
残差图通常还用来检查异方差问题,如果残差的波动性(方差)随着拟合值的变化,出现系统性的变化规律,那么就说明出现了异方差问题,比如图7,这是典型存在异方差的残差图。而在图5的左上方中,可以看出残差的方差随着拟合值的增大有变大的趋势,说明还是存在一定的异方差问题。对于这样的情况,一般通过对因变量进行变换实现“诊治”,常用的变换是对数变换。从对数变换后的诊断结果来看(见图8),异方差得到了明显的改善。
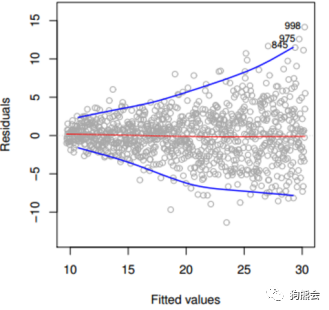
图7 存在异方差的残差图
2. 样本检查
把图5的右下方的 Cook距离图进行样本检查,看是否存在强影响点。如果存在强影响点,为了保证模型的稳健性,需要删除。其中如果某些样本点的Cook距离“特别大”,跟其他样本相比在量级上具有压倒性优势,则认为这些样本点可能是强影响点,否则不认为样本点是强影响点。值得注意的是,尽管图5中样本点“282”被系统标出,但是经过数值比较,发现它与其他样本点的Cook距离相比,其Cook距离不具有压倒性优势(一般认为Cook距离>1或者>4/n为强影响点),且删除后对回归结果影响不大,所以不认为样本点“282”为强影响点。
3. X变量检查
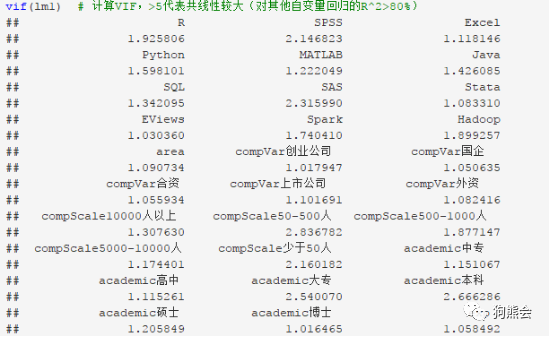
自变量中往往会存在一些“捣蛋鬼”,它们之间高度相关,导致模型系数结果不可靠,所以用VIF(方差膨胀因子)来找出那些“捣蛋鬼”。VIF关心的核心问题为是否有些X变量之间存在多重共线性。当自变量之间存在严重多重共线性时,会有以下症状出现:有些自变量的回归系数不显著,甚至回归系数的正负号与现实合理的解释相悖,一旦出现以上情况,就需要对数据进行X变量检查。
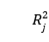 为把自变量
为把自变量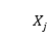 对其余所有自变量线性回归而得到的R方,如果为100%,则说明它可以完全由其他X变量代替,相应的VIF为无穷大。VIF计算公式如下:
对其余所有自变量线性回归而得到的R方,如果为100%,则说明它可以完全由其他X变量代替,相应的VIF为无穷大。VIF计算公式如下:

因此若某个自变量的VIF = 5,则这个自变量对其余自变量回归的R方高达0.8。显然,自变量的VIF值越大,代表多重共线性越严重。那么VIF大的标准是多少呢?一般而言,经验上认为VIF大于5或者10,则认为存在严重多重共线性。R中,可以直接利用vif()函数求出各个自变量的VIF值。由vif()函数的结果看到,所有变量VIF值都没有超过5,因此可以认为模型基本不存在多重共线性。
4. 其他检查
接下来检查Q-Q图(图5的右上方),当Q-Q图近似一条直线时,说明数据满足误差的正态性假设。图5中的Q-Q图并不是一条直线,说明数据可能存在问题,不符合正态性假设。对于此问题的解决,一般可以通过对因变量Y取对数。
5. 提出解决方案
检查结果显示,模型基本健康,但是有个小毛病——非正态问题。当模型存在非正态性时,需要根据具体情况对因变量进行变换,常用办法是对数变换。例如,在该案例中,对Y进行对数变换后再来复查一次,就会发现Q-Q图(见图8的右上方)显示非正态性问题得到了很大的改善。另外需要注意的是,实际数据很难满足各种诊断,对此也不必“执念太深”,而要把分析重点放到对业务问题的解读上。


图8 对数变换后的回归诊断图
6、模型选择及预测AIC原则力求在简洁的模型(自变量个数越少越好)与模型精度(拟合误差越小越好)之间找到一个最优平衡点,这里不再赘述其细节。在R中,使用step()函数即可轻松完成AIC步骤。
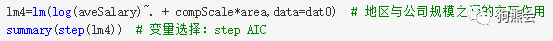
在以上步骤全部完成后,最终得到的模型系数估计以及刻画模型整体效果的指标如下:
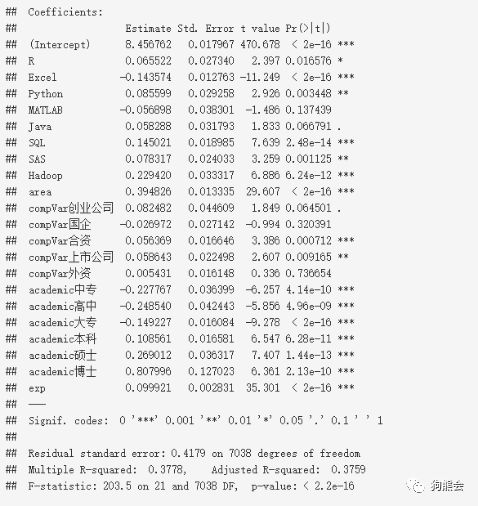
与一般线性模型不同,对数线性模型的系数含义代表的是“增长率”:在控制其他自变量不变的条件下,某个自变量每变化1个单位,因变量的增长率。
对照系数估计结果,控制其他因素不变时,得到以下结论:
(1)学历:高中学历的平均薪资最低,博士学历的平均薪资最高,比高中学历的平均薪资高0.8079 - (-0.2485) = 105.6%。
(2)经验:工作经验年限要求每多一年,平均薪资高出10.0%。
(3)软件:需要SQL,Hadoop应用的岗位比不需要的岗位平均薪资分别高14.5%,22.9%,需要Excel应用的岗位比不需要的岗位平均薪资低14.4%。
(4)地区:北上深地区比其他地区平均薪资高39.5%。
总的来说,自然是体面的学历、丰富的工作经验、多样的软件应用能力和在北上深打拼的决心,更能帮你拿到一份满意的薪水。
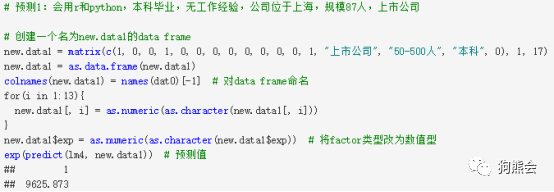
7、模型预测先来看看一个会用R和Python、没有工作经验的本科生,如果找一份位于上海、规模387人的上市公司总部提供的工作,他能不能养活自己呢?
这位本科生会使用R和Python,那他可以应聘的最优选择自然是同时要求会使用R和Python两款统计分析软件的岗位。根据这个工作岗位的条件,可以对照自变量的含义,得到应该代入回归模型的自变量的值。用predict()预测[1由于最终的回归模型因变量是“薪资”变量进行过对数变换后的结果,需要将模型预测值进行指数变换,才能得到我们真正关注的“薪资水平”。]如下:
如果是位已经工作7年的硕士,会用R,SAS和Python等多款统计软件,不仅会分析,还能用Java直接在APP/网页终端实现自己想法呢?
这位硕士可以应聘的最优选择自然是要求7年以上工作经验,同时要求会使用R,SAS,Python,Java等软件的精英岗位,预测月薪4.4w(见图9)。


图9 模型预测示意图
如果是一位没有学历、微弱的国企工作经验、不会任何统计软件的人,其薪资又会如何呢?


本节通过数据岗位招聘薪酬的案例分析,详细介绍了线性回归模型的完整用法,从确定分析目标,到数据清洗、回归诊断,并最终解释模型、进行预测,步步为营,目标清晰。

 购买指南
购买指南

请扫描以下二维码/点击链接购买
《R语言:从数据思维到数据实战》
1 京东

https://detail.tmall.com/item.htm?spm=a220z.1000880.0.0.0A6pvS&id=581845865737
点击















 3029
3029











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









