





需求: 获取某网站近10万条数据记录的相关详细信息。
分析:数据的基本信息存放于近1万个页面上,每个页面上10条记录。如果想获取特定数据记录的详细信息,需在基本信息页面上点击相应记录条目,跳转到详细信息页面。详细信息页面的地址可从基本信息页面里的href属性获取。
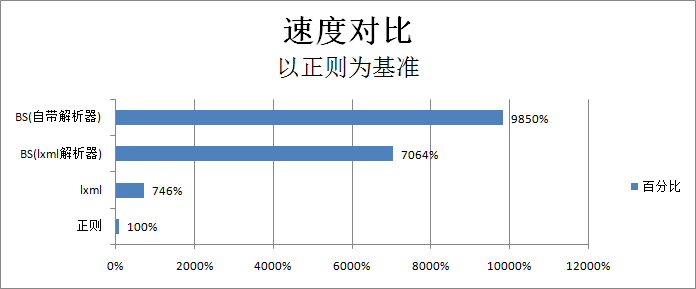
方法:开始时使用beautiful soup进行爬网,因速度较慢,换用lxml,速度改善不明显。
beautiful soup
importbs4importreimportrequestsimportlxml.html
f=open('testpython2.txt','w',encoding='utf-8')
j=30
while(j<41):
beautiful=requests.get(webaddress).content
soup=bs4.BeautifulSoup(beautiful,"lxml")
m=5
while m <85:
daf1=soup.find_all('a')[m].get_text()if daf1!='哈哈':
daf=soup.find_all('a')[m-1].get('href')
c='webaddress1'+str(daf)if requests.get(c).status_code==500:
f.write('Cannot found!')
f.write('\n')else:
beautiful1=requests.get(c).content
soup1=bs4.BeautifulSoup(beautiful1,"lxml")
daf2=soup1.find(id="project_div2")
p=2
while (p<20):
mm=daf2.find_all('td')[p].get_text()
f.write(mm)
f.write(' ')
p=p+2daf3=soup1.find(id="xiugai")
hh=0for tag in daf3(re.compile("td")):
hh=hh+1q=2
while (q
nn=daf3.find_all('td')[q].get_text().replace(' ','')
nn1=daf3.find_all('td')[q+1].get_text().replace(' ','')
nn2=daf3.find_all('td')[q-1].get_text().replace(' ','')
nn3=daf3.find_all('td')[q-2].get_text().replace(' ','')if nn2==nn3:
f.write(nn2)
f.write(';')
f.write(nn)
f.write(',')
f.write(nn1)
f.write(',')else:if nn2=='1':
f.write('InteriorRing')
f.write(nn2)
f.write(';')
f.write(nn)
f.write(',')
f.write(nn1)
f.write(',')else:
f.write(nn2)
f.write(';')
f.write(nn)
f.write(',')
f.write(nn1)
f.write(',')
q=q+4f.write('\n')
m=m+8j=j+1f.close()
lxml
importbs4importreimportrequestsimportlxml.htmlfrom lxml.cssselect importCSSSelector
f=open('testpython2.txt','w',encoding='utf-8')
j=2001
while(j<2592):
link="webaddress"headers={'User-Agent':'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US; rv:1.9.1.6) Gecko/20091201 Firefox/3.5.6','referer':'link'}
beautiful= requests.get(link,headers=headers).content
tree=lxml.html.fromstring(beautiful)
sel=CSSSelector('div div table tr td a')
results=sel(tree)
m=5
while m <85:
match=results[m]if results[m-4].text=='XXX:
daf=match.get('href')
c='webaddress2'+str(daf)if requests.get(c).status_code==500:
f.write('Cannot found!')
f.write('\n')else:
beautiful1=requests.get(c).content
tree1=lxml.html.fromstring(beautiful1)
sel1=CSSSelector('div[id="project_div2"] table tr td')
results1=sel1(tree1)
p=2
while (p<20):
match1=results1[p]
mm=match1.textif mm isNone:
f.write('NoValue')else:
f.write(mm)
f.write(' ')
p=p+2sel2=CSSSelector('div[id="xiugai"] table tr')
sel3=CSSSelector('div[id="xiugai"] table tr td')
results2=sel2(tree1)
results3=sel3(tree1)
ee=len(results3)
q=2
while (q
nn1=results3[q].text
nn2=results3[q+1].text
nn3=results3[q-1].text
nn4=results3[q-2].text
f.write(nn4)
f.write(',')
f.write(nn3)
f.write(',')
f.write(nn1)
f.write(',')
f.write(nn2)
f.write(';')
q=q+4f.write('\n')
m=m+8j=j+1f.close()
问题:1. Python中如何安装库。
解决方法:cmd,cd 定位到Python安装目录相应文件夹,再用easy install或者 pip命令进行安装
cd C:\Python36-32\Scripts
pip install lxml
2. urllib使用。
2.x版本的Python可以直接使用import urllib来进行操作,但是3.x版本的python使用的是import urllib.request来进行操作
beautiful = urllib.request.urlopen(webaddress).read()
3. urllib vs. requests
使用urllib,网页读取不稳定,时常很快断连接。改用requests。
beautiful = requests.get(webaddress).content
4. beautiful soup爬网速度太慢。查询文档,换用lxml,速度改善不明显
之前
soup=bs4.BeautifulSoup(beautiful,"html.parser")
之后
soup=bs4.BeautifulSoup(beautiful,"lxml")
5.根据网上查询(http://blog.csdn.net/my_precious/article/details/52948362), 为了测试速度,完全弃用beautiful soup,使用lxml和CSSSelector
importlxml.htmlfrom lxml.cssselect importCSSSelector
tree=lxml.html.fromstring(beautiful)
sel=CSSSelector('div div table tr td a')
results=sel(tree)
match=results[m]
daf=match.get('href')
daf1=match[1].text
6. 读取50+页面时,遭遇10054错误,链接断开。
requests.exceptions.ConnectionError: ('Connection aborted.', ConnectionResetError(10054, '远程主机强迫关闭了一个现有的连接。', None, 10054, None))
解决方法:添加header,讲referer设为网站自身地址,避免网站误以为网站攻击
headers={'User-Agent':'Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US; rv:1.9.1.6) Gecko/20091201 Firefox/3.5.6','referer':'link'}
beautiful= requests.get(link,headers=headers).content
感受: Python大小写敏感,缩进格式要求严格。














 999
999











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









