






转载自:凹凸数据,作者Rilke Yang
原文链接: https://www. kesci.com/home/project/ 5f06b0193af6a6002d0fa357
这是一篇我关于滴滴的数据实战,之前首发在和鲸,这次投稿到凹凸数据,希望能够帮助到大家~
原文链接:https://www.kesci.com/home/project/5f06b0193af6a6002d0fa357
随着企业日常经营活动的进行,企业内部必然产生了各式各样的数据,如何利用这些数据得出有益的见解,并支持我们下一步的产品迭代以及领导决策就显得尤为重要。
A/B测试是互联网企业常用的一种基于数据的产品迭代方法,它的主要思想是在控制其他条件不变的前提下对不同(或同一、同质)样本设计不同实验水平(方案),并根据最终的数据变现来判断自变量对因变量的影响;A/B测试的理论基础主要源于数理统计中的假设检验部分,此部分统计学知识读者可自行探索。
长话短说,本次实战用到的数据集分为两个Excel文件,其中test.xlsx为滴滴出行某次A/B测试结果数据,city.xlsx为某城市运营数据。
数据说明
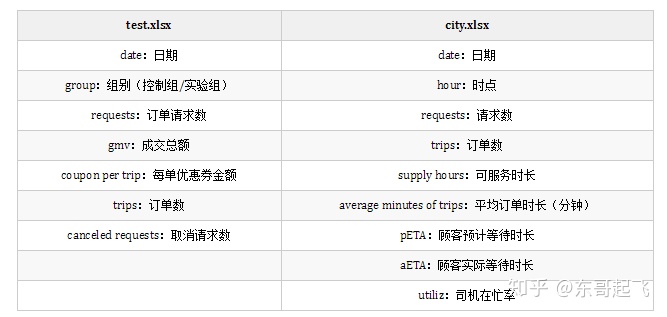
test.xlsx 数据可以用来判断实验条件对此次A/B测试的结果影响是否显著;city.xlsx 数据可以用来探索该城市运营中出现的问题,根据关键结论辅助决策。
在本文中,我们将使用该数据来做A/B测试效果分析与城市运营分析。
一、A/B测试效果分析
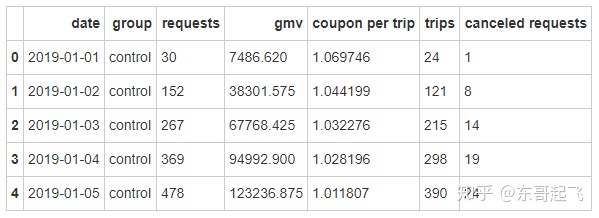
1、数据导入
#A/B测试结果数据导入
2、计算ROI
#计算优惠券投入相对gmv的ROI
test['ROI']=test['gmv']/(test['coupon per trip']*test['trips'])
test.head()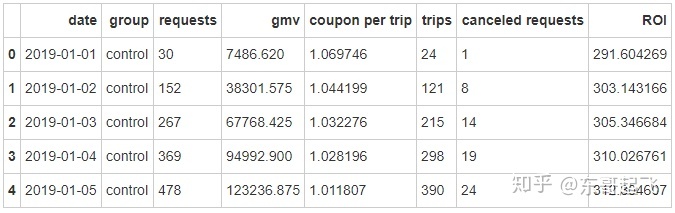
3、requests检验
数据共58条,对照组与实验组各29条,样本量<30。
3.1 requests方差检验
- 记两组requests方差分别为从c1,c2
- 零假设H0:c1=c2;备选假设:H1:c1≠c2
- 显著性水平取0.05
#levene检验requests是否齐方差
requests_A=test[test.group=='control'].requests
requests_B=test[test.group=='experiment'].requests
import scipy.stats as st
st.levene(requests_A,requests_B)
p值大于0.05,不拒绝原假设,因此可认为两组实验requests齐方差。
3.2 requests均值检验
- 该数据为同一样本实验前后的不同水平,因此选用配对样本t检验。
- 记两组requests均值分别为从u1,u2
- 零假设H0:u1=u2;备选假设:H1:u1≠u2
- 显著性水平取0.05
#配对样本t检验(两独立样本t检验之前需检验是否齐方差,此处不需要)
st.ttest_rel(requests_A,requests_B)
p值大于0.05,不拒绝原假设,因此可认为实验条件对requests影响不显著。
4、gmv检验
4.1 gmv方差检验
#levene检验gmv是否齐方差
gmv_A=test[test.group=='control'].gmv
gmv_B=test[test.group=='experiment'].gmv
st.levene(gmv_A,gmv_B)
p值大于0.05,不拒绝原假设,因此可认为两组实验gmv齐方差。
4.2 gmv均值检验
#配对样本t检验(两独立样本t检验之前需检验是否齐方差,此处不需要)
st.ttest_rel(gmv_A,gmv_B)
p值小于0.05,拒绝原假设,因此可认为实验条件对gmv有显著影响。
5、ROI检验
5.1 ROI方差检验
#levene检验ROI是否齐方差
ROI_A=test[test.group=='control'].ROI
ROI_B=test[test.group=='experiment'].ROI
st.levene(ROI_A,ROI_B)
p值大于0.05,不拒绝原假设,因此可认为两组实验ROI齐方差。
5.2 ROI均值检验
#配对样本t检验(两独立样本t检验之前需检验是否齐方差,此处不需要)
st.ttest_rel(ROI_A,ROI_B)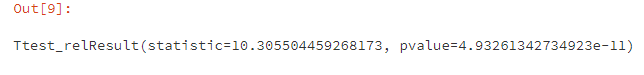
p值小于0.05,拒绝原假设,因此可认为实验条件对ROI有显著影响。

二、城市运营分析
1、数据导入
#导入该城市运营相关数据
city = pd.read_excel('/home/kesci/input/didi4010/city.xlsx')
city.head()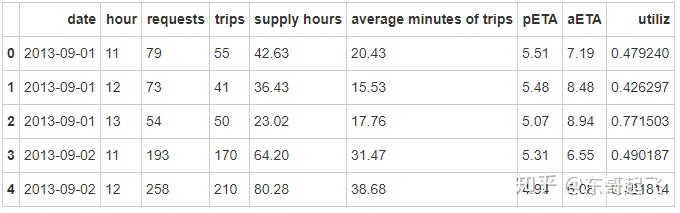
#查看数据有无缺失值
city.info()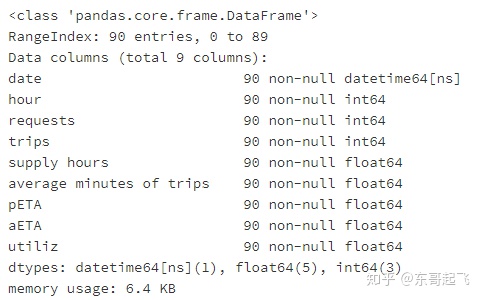
2、数据探索
2.1 单量最多的时间点
req_hour = city.groupby(['hour'],as_index=True).agg({'requests':sum},inplace=True)
req_hour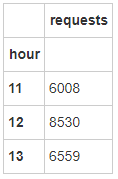
#绘制各时点订单请求柱状图
import matplotlib.pyplot as plt
req_hour.plot(kind='bar')
plt.xticks(rotation=0)
plt.show()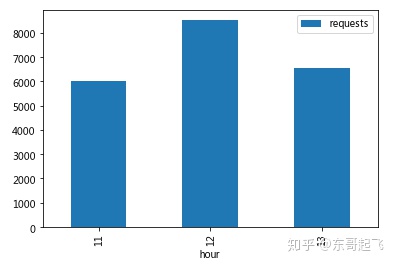
可见,在11、12、13这三个时间点内,12点用户发起订单的需求是最大的,其次是13点,11点。
司机运营平台应考虑加大该时点车辆供应。
2.2 单量最多的日期
req_date = city.groupby(['date'],as_index=True).agg({'requests':sum},inplace=True)
req_date.sort_values('date').head()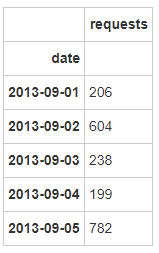
#绘制订单请求数随日期变化的折线图
req_date.plot(kind='line')
plt.show()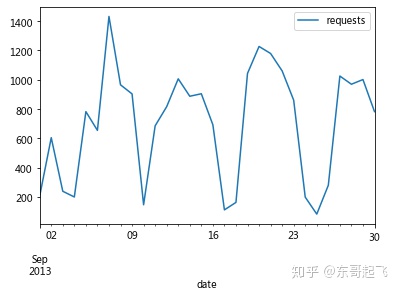
单月订单请求数随日期的变化呈周期性变化,我们猜测4个峰值分别对应4个周末,周末用户出行需求较大。
经验证发现猜想与数据吻合,因此司机运营平台应考虑加大周末、节假日的车辆供给。
2.3 各时段订单完成率
com_hour = city.groupby(['hour'],as_index=False).agg({'requests':sum,'trips':sum},inplace=True)
com_hour['rate']=com_hour['trips']/com_hour['requests']
com_hour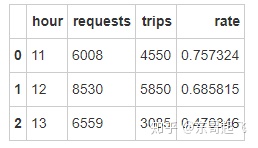
13点订单需求较多,但订单完成率仅47%,说明较多订单没有得到及时相应。
客运部应重点关注13点订单相应时长,排查具体原因。
2.4 单月每日订单完成率
com_date = city.groupby(['date'],as_index=True).agg({'requests':sum,'trips':sum},inplace=True)
com_date['rate']=com_date['trips']/com_date['requests']
com_date.sort_values('date').head()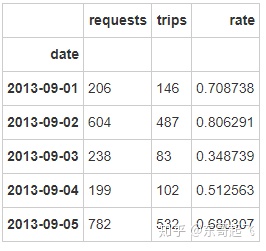
#绘制订单完成率随日期变化的折线图
com_date.rate.plot(kind='line')
plt.show()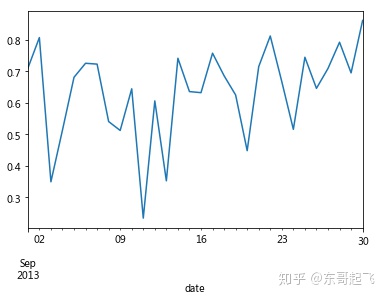
单月每日订单完成率规律不太明显,但几个谷值基本都出现在周末附近,说明客户出行需求的提升可能导致响应率的降低。
2.5 顾客等待时间
import numpy as np
eta_hour = city.groupby(['hour'],as_index=True).agg({'pETA':np.mean,'aETA':np.mean},inplace=True)
eta_hour
#绘制顾客等待时长复合柱状图
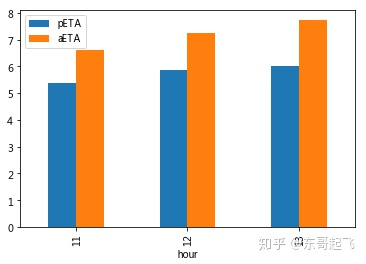
以上可见,无论哪个时点,用户实际等待时长均明显大于用户预计等待时长。
各时点用户等待时长差异不明显,但13点最高。
客运部一方面应提升用户预计等待时长的准确性,另一方面优化平台派单逻辑等。
2.6 司机在忙率
city['busy'] = city['supply hours']*city['utiliz']
city.head()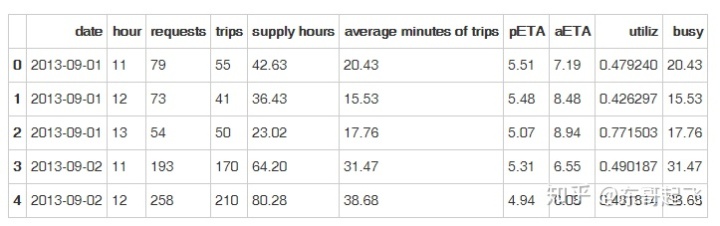
busy_hour = city.groupby(['hour'],as_index=False).agg({'supply hours':sum,'busy':sum})
busy_hour['utiliz'] = busy_hour['busy']/busy_hour['supply hours']
busy_hour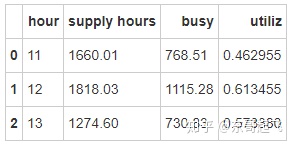
12点司机在忙总时长最长,在忙率也最高,用户订单请求也最多,说明车辆总数偏少。
2.7 订单时长
trip_min = city.groupby(['hour'],as_index=False).agg({'average minutes of trips':np.mean})
trip_min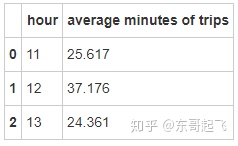
12点用户订单需求较多,同时订单时长最长,说明这个时间点是一个非常重要的时间点。
supply_hour = city.groupby(['hour'],as_index=False).agg({'supply hours':np.mean})
supply_hour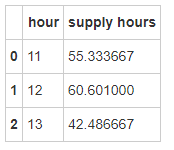
13点订单量也较大,此时点司机服务时长较短。
为优化用户出行体验,司机运营平台可联合客运部可考虑此时段尽量分配总服务时长较长的司机来接单(经验较为丰富)。
3、后续思考方向:
- 提升顾客预计等待时长预测准确度(需要历史数据进行预测)
- 加大车辆投入(分车辆不同等级来看,因此可能需要车辆相关信息表)
- 优化用户体验(需要客诉相关数据)
- 优化平台派单逻辑(需要订单的位置相关数据)
- 个性化需求(需要用户属性、及其他行为数据)
先分享这些,如果觉得有帮助,还请多分享和点个赞。
欢迎大家关注我的原创微信公众号 Python数据科学,专注于写基于Python的数据算法、机器学习、深度学习硬核干货。















 679
679











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









