






不可否认的是python的统计功能若于R和SAS,但对于常见的统计分析,python亦可以实现。本文介绍Python中的ggplot2绘图库:plotnine,使用python完成常见的统计描述、分布差异检验、相关分析和回归分析方法。
# plotnine:python中的ggplot2
import plotnine as pn
from plotnine import data
import numpy as np
import pandas as pd
# 统计分析
from scipy import stats
import statsmodels.api as sm
from statsmodels.formula.api import ols, glm, poisson
import copy
# 阻止pandas产生warnings(提示DataFrame的相关操作生成引用or副本)
import warnings
warnings.filterwarnings("ignore")
# jupyter中同一个cell的多个结果均自动输出,不需挨个手工print
from IPython.core.interactiveshell import InteractiveShell
InteractiveShell.ast_node_interactivity = "all"使用 plotnine 库自带的 mtcars 汽车数据集
选取 mtcars 的子集 df,共 32 个记录,6 个变量
df = data.mtcars[["wt", "mpg", "cyl", "vs", "am", "gear"]]
df.shape
df.dtypes
print(df.head())
(32, 6)
wt float64
mpg float64
cyl int64
vs int64
am int64
gear int64
dtype: object
wt mpg cyl vs am gear
0 2.620 21.0 6 0 1 4
1 2.875 21.0 6 0 1 4
2 2.320 22.8 4 1 1 4
3 3.215 21.4 6 1 0 3
4 3.440 18.7 8 0 0 3将变量 vs、am、gear 由数值型连续变量转为字符型分类变量
df["vs"] = df["vs"].astype(str)
df["am"] = df["am"].astype(str)
df["gear"] = df["gear"].astype(str)
df.dtypes
wt float64
mpg float64
cyl int64
vs object
am object
gear object
dtype: object变量分布
# 连续变量的常见分布统计量
print(df.describe())
# 分类变量的类别及频数
df["vs"].value_counts()
df["am"].value_counts()
df["gear"].value_counts()
wt mpg cyl
count 32.000000 32.000000 32.000000
mean 3.217250 20.090625 6.187500
std 0.978457 6.026948 1.785922
min 1.513000 10.400000 4.000000
25% 2.581250 15.425000 4.000000
50% 3.325000 19.200000 6.000000
75% 3.610000 22.800000 8.000000
max 5.424000 33.900000 8.000000
0 18
1 14
Name: vs, dtype: int64
0 19
1 13
Name: am, dtype: int64
3 15
4 12
5 5
Name: gear, dtype: int64plotnine 绘图
plotnine 是 python 的一个绘图库,模仿了 ggplot2 的语法和绘图样式,如果熟悉 R 的 ggplot2,那么该库可快速上手。 官方文档
该库与 R 的 ggplot2 使用中主要有以下 2 点不同:
ggplot()的 mapping 参数,R 中写为aes(x = mpg, y = wt),plotnine 写为aes(x="mpg", y="wt")- plotnine 要求整个绘图语句为一个语句,若中间需要换行,需要使用
连接或者语句首尾加括号
以下是几个简单的例子
散点图 + 回归线
pn.ggplot(data = df, mapping=pn.aes(x="mpg", y="wt")) +
pn.geom_point() +
pn.geom_smooth(method="lm") +
pn.theme_classic()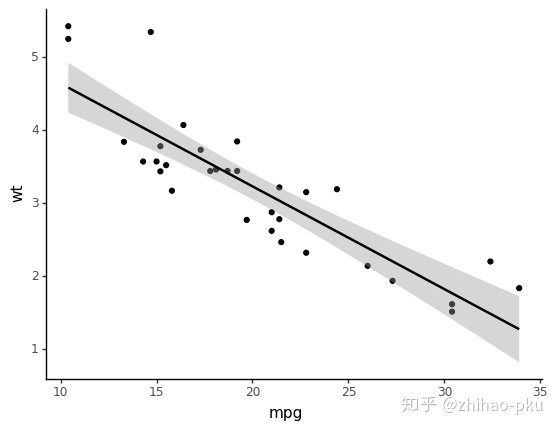
<ggplot: (-9223371901789411352)>分组
按照 vs 分组,分别绘制散点图、回归线及其 95% 置信区间
pn.ggplot(data = df, mapping=pn.aes(x="mpg", y="wt", color="vs")) +
pn.geom_point() +
pn.geom_smooth(method="lm") +
pn.theme_classic()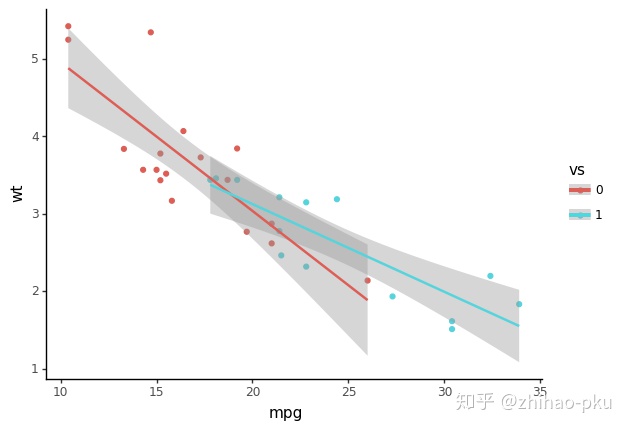
<ggplot: (-9223371901789391480)>分面(xkcd 主题)
按照变量 vs 和 gear 进行分面
pn.ggplot(data = df, mapping=pn.aes(x="mpg", y="wt")) +
pn.facet_grid("vs ~ gear") +
pn.geom_point() +
pn.geom_smooth(method="lm") +
pn.theme_xkcd()
<ggplot: (-9223371901789166508)>描述性统计量
各变量的缺失值
df.apply(lambda x: sum(x.isnull())).sort_values()
wt 0
mpg 0
cyl 0
vs 0
am 0
gear 0
count 0
dtype: int64连续变量和分类变量的分布信息
print(df.describe())
# count:分类变量非缺失值的数量
# unique:分类变量唯一值的数量
# top:分类变量中出现频次最高的数
# freq:分类变量中出现频次最高的数出现了几次
print(df.describe(include="object"))
wt mpg cyl
count 32.000000 32.000000 32.000000
mean 3.217250 20.090625 6.187500
std 0.978457 6.026948 1.785922
min 1.513000 10.400000 4.000000
25% 2.581250 15.425000 4.000000
50% 3.325000 19.200000 6.000000
75% 3.610000 22.800000 8.000000
max 5.424000 33.900000 8.000000
vs am gear
count 32 32 32
unique 2 2 3
top 0 0 3
freq 18 19 15
# 频次
df["vs"].value_counts()
# 构成比
df["vs"].value_counts(normalize=True)
0 18
1 14
Name: vs, dtype: int64
0 0.5625
1 0.4375
Name: vs, dtype: float64其他描述性统计量
# 方差
np.var(df["wt"])
# 标准差
np.std(df["wt"])
0.927460875
0.9630477013107918
# 众数
stats.mode(df["wt"])
ModeResult(mode=array([3.44]), count=array([3]))
# 偏度
stats.skew(df["wt"])
0.44378553550607736
# 峰度
stats.kurtosis(df["wt"])
0.1724705401587343正态分布样本均值的标准差(即标准误)及其 95% 置信区间
# 标准误
se = np.std(df["wt"]) / np.sqrt(len(df["wt"]))
se
# 区间上下限
np.mean(df["wt"]) - 1.96 * se
np.mean(df["wt"]) + 1.96 * se
0.17024439005074438
2.883570995500541
3.550929004499459统计学检验
正态性检验
p = 0.09,在 0.05 的显著性水平下接受原假设,即未发现变量 wt 不符合正态分布
stats.shapiro(df["wt"])
ShapiroResult(statistic=0.9432578682899475, pvalue=0.09265592694282532)两独立样本均值 t 检验
p = 0.38,未发现方差不齐
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 2892
2892











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









