





本文翻译自:https://www.freetype.org/freetype2/docs/tutorial/step2.html#section-1
由于本人才疏学浅,翻译难免有误,望各位不吝惜指正。
1.字符度量
字符度量信息,是单个字符在渲染时需要用到的布局信息。
度量信息分为垂直和水平两套。但通常只有少数字体提供垂直度量信息。我们可以使用FreeType库的FT_HAS_VERTICAL宏来检测字体是否包含垂直度量信息。
每个独立的字符可以在被载入后,通过face->glyph->metrics结构体访问其度量信息。
这一结构体(FT_Glyph_Metrics)包含以下这些成员:
- width:字符图像包围盒的宽度,独立于布局方向。
- height:字符图像包围盒的高度,独立于布局方向。注意不要将其与FT_Size_Metrics结构体的height成员搞混。
- horiBearingX:用于水平布局,代表从游标位置到字符图像包围盒左边框的距离。
- horiBearingY:用于水平布局,代表从游标位置到字符图像包围盒上边框的距离。
- horiAdvance:用于水平布局,代表字符被作为字符串的一部分绘制时,游标从该字符移动到下一个字符所需的距离。
- vertBearingX:用于垂直布局,代表从游标位置到字符图像包围盒左边框的距离。
- vertBearingY:用于垂直布局,代表从游标位置到字符图像包围盒上边框的距离。
- vertAdvance:用于垂直布局,代表字符被作为字符串的一部分绘制时,游标从该字符移动到下一个字符所需的距离。
由于并不是所有字体都包含垂直布局,所以在使用垂直布局信息前,应该使用FT_HAS_VERTICAL宏确定字体是否包含垂直布局信息。
读者可以结合下面的图示理解结构体中每个成员的意义。需要注意的是,这里的距离是带符号的有向距离。
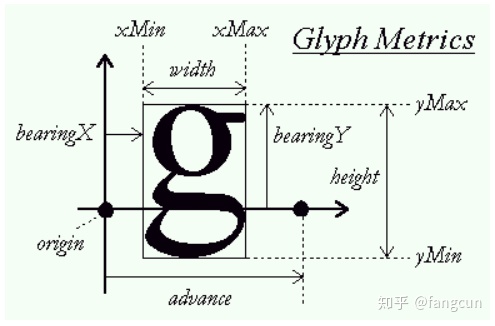
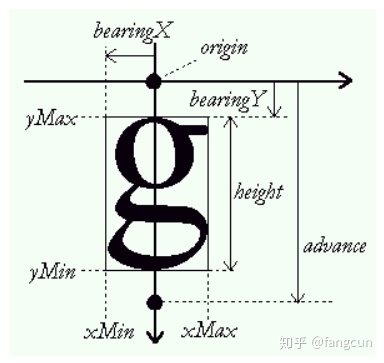
face->glyph->metrics的度量单位通常是26.6像素格式,如果使用FT_LOAD_NO_SCALE标记调用FT_Load_Glyph或FT_Load_Char函数,则使用字体原始的度量单位。
face->glypy成员还包含了下面这些成员:
- advance:FT_Vector类型,如果读者使用了FT_Set_Transform函数进行变换,这一成员包含了变换后的字符advance,如果没有进行变换,该成员的值为(metrics.horiAdvance,0),如果载入字符图像时使用了FT_LOAD_VERTICL标记,该成员值为(0,metrics.vertAdvance)。
- linearHoriAdvance:这一成员包含了线性缩放后的字符horiAdvance值。实际上,metrics.horiAdvance的值在字符载入时被取整到整数像素坐标(通过乘以64)。linerHoriAdvance的值是一个16.16定点数,它以1/65536像素为单位给出字符的advance大小。可以使用它来实现设备无关的文本布局。
- linearVertAdvance:和linerHoriAdvance成员类似,但定义的是字符的垂直advance大小。只有在字体包含垂直布局信息时可用。
2.字符管理
在载入字符时使用FT_LOAD_RENDER标记,或是主动调用FT_Render_Glyph函数可以生成一个字符位图。每一次载入新的字符,之前生成的字符位图就会被清除。
有时,我们可能想要导出字符进行缓存,以及在生成字符位图之前对字符位图进行变换和度量。
FreeType 2 API包含了一个扩展,可以灵活地处理字符。使用这一扩展需要包含FT_GLYPH_H头文件:
#include FT_GLYPH_H
a.导出字符
导出字符非常简单,下面是示例代码:
FT_Glyph glyph; /* a handle to the glyph image */
...
error = FT_Load_Glyph( face, glyph_index, FT_LOAD_NORMAL );
if ( error ) { ... }
error = FT_Get_Glyph( face->glyph, &glyph );
if ( error ) { ... }
代码执行了以下步骤:
- 创建了一个类型为FT_Glyph的变量glyph,这是一个可以指向独立字符的句柄。
- 载入字符(这里我们想要得到一个可以在之后进行变换的字符,所以没有使用FT_LOAD_RENDER标记)
- 调用FT_GET_Glyph函数导出字符。
导出的字符格式和原来的字符格式相同。从TrueType字体载入的字符,它的字符实际上是一个矢量轮廓。我们可以通过glyph->format来确定字符图像的格式。
通过调用FG_Done_Glyph函数可以销毁字符。
一个字符包含了一个字符图像和一个表示字符advance的二维向量(在16.16定点像素坐标系下)。后者可以通过glyph->advance访问。
需要注意的是FreeType并没有维护它所分配的字符列表,需要我们在不需要时手动调用FT_Done_Glyph来销毁字符。
b.变换和复制字符
如果字符的格式是scalable(glyph->format的值为FT_GLYPH_FORMAT_BITMAP),我们就可以在任意时间调用FT_Glyph_Transform函数来对字符进行变换操作。
我们也可以通过调用FT_Glyph_Copy函数复制单个字符。
FT_Glyph glyph, glyph2;
FT_Matrix matrix;
FT_Vector delta;
... load glyph image in `glyph' ...
/* copy glyph to glyph2 */
error = FT_Glyph_Copy( glyph, &glyph2 );
if ( error ) { ... could not copy (out of memory) ... }
/* translate `glyph' */
delta.x = -100 * 64; /* coordinates are in 26.6 pixel format */
delta.y = 50 * 64;
FT_Glyph_Transform( glyph, 0, &delta );
/* transform glyph2 (horizontal shear) */
matrix.xx = 0x10000L;
matrix.xy = 0.12 * 0x10000L;
matrix.yx = 0;
matrix.yy = 0x10000L;
FT_Glyph_Transform( glyph2, &matrix, 0 );
2x2变换矩阵同时被应用在字符的16.16定点像素坐标advance上,所以不需要我们重新计算它。
c.度量字符
我们可以通过调用FT_Glyph_Get_CBox函数获取字符的包围盒:
FT_BBox bbox;
...
FT_Glyph_Get_CBox( glyph, bbox_mode, &bbox );
获取的包围盒的坐标是基于字符原点,y轴朝上的坐标。FT_Glyph_Get_CBox函数带有一个参数bbox_mode,用于指示如何表示包围盒坐标。
如果在载入字符时使用了FT_LOAD_NO_SCALE标记,bbox_mode必须设置为FT_GLYPH_BBOX_UNSCALED才能获取26.6像素格式的未缩放字符。FT_GLYPH_BBOX_SUBPIXELS和FT_GLYPH_BBOX_UNSCALED等价。
我们可以通过字符包围盒的xMax和xMin,以及yMax和yMin来计算字符大小:
width = bbox.xMax - bbox.xMin;
height = bbox.yMax - bbox.yMin;
需要注意的是计算出的包围盒大小是在26.6像素坐标下。如果使用了FT_GLYPH_BBOX_GRIDFIT标记作为bbox_mode,包围盒的坐标会被网格化,等价于使用了下面的代码:
bbox.xMin = FLOOR( bbox.xMin )
bbox.yMin = FLOOR( bbox.yMin )
bbox.xMax = CEILING( bbox.xMax )
bbox.yMax = CEILING( bbox.yMax )
可以将bbox_mode设置为FT_GLYPH_BBOX_TRUNCATE,来让包围盒的坐标以整数像素坐标的形式表示。
为了得到网格化的像素坐标,需要将bbox_mode设置为FT_GLYPH_BBOX_PIXELS。
如果想要得到更加精确的包围盒,可以使用FT_Outline_Get_BBox函数,但这一函数计算代价较高。通常,除非要对字符进行旋转,我们很少使用这一函数。
d.转换字符到一个位图
在缓存或变换字符之后,我们可能要将字符生成位图来方便使用,这可以通过调用FT_Glyph_To_Bitmap函数实现:
FT_Vector origin;
origin.x = 32; /* 1/2 pixel in 26.6 format */
origin.y = 0;
error = FT_Glyph_To_Bitmap(
&glyph,
render_mode,
&origin,
1 ); /* destroy original i
需要特别注意的地方:
- 函数的第一个参数是字符句柄。当函数被调用时,它会读取给定字符,然后在函数返回前返回一个包含位图的新的字符。
- 函数的第二个参数用来指定使用的渲染模式。它可以是FT_RENDER_MODE_DEFAULT,用于渲染8位反走样字符位图,也可以是FT_RENDER_MODE_MONO,用于渲染1位的黑白字符位图。
- 函数的第三个参数是一个指向用于在生成位图前平移字符的二维向量的指针。在函数调用后,字符位置会被还原回原位置,如果不需要在渲染位图前平移字符,将其设置为NULL即可。
- 函数的最后一个参数是一个指示源字符是否在函数调用后被销毁的布尔量。如果设置为false,源字符在函数调用后不会被销毁。
调用函数产生的新的字符包含了一个位图,为了访问这个位图,我们需要将字符变量的类型强制转换到FT_BitmapGlyph类型,这一类型相对于FT_Glyph额外包含了下面这些成员:
- left:和glyph的bitmap_left成员相同,是从字符原点到字符位图最左像素的距离,以整数像素为单位。
- top:和glyph的bitmap_top成员相同,是从字符原点到字符位图顶部像素的距离,以整数像素为单位,坐标系y轴朝上。
- bitmap:描述位图的结构体成员,和glyph的bitmap成员相同。
3.全局字符度量
全局字符度量被用来描述整个字体的度量信息。这些度量信息可以以26.6像素格式表示,对于可缩放格式也可以用未缩放的字体单位表示。
a.全局设计度量
对于可缩放格式,为了更好地在之后缩放到设备空间,所有全局度量信息以字体单位进行表示。
我们可以通过FT_IS_SCALABLE宏检测字体格式是否是可缩放格式。
下面是可缩放格式包含的全局设计度量信息:
- units_per_EM:字体的EM大小。被用在可缩放格式字体来缩放设计坐标到设备像素坐标。对于TrueType字体,它的值通常是2048,对于Type1或CFF字体,它的值通常是1000。当然也可能是其它值。对于固定大小的字体比如FNT,FON,PCF和BDF,它的值通常是1。
- bbox:可以包括字体所有字符的全局包围盒。
- ascender:ascender是从水平基线到字体最高的字符的顶部的距离。但不同字体对ascender的定义不统一,有些格式,它使用所有大写拉丁字母的上部(不包含重音字母)进行定义,有些使用最高的重音字母的上部进行定义,还有些格式它的值和bbox.yMax相同。
- descender:descender是从水平基线到底部最低的字符的底部的距离。同样,不同字体对descender的定义并不统一,有些格式它使用所有大写拉丁字母的下部(不包含重音字母)进行定义,有些格式,它使用底部最低的重音字母的下部进行定义,还有些格式它的值和bbox.yMin相同。当低于水平基线时,它的值为负数。
- height:它表示默认的行高(水平基线到水平基线之间的距离)。通常,它的值大于ascender和descender的绝对值之和。这一值并不保证字体的所有字符一定位于这一高度范围内,可以认为这个值是字体设计者认为的合理的行高。
- max_advance_width:用于水平布局,这一成员表示字体所有字符的最大水平光标移动距离。可以使用它来快速计算文本的最大宽度。但它并不代表字体中最大字符的宽度。
- max_advance_height:用于垂直布局,和max_advance_height的意义相同。
- underline_position:用于渲染带有下划线的文本,这个值表示下划线相对于水平基线的距离,当下划线在水平基线下方时,它的值为负数。
- underline_thickness:用于渲染带有下划线的文本,这个值表示下划线的厚度。
需要注意的是,这里的ascender和descender的值因为不同字体的定义不同,很不可靠。
b.缩放后的全局度量
每个size对象包含了上面描述全局度量信息的缩放版本,可以通过face->size->metrics来访问缩放后的度量信息。这些缩放后的度量信息没有进行网格化,也没有进行任何的hinting处理。如果要保证像素级别的精度,我们不应该使用这些度量信息。这些度量信息以26.6像素格式表示,但由于历史原因进行了取整处理。
- ascender:设计ascender的缩放版本,经过向上取整。
- descender:设计descender的缩放版本,经过向下取整。
- height:设计height的缩放版本,大概是这一结构体,我们惟一会使用的度量信息,经过取整处理。
- max_advance:设计max_advance的缩放版本,经过取整处理。
此外,face->size->metrics结构体还包含了其它一些用于缩放设计坐标到设备空间的成员,我们会在之后介绍。
c.Kerning
Kerning值是用来调整文本中连续两个字符的间距。比如,大写字母A和大写字母V之间,可以通过Kerning值来减少间距,让文本渲染效果看上去更好。
虽然理论上,可以在水平和垂直两个方向上都使用Kerning,但大多数场景下,只会在一个方向上使用Kerning。
并非所有字体格式都包含那Kerning信息,并且并非所有字体格式的Kerning信息被FreeType所支持。对于TrueType字体,FreeType库只能访问kern表中的kerning信息。GPOS表中的kerning信息不被FreeType库支持。如果要使用GPOS表中的kernning信息,应该使用HarfBuzz,Pango或ICU这类更高级的库。
有些字体会使用一个附加的文件来提供字符度量信息。比如Type1格式的字体将字形信息存储在.pfa或.pfb文件中,将kerning信息存储在.afm或.pfm文件中。
我们可以通过FreeType库提供的FT_Attach_File或FT_Attach_Stream函数来使用附加的字体度量信息。下面是一个使用示例:
error = FT_New_Face( library, "/usr/share/fonts/cour.pfb",
0, &face );
if ( error ) { ... }
error = FT_Attach_File( face, "/usr/share/fonts/cour.afm" );
if ( error )
{ ... could not read kerning and additional metrics ... }
FT_Attach_Stream函数的使用和FT_Attach_File函数类似。
这两个API可以载入字体任意类型的附加文件,而不仅仅是度量信息。
载入度量信息后,我们可以通过调用FT_Get_Kerning函数获取kerning信息:
FT_Vector kerning;
...
error = FT_Get_Kerning( face, /* handle to face object */
left, /* left glyph index */
right, /* right glyph index */
kerning_mode, /* kerning mode */
&kerning ); /* target vector */
这一函数通过指定需要kerning信息的左右两个字符来获取kerning。
这里的kerning_mode参数和之前我们见到的bbox_mode参数非常类似,它用于指定kerning值的表示方式。
kerning_mode的默认值是FT_KERNING_DEFAULT,表示使用26.6网格化像素方式表示kerning值。对于可缩放格式,这表示对设计kerning值进行缩放,然后取整得到kerning值。
kerning_mode的值设置为FT_KERNING_UNFITTED表示使用26.6未像素化(不对应整数坐标值)方式表示kerning值。这时的kerning值是对设计kerning值进行缩放,而不进行取整处理得到的。
kerning_mode的值设置为FT_KERNING_UNSCALED,返回使用字体单位表示的设计kerning。
这里的left和right字符对应文本串中的连续两个字符,特别注意这点在left to right和right to left文本串的不同。
4.简易文本渲染:Kerning和居中
接下来,我们演示如何通过度量信息来更好地渲染文本串。
a.Kerning支持
我们这里按照left to right渲染文本串,通过获取文本串连续两个字符地kerning,来更好地布局文本串的字符:
FT_GlyphSlot slot = face->glyph; /* a small shortcut */
FT_UInt glyph_index;
FT_Bool use_kerning;
FT_UInt previous;
int pen_x, pen_y, n;
... initialize library ...
... create face object ...
... set character size ...
pen_x = 300;
pen_y = 200;
use_kerning = FT_HAS_KERNING( face );
previous = 0;
for ( n = 0; n < num_chars; n++ )
{
/* convert character code to glyph index */
glyph_index = FT_Get_Char_Index( face, text[n] );
/* retrieve kerning distance and move pen position */
if ( use_kerning && previous && glyph_index )
{
FT_Vector delta;
FT_Get_Kerning( face, previous, glyph_index,
FT_KERNING_DEFAULT, &delta );
pen_x += delta.x >> 6;
}
/* load glyph image into the slot (erase previous one) */
error = FT_Load_Glyph( face, glyph_index, FT_LOAD_RENDER );
if ( error )
continue; /* ignore errors */
/* now draw to our target surface */
my_draw_bitmap( &slot->bitmap,
pen_x + slot->bitmap_left,
pen_y - slot->bitmap_top );
/* increment pen position */
pen_x += slot->advance.x >> 6;
/* record current glyph index */
previous = glyph_index;
}
下面是对上面代码的详细解释:
- 由于kerning信息由字符索引确定,所以我们需要将字符编码转换为字符索引,然后调用FT_Load_Char函数来使用字符索引载入字符。
- 我们通过FT_HAS_KERNING宏检测字体是否包含kerning信息,如果字体不包含kerning信息,我们就不使用它。
- 我们在渲染下一个字符前,移动画笔。
- 我们将变量previous的值初始化为0,表示上一字符不存在,不需要处理kerning信息。
- 代码中,我们没有处理FT_Get_Kerning函数返回的错误代码,这是因为该函数发生错误时,会将delta的值设置为(0,0),刚好就是不存在kerning信息时,我们所需要的值。
b.居中
现在,让我们将文本渲染函数分解为两部分:第一部分定位每个字符在基线上的位置,第二部分渲染字符,这样做可以帮助我们实现一些较高级的布局,比如居中布局文本。
我们首先将每个字符,以及它们在基线上的位置存储起来:
FT_GlyphSlot slot = face->glyph; /* a small shortcut */
FT_UInt glyph_index;
FT_Bool use_kerning;
FT_UInt previous;
int pen_x, pen_y, n;
FT_Glyph glyphs[MAX_GLYPHS]; /* glyph image */
FT_Vector pos [MAX_GLYPHS]; /* glyph position */
FT_UInt num_glyphs;
... initialize library ...
... create face object ...
... set character size ...
pen_x = 0; /* start at (0,0) */
pen_y = 0;
num_glyphs = 0;
use_kerning = FT_HAS_KERNING( face );
previous = 0;
for ( n = 0; n < num_chars; n++ )
{
/* convert character code to glyph index */
glyph_index = FT_Get_Char_Index( face, text[n] );
/* retrieve kerning distance and move pen position */
if ( use_kerning && previous && glyph_index )
{
FT_Vector delta;
FT_Get_Kerning( face, previous, glyph_index,
FT_KERNING_DEFAULT, &delta );
pen_x += delta.x >> 6;
}
/* store current pen position */
pos[num_glyphs].x = pen_x;
pos[num_glyphs].y = pen_y;
/* load glyph image into the slot without rendering */
error = FT_Load_Glyph( face, glyph_index, FT_LOAD_DEFAULT );
if ( error )
continue; /* ignore errors, jump to next glyph */
/* extract glyph image and store it in our table */
error = FT_Get_Glyph( face->glyph, &glyphs[num_glyphs] );
if ( error )
continue; /* ignore errors, jump to next glyph */
/* increment pen position */
pen_x += slot->advance.x >> 6;
/* record current glyph index */
previous = glyph_index;
/* increment number of glyphs */
num_glyphs++;
}
代码中的pen_x包含了渲染整个文本串需要在x方向移动的距离。
我们现在可以使用下面的函数来计算整个文本串的包围盒:
void compute_string_bbox( FT_BBox *abbox )
{
FT_BBox bbox;
FT_BBox glyph_bbox;
/* initialize string bbox to "empty" values */
bbox.xMin = bbox.yMin = 32000;
bbox.xMax = bbox.yMax = -32000;
/* for each glyph image, compute its bounding box, */
/* translate it, and grow the string bbox */
for ( n = 0; n < num_glyphs; n++ )
{
FT_Glyph_Get_CBox( glyphs[n], ft_glyph_bbox_pixels,
&glyph_bbox );
glyph_bbox.xMin += pos[n].x;
glyph_bbox.xMax += pos[n].x;
glyph_bbox.yMin += pos[n].y;
glyph_bbox.yMax += pos[n].y;
if ( glyph_bbox.xMin < bbox.xMin )
bbox.xMin = glyph_bbox.xMin;
if ( glyph_bbox.yMin < bbox.yMin )
bbox.yMin = glyph_bbox.yMin;
if ( glyph_bbox.xMax > bbox.xMax )
bbox.xMax = glyph_bbox.xMax;
if ( glyph_bbox.yMax > bbox.yMax )
bbox.yMax = glyph_bbox.yMax;
}
/* check that we really grew the string bbox */
if ( bbox.xMin > bbox.xMax )
{
bbox.xMin = 0;
bbox.yMin = 0;
bbox.xMax = 0;
bbox.yMax = 0;
}
/* return string bbox */
*abbox = bbox;
}
我们计算的包围盒以整数像素为单位表示,使用包围盒的信息,我们就可以在渲染文本前得到画笔的最终坐标。
需要特别注意,上面的函数计算的包围盒并不是文本串的精确包围盒。如果字符进行了hinting,字符的尺寸必须从hinting后的字符轮廓得出。对于反走样pixmap,调用FT_Outline_Get_BBox可以获得这一轮廓的包围盒。对于1位的黑白位图,由于从字符轮廓转换到位图时也由hinting影响,所以必须先对字符进行渲染。
/* compute string dimensions in integer pixels */
string_width = string_bbox.xMax - string_bbox.xMin;
string_height = string_bbox.yMax - string_bbox.yMin;
/* compute start pen position in 26.6 Cartesian pixels */
start_x = ( ( my_target_width - string_width ) / 2 ) * 64;
start_y = ( ( my_target_height - string_height ) / 2 ) * 64;
for ( n = 0; n < num_glyphs; n++ )
{
FT_Glyph image;
FT_Vector pen;
image = glyphs[n];
pen.x = start_x + pos[n].x;
pen.y = start_y + pos[n].y;
error = FT_Glyph_To_Bitmap( &image, FT_RENDER_MODE_NORMAL,
&pen, 0 );
if ( !error )
{
FT_BitmapGlyph bit = (FT_BitmapGlyph)image;
my_draw_bitmap( bit->bitmap,
bit->left,
my_target_height - bit->top );
FT_Done_Glyph( image );
}
}
上面代码的一些注解:
- 画笔坐标以笛卡尔坐标的形式表示(y轴朝上)。
- 我们调用FT_Glyph_To_Bitmp函数时将destroy参数设置为0(false),从而避免FreeType库自动销毁字符。我们将字符通过强制类型转换转换到FT_BitmapGlyphy类型,然后访问字符的位图信息。
- 我们在调用FT_Glyph_To_Bitmap函数时使用了平移变换参数。这保证位图字符的left和top成员会被放在对应的像素坐标位置。
- 最后,我们还需要将像素坐标从笛卡尔空间转换到设备空间:my_target_height - bitmap->top in the call to my_draw_bitmap。
这样只需要载入每个字符一次,就可以使用上面代码在需要的地方渲染文本。
5.高级文本渲染:变换、居中和Kerning
接下来,我们演示一些较为高级的布局方式。
a.打包字符信息和平移字符
我们可以将一个字符相关的信息定义为一个结构体来方便使用。
typedef struct TGlyph_
{
FT_UInt index; /* glyph index */
FT_Vector pos; /* glyph origin on the baseline */
FT_Glyph image; /* glyph image */
} TGlyph, *PGlyph;
在载入字符到它的基线坐标后,我们就可以对字符进行平移。
FT_GlyphSlot slot = face->glyph; /* a small shortcut */
FT_UInt glyph_index;
FT_Bool use_kerning;
FT_UInt previous;
int pen_x, pen_y, n;
TGlyph glyphs[MAX_GLYPHS]; /* glyphs table */
PGlyph glyph; /* current glyph in table */
FT_UInt num_glyphs;
... initialize library ...
... create face object ...
... set character size ...
pen_x = 0; /* start at (0,0) */
pen_y = 0;
num_glyphs = 0;
use_kerning = FT_HAS_KERNING( face );
previous = 0;
glyph = glyphs;
for ( n = 0; n < num_chars; n++ )
{
glyph->index = FT_Get_Char_Index( face, text[n] );
if ( use_kerning && previous && glyph->index )
{
FT_Vector delta;
FT_Get_Kerning( face, previous, glyph->index,
FT_KERNING_MODE_DEFAULT, &delta );
pen_x += delta.x >> 6;
}
/* store current pen position */
glyph->pos.x = pen_x;
glyph->pos.y = pen_y;
error = FT_Load_Glyph( face, glyph_index, FT_LOAD_DEFAULT );
if ( error ) continue;
error = FT_Get_Glyph( face->glyph, &glyph->image );
if ( error ) continue;
/* translate the glyph image now */
FT_Glyph_Transform( glyph->image, 0, &glyph->pos );
pen_x += slot->advance.x >> 6;
previous = glyph->index;
/* increment number of glyphs */
glyph++;
}
/* count number of glyphs loaded */
num_glyphs = glyph - glyphs;
这样做后,我们就不需要在计算文本串包围盒时平移字符的包围盒。
void compute_string_bbox( FT_BBox *abbox )
{
FT_BBox bbox;
bbox.xMin = bbox.yMin = 32000;
bbox.xMax = bbox.yMax = -32000;
for ( n = 0; n < num_glyphs; n++ )
{
FT_BBox glyph_bbox;
FT_Glyph_Get_CBox( glyphs[n], ft_glyph_bbox_pixels,
&glyph_bbox );
if (glyph_bbox.xMin < bbox.xMin)
bbox.xMin = glyph_bbox.xMin;
if (glyph_bbox.yMin < bbox.yMin)
bbox.yMin = glyph_bbox.yMin;
if (glyph_bbox.xMax > bbox.xMax)
bbox.xMax = glyph_bbox.xMax;
if (glyph_bbox.yMax > bbox.yMax)
bbox.yMax = glyph_bbox.yMax;
}
if ( bbox.xMin > bbox.xMax )
{
bbox.xMin = 0;
bbox.yMin = 0;
bbox.xMax = 0;
bbox.yMax = 0;
}
*abbox = bbox;
}
现在我们的compute_string_bbox函数就可以使用变换后的字符包围盒来计算文本串包围盒,从而简化代码。
FT_BBox bbox;
FT_Matrix matrix;
FT_Vector delta;
... load glyph sequence ...
... set up `matrix' and `delta' ...
/* transform glyphs */
for ( n = 0; n < num_glyphs; n++ )
FT_Glyph_Transform( glyphs[n].image, &matrix, &delta );
/* compute bounding box of transformed glyphs */
compute_string_bbox( &bbox );
b.渲染变换后的字符序列
如果想要以不同的角度或变换操作渲染文本多次,对渲染后的字符进行变换不如在渲染字符前进行变换。
FT_Vector start;
FT_Matrix matrix;
FT_Glyph image;
FT_Vector pen;
FT_BBox bbox;
/* get bbox of original glyph sequence */
compute_string_bbox( &string_bbox );
/* compute string dimensions in integer pixels */
string_width = (string_bbox.xMax - string_bbox.xMin) / 64;
string_height = (string_bbox.yMax - string_bbox.yMin) / 64;
/* set up start position in 26.6 Cartesian space */
start.x = ( ( my_target_width - string_width ) / 2 ) * 64;
start.y = ( ( my_target_height - string_height ) / 2 ) * 64;
/* set up transform (a rotation here) */
matrix.xx = (FT_Fixed)( cos( angle ) * 0x10000L );
matrix.xy = (FT_Fixed)(-sin( angle ) * 0x10000L );
matrix.yx = (FT_Fixed)( sin( angle ) * 0x10000L );
matrix.yy = (FT_Fixed)( cos( angle ) * 0x10000L );
pen = start;
for ( n = 0; n < num_glyphs; n++ )
{
/* create a copy of the original glyph */
error = FT_Glyph_Copy( glyphs[n].image, &image );
if ( error ) continue;
/* transform copy (this will also translate it to the */
/* correct position */
FT_Glyph_Transform( image, &matrix, &pen );
/* check bounding box; if the transformed glyph image */
/* is not in our target surface, we can avoid rendering it */
FT_Glyph_Get_CBox( image, ft_glyph_bbox_pixels, &bbox );
if ( bbox.xMax <= 0 || bbox.xMin >= my_target_width ||
bbox.yMax <= 0 || bbox.yMin >= my_target_height )
continue;
/* convert glyph image to bitmap (destroy the glyph copy!) */
error = FT_Glyph_To_Bitmap(
&image,
FT_RENDER_MODE_NORMAL,
0, /* no additional translation */
1 ); /* destroy copy in "image" */
if ( !error )
{
FT_BitmapGlyph bit = (FT_BitmapGlyph)image;
my_draw_bitmap( bit->bitmap,
bit->left,
my_target_height - bit->top );
/* increment pen position -- */
/* we don't have access to a slot structure, */
/* so we have to use advances from glyph structure */
/* (which are in 16.16 fixed float format) */
pen.x += image.advance.x >> 10;
pen.y += image.advance.y >> 10;
FT_Done_Glyph( image );
}
}
相比之前的代码:
- 我们保持原来的字符不变,复制一个新的字符进行变换操作。
- 如果文本串变换后超出可渲染的范围,不进行渲染。
- 调用FT_Glyph_To_Bitmap函数,销毁之前复制的字符。需要注意如果FT_Glyph_To_Bitmap函数返回错误代码,就不会自动销毁之前的字符(这种情况下,我们调用FT_Done_Glyph来销毁字符)。
- 字符的变换操作通过调用FT_Glyph_Transform函数完成。
我们可以以不同角度,或改变start来移动文本调用这一函数进行文本渲染。
上面的代码基于FreeType 2的官方演示程序ftstring.c。我们可以很容易地只修改第一部分代码将其扩展来实现高级的文本布局,而不需要对第二部分代码作任何改变。
通常来说,所有实用程序都会将字符进行缓存来减少内存占用。比如,假设我们要渲染的文本串是"FreeType"。对于e这个字符,我们显然应该缓存起来。这还只是一个单词,考虑一篇文章的情况,节约的内存就非常可观了。
FreeType库给出了一个进行字符缓存的演示程序ftview.c。一般而言,应用程序开发者应该使用ftview来对它们自己的实现进行正确性验证。
FreeType库还给出了一个非常有用的演示程序ftdiff.c。该程序演示了使用不同的渲染和hinting模式产生的字体渲染效果。特别地,它也演示了如何进行次像素(用于未hinting字符和"light" hinting模式)定位(所有代码假定使用整数坐标)。
6.使用字体设计单位的度量信息进行缩放
可缩放字体格式通常会存储每个字符的向量轮廓。这一向量轮廓被定义在坐标以字体单位表示的抽象网格中。字符载入时,这一轮廓被字体驱动程序缩放到FT_Size定义的字符像素大小。字体驱动程序也可能对缩放后的轮廓进行修改来提升它在基于像素的设备上的渲染表现(比如进行hinting或网格化)。
本节主要介绍将设计坐标缩放到设备空间的方法,以及如何读取字符以字体单位表示的轮廓和度量信息。这对于下面这些工作非常重要:
- 真 所见即所得文本布局。
- 以转换和分析为目的访问字体。
a.缩放距离值到设备空间
将设计坐标缩放到设备空间非常容易,我们只需要知道像素在设计坐标下的大小就可以做到:
device_x = design_x * x_scale
device_y = design_y * y_scale
x_scale = pixel_size_x / EM_size
y_scale = pixel_size_y / EM_size
上面代码中的EM_size是特定于字体的,对应设计空间用于字体设计的抽象正方形大小,以字体单位表示。对于可缩放格式字体,可以通过face->units_per_EM来访问它。对于一个字体是否是可缩放的,可以使用FT_IS_SCALABLE宏进行检测。
调用FT_Set_Pixel_Sizes函数时,可以指定FreeType库使用的pixel_size_x和pixel_size_y的整数值。
调用FT_Set_Char_Size函数时,可以以设备的物理点数为大小指定字符大小。结合字符的物理点数大小和设备分辨率,FreeType库会计算出字符的像素大小和对应缩放系数。
在调用上面这两个函数后,我们可以通过face->size->metrics结构体来访问字符的像素大小和缩放系数:
- x_ppem:这一成员的全称是"x pixels per EM"。它表示水平方向1 EM的大小相当于x个像素大小,在上面的代码中也被叫做pixel_size_x。
- y_ppem:这一成员的全称是"y pixels per EM"。它表示垂直方向1 EM的大小相当于y个像素大小,在上面的代码中也被叫做pixel_size_y。
- x_scale:以16.16定点表示的缩放系数。用于将水平距离从设计空间缩放到1/64设备像素大小。
- y_scale:以16.16定点表示的缩放系数。用于将垂直距离从设计空间缩放到164设备像素大小。
我们可以使用FT_MulFix函数将一个距离值从字体单位表示转换到26.6像素格式表示:
/* convert design distances to 1/64th of pixels */
pixels_x = FT_MulFix( design_x, face->size->metrics.x_scale );
pixels_y = FT_MulFix( design_y, face->size->metrics.y_scale );
我们也可以使用双精度浮点数,手动进行这一缩放过程:
FT_Size_Metrics* metrics = &face->size->metrics; /* shortcut */
double pixels_x, pixels_y;
double x_scale, y_scale;
/* compute floating point scale factors */
x_scale = face->size->metrics.x_scale / 65536.0;
y_scale = face->size->metrics.y_scale / 65536.0;
/* convert design distances to floating point pixels */
pixels_x = design_x * x_scale;
pixels_y = design_y * y_scale;
b.访问设计度量(字符&全局)
我们可以在调用FT_Load_Glyph或FT_Load_Char函数时,指定FT_LOAD_NO_SCALE标记。这样face->glyph->metrics就会返回以字体单位表示的度量信息。
我们可以使用FT_KERNING_MODE_UNSCALED模式来访问未缩放的kerning数据。
总结
现在,读者可以利用度量信息,更快更好地进行文本渲染。
FreeType库的演示程序包ft2demos包含了一些文本渲染的实现代码,可供读者参考。
注
EM是一个字体度量单位,表示字体的单位大小。
26.6定点格式定义了一个分数像素坐标单位,1单位=1/64像素大小。
16.16定点格式定义了一个分数像素坐标单位,1单位=1/65536像素大小。
网格化是指修改字符轮廓来使字符轮廓和网格对齐。















 372
372











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









