






背景
当前软件开发中,绝大部分团队都已经实现了前后端分离,不过实施的过程中并不总是甜头,前端和后端的协作过程中总是会遇到让人头疼的问题。
比如,前端的同学正在全神贯注的调试着代码,突然后端把服务停了(测试环境把服务停掉太正常了,最常见的原因就是打包),接口调不通了,没办法,谁让前端需要用到测试环境的接口取数据呢,这个时候只能停下手中的活,等待后端服务再次启动,这个过程通常在几十秒到几分钟不等,这就要看后端服务启动要多久了(我见过最长的服务要启动200多秒的),一次两次还好,如果一天之中遇到这种问题十次八次,前端绝对要抓狂。
但是后端的同学可能也很委屈,我们也是在抓紧时间完成任务啊,测试提了一个bug需要赶紧修复,不然功能没法儿测了;新的需求开发好了,打到测试环境走一下完整流程;各种原因都有可能,总之也不能不动测试环境(也许大公司都有一套比较好的研发流程和工具,可以保证前后端互不影响还能很好的完成工作,但大部分中小公司我相信都可能遇到这种问题)。
‘卑微’的前端同学怎么办?
前端自己模拟数据,做挡板?就不调后端接口了,自己mock?估计很难,而且自己模拟数据也很费事啊,后端那么多接口,怎么模拟的过来,况且再怎么模拟也还是跟真实数据可能有出入不是!
把环境再分出一套,专门给前端用?好像也不行,这套环境也要维护啊,谁来维护,新的代码也还是需要不断的集成到这套新的环境中的,还是逃不开上面的问题。
让后端在指定的时间打包?你可以试试看后端会不会听你的话。。。

前端想要个稳定的环境怎么就这么难!
该如何解决?
这个问题,还是要通过技术手段去解决,最好就是后端服务别是单节点的,然后可以有手段感知到我们要用的后端接口服务的状态,如果服务异常,我请求不去这台服务器就可以了,然后后端打包的时候,多台服务器串行打包,保证至少有一台活着可以提供服务,这样前后端就又可以愉快的玩耍啦。
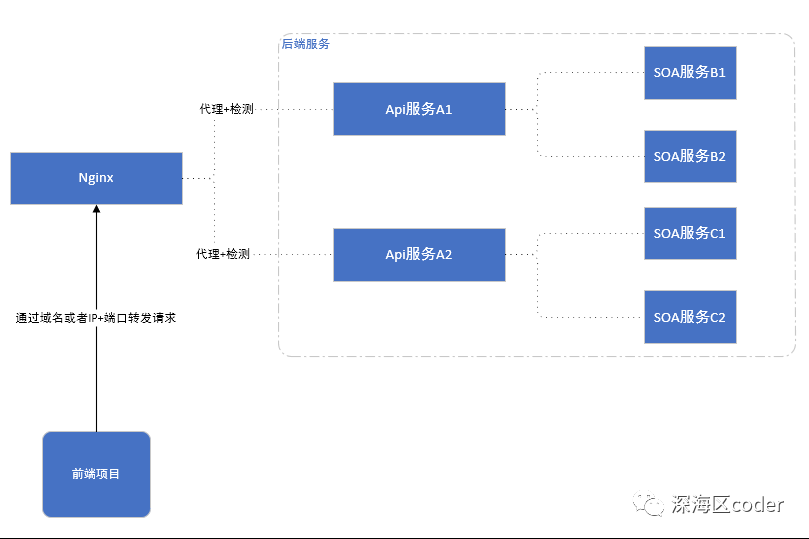
理想中的架构
一般架构抽象一下大概就是这个样子,后端也许会有很多花样,什么spring-cloud,微服务,SOA等等,总的说来没太多区别。像我所在的团队,后端的API服务这一层经常发生变更,下游依赖的服务也经常变更,不过是下游的服务是dubbo组成的,dubbo服务集群本身有状态管理,所以下游的服务并不会对前端造成影响,主要是API的变更对前端影响大。
在这种情况下,我们给nginx加上服务状态检测的能力,再配合jenkins分批串行打包,就可以完美解决前端的问题。
nginx的状态检测

nginx 代理+检测
nginx本身并不直接支持代理的服务的健康状态检查,需要依赖外部的一个模块实现,这个模块叫
nginx_upstream_check_module
这个模块来自阿里,模块已经被集成在阿里的Tengine中,这里顺便说一下阿里的Tengine,这个是阿里基于自己的需求定制扩展的nginx,完全兼容nginx,同时又整合了很多阿里自己开发的实用模块,nginx_upstream_check_module就是其中之一。我们本身有已经安装好的nginx,所以就只添加这个模块了。如果想要简单的办法,也可以直接安装tengine。
这个模块可以通过github下载到,如下是一个使用比较多的地址:
https://github.com/yaoweibin/nginx_upstream_check_module上面这个仓库中也有介绍安装和使用方法,我这里就简单列一下大致流程:
安装
# 1. 将仓库clone下来,放在和nginx源码目录同级目录下
# 2. 进入nginx源码目录,给nginx打补丁
patch -p1 < ../nginx_upstream_check_module/check_1.16.1+.patch
# 3. 重新编译nginx,注意,这里configure后面的参数要和之前安装的时候一样
./configure --add-module=../nginx_upstream_check_module/
# 4. 使用./objs/nginx文件 替换现有的nginx文件配置nginx的健康检查
upstream service-dev {
server 192.168.3.151:8080;
server 192.168.3.152:8080;
check interval=3000 rise=2 fall=2 timeout=1000 type=tcp;
}
## 然后在server下的location中可以使用上面的upstream,这其实是nginx负载均衡配置的方法。这里的check就是我们添加的模块中提供的指令,表示每3秒向后端节点发起一次tcp连接,连续两次失败则标记为不可用,再有两次成功则标记为可用。更多详细解析可以看上面的github主页。
配置状态页面
在同一个端口下,增加status路径,可以显示nginx检测的状态页面,访问/status 就可以看到
location /status {
check_status;
access_log off;
}就像下面这样
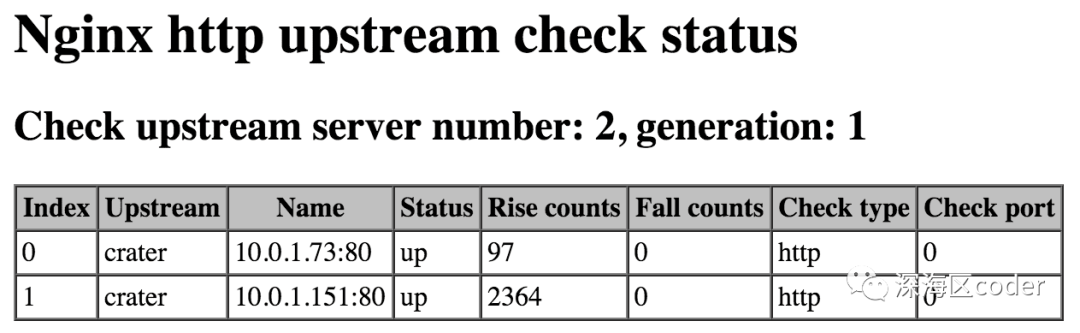
状态检测的结果
这样后端和前端各自干活,后台随便打包,前端不会受到任何影响。
既然都看到这里了,不妨点个赞再走呗 。
。















 1307
1307











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









