







前言
对于Web来说,并发量和访问量增加一定程度上推动项目技术和架构的更迭和进步。可能会有以下的一些状况:
页面并发量和访问量并不多,MySQL足以支撑自己逻辑业务的发展。那么其实可以不加缓存。最多对静态页面进行缓存即可。
页面的并发量显著增多,数据库有些压力,并且有些数据更新频率较低反复被查询或者查询速度较慢。那么就可以考虑使用缓存技术优化。对高命中的对象存到key-value形式的Redis中,那么,如果数据被命中,那么可以不经过效率很低的db。从高效的redis中查找到数据。
当然,可能还会遇到其他问题,你还通过静态页面缓存页面、cdn加速、甚至负载均衡这些方法提高系统并发量。这里就不做介绍。
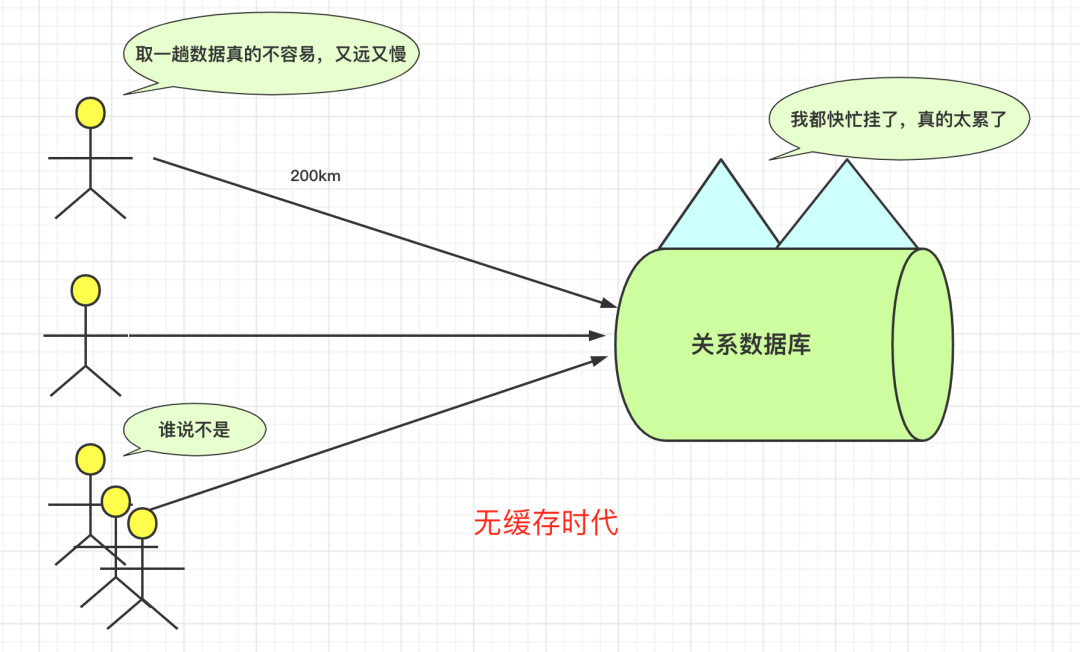
缓存思想无处不在
我们从一个算法问题开始了解缓存的意义。
问题1:
输入一个数n(n<20),求n!;
分析1:
单单考虑算法,不考虑数值越界问题。
当然我们知道n!=n * (n-1) * (n-2) * … * 1= n * (n-1)!;
那么我们可以用一个递归函数解决问题。
static long jiecheng(int n)
{
if(n==1||n==0)return 1;
else {
return n*jiecheng(n-1);
}
}
这样每输入求一次需要执行n次。
问题2:
输入t组数据(可能成百上千),每组一个xi(xi<20),求xi!;
分析2:
如果使用递归,输入t组数据,每次输入为xi,那么每次都要执行次数为:
当每次输入的Xi过大或者t过大都会造成不小的负担!时间复杂度为O(n2)
那么能否换个思想的。没错、是打表。打表常用于ACM算法中,常用于解决多组输入输出、图论搜索结果、路径储存问题。那么,对于这个求阶乘。我们只
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 263
263











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









