





Wang H , Guo S , Cao J , et al. MeLoDy: A Long-Term Dynamic Quality-Aware Incentive Mechanism for Crowdsourcing[J]. IEEE Transactions on Parallel & Distributed Systems, 2018, PP(99):1-1.
摘要
在众包模式中,为了充分利用群体智慧,允许请求者将任务分配给网上的一组工人。质量控制是众包激励机制的关键设计目标,然而在现有的机制中衡量工人的长期质量方法不利用工人的历史信息并且将工人的质量视为稳定忽略时间因素,效果不佳。在本文中,我们提出了MELODY,一种用于众包的长期动态质量感知激励机制。 MELODY模拟了请求者和工作者之间的交互作为持续运行的逆向拍卖。在MELODY的每次运行中,我们设计了一个真实合理、预算可行的质量感知算法用于任务分配,它具有多项式时间计算复杂度和O(1)性能比。此外,考虑到工人长期质量的特征,在每次运行结束时提出了基于线性动态系统的MELODY质量推理和参数学习的新框架,充分利用了工人的历史信息并且可以准确地预测他们的质量。通过大量的模拟,我们证明了在长期情景中,MELODY在质量评估和社会绩效方面优于现有工作。
介绍
众包将小任务外包给大量在线工人,并利用他们的群体智慧来解决这些任务。在Amazon Mechanical Turk (AMT)这样的众包平台中,请求者可能会提交一些小批量的任务,这些任务用计算机解决成本太高,无法自动化,但对人类来说却很简单,比如校对和图像标记。请求者写出他们愿意支付的金额。然后工人们选择完成任务并获得报酬。
现有的众包激励机制大多采用拍卖和定价的方式为工人提供货币奖励。在拟议的机制中,质量控制是平台设计人员需要考虑的关键问题之一。一方面,群体工作者具有不同层次的解决问题的能力,可能会提供不同质量的答案。另一方面,请求程序通常依赖于将一个任务分配给多个工作者来确保得到正确的答案。
虽然最近提出了许多关于工人质量的激励机制,但主要关注的是如何通过运行特定的任务分配算法将一组任务分配给一组员工,以及如何根据工人在一次运行中的表现来衡量工人的质量。然而,在现实中,众包平台(如AMT)需要长时间持续外包多组任务。为了适应这些多运行场景,现有的机制只能独立地为每组任务执行它们的算法,而不考虑工人的历史信息。该算法简单地利用工人的现有信息进行独立重复,丧失了对工人质量的先验知识,容易受到系统噪声的影响,导致出现过拟合现象。现有的一些机制确实利用了工人的历史信息来衡量和估计他们的素质。然而,他们忽略工人质量的时间特征(即,工作人员的先验信息被视为一个集合,而不是序列)。这类模型缺乏足够的拟合能力,无法对真实工人的长期素质进行拟合,称为拟合不足。
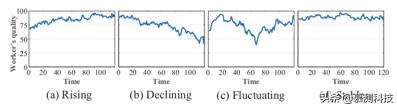
进一步说明这些问题,我们分析一个公开数据并绘制四种典型的类型的工人的时变质量曲线(图1),我们学习的工人的长期质量有两个重要属性:
1)在一些运行中,工人的潜在质量不太可能大幅改变。
2)除了少数情况(图d),质量在相当长一段时间内保持稳定外,大多数工人的长期质量曲线呈现出明显的上升、下降和波动,如图a、b和c所示。这种趋势往往是由于工人的专业水平、熟练程度和努力程度逐渐积累的变化,而不是偶然发生的,不能用简单的统计分布来表现。
现有的机制忽略了工人长期质量的这两个属性,因此无法长期保持良好的表现。
针对上述过拟合和欠拟合问题,本文提出了一种考虑工人长期动态质量的真实、预算可行的众包市场激励机制MELODY。MELODY将请求者和工人之间的交互建模为连续运行的反向拍卖。在每次运行中,请求者发布一组带有预算的任务,工人提交他们的投标信息。然后MELODY确定任务分配方案和支付方案,使每个工人的出价和每个任务的质量要求相符合,同时保证真实性、个体合理性、竞争力和计算效率。
相关工作
A.众包激励机制
除少数非货币性激励机制外,众包的激励机制大多以拍卖和定价为基础,利用货币性奖励来激励员工。但是现有的机制如大规模众包平台的预算可行机制、基于lyapunovo的VCG拍卖策略等,没有考虑到工人质量的因素。其他的现有机制考虑了工人的质量因素,但是没有考虑工人质量的长期特征。
B.众包的质量控制和测量
我们的论文与现有的质量控制研究之间的主要区别在于,我们更多地关注工人长期质量的估算和更新方法,而不是这些工作中讨论的质量测量指标。现有研究中的质量测量指标可以自然地纳入我们的工作中。
系统模型与问题公式
在我们的系统中,我们考虑一个单一的平台,有几个请求者,一组通用的工作者Wu = {1,2,...}。 在每次运行中r∈N+,其中一个请求者发布了一系列众包任务Tr = {tr1,{tr2,...}给一组合格的工人Wr⊆Wu。在这项工作中,我们只考虑解决这些任务所需要的知识和努力是同质的。
我们将请求者和给定运行中的工人之间的交互建模为反向拍卖。 工人将他们的智慧或努力卖给请求者并寻求可以最大化他们个人效用的制定策略,并且请求者决定是否以及以什么价格购买他们的服务。
在我们的模型中,假设可以将任务分配给多个工人以进行质量保证,并且可以在运行中为工人分配多个任务。 我们还假设请求者将预算Br∈R+作为他愿意在运行r中支付的总支付金额。
A.系统工作流程
我们的拍卖系统由多个基本运行单元r组成。在运行r中,系统工作流程描述如下:
1)拍卖开始前,平台从一个请求者那里接收一个带有预算约束的任务,并从所有工作人员那里获得投标信息。然后确定合格工人的集合。
2)平台决定分配给工人i。
3)工人i完成分配给他的每一项任务,回复请求者的应答,并根据支付方案获得任务的报酬。
4)对于工人i的所提交的答案,请求者给出分数,并提交给平台。
5)在收到本次运行的所有分数后,平台会更新每个工人的质量。
B.工人建模
为了表述我们的问题,运行 r中的每个工人与这些关联:
1)执行每一项任务的成本投标
2)工人愿意完成的任务的最大数量(也称为频率)
3)运行r中的潜在质量的先验概率
上述成本和频率的出价构成了工人的投标, 一个工人可能会为了最大化他的效用而撒谎,所以我们使用成本和频率来表示工人的真实出价。
C.工人和请求者的实用效用
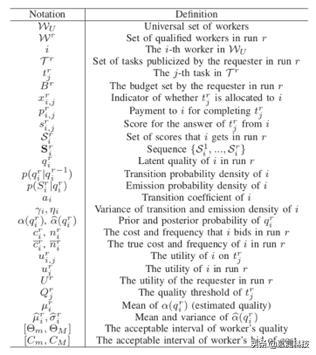
该表为下述公式中部分符号的含义。
在运行r中,每个工人在战略性地确定了他的出价并最大化他的效用。在定义1中展示工人的效用。
定义1:运行r中的工人i的效用是他收到的总报酬与其总成本之间的差额:
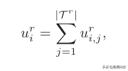
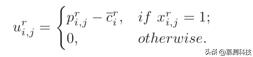
为了确保从工人收集的答案的质量(例如,标签的置信度),每项任务都需要足够的集体智慧和努力。 值得注意的是,量化综合人群质量仍然是众包中的一个挑战性问题,因为答案的类型有多种形式(例如,文本,照片,选项),并且答案之间可能存在相关性。因此,在测量一群人的综合质量时,现有机制都会进行适度的简化。
在本文中,所有工人在任务上生成的综合质量被定义为:如果完成任务的综合质量超过请求者设定的阈值,则算对该任务完成情况满意。
定义2:满意的任务。
当

成立时,该任务为满意的任务。
在定义2中,我们使用μri来完全表示工人i的信息质量。我们称μri为工人i的估计质量。基于上述概念,我们在定义3中提出了请求者效用的定义。
定义3:请求者的效用。运行r中的请求者的效用是满意任务的总数:
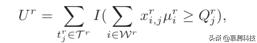
where I (·) is indicator function defined as I (TRUE) = 1 and I(FALSE) = 0.
D.平台的设计目标
我们将单次运行拍卖(SRA)问题制定为以下线性编程。
定义4(SRA问题)。 在运行 r中,平台希望在请求者的预算和工人出价的约束下最大化请求者的效用。
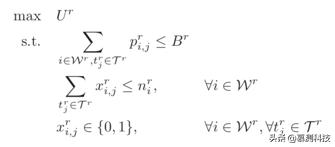
为了提高平台的实用性,我们的目标是计满足以下所需特性的MELODY:
•真实:如果所有工人报告真实出价,那么机制就是真实的。
•个体合理性:如果每个参与的工作者都具有非负效用,则机制是个体合理性的。
•竞争力:使用符号OPT来表示在平台完全了解工人真实投标的情况下可以计算的最优解,MEL表示MELODY的结果。
•计算效率:如果分配和支付方案都运行多项式时间,则机制在计算上是有效的。
•长期质量意识:如果能够在估算工人质量时根据其长期特征利用工人的历史信息,则该机制具有长期质量意识。
单次拍卖的机制设计
定理一:SAR问题是NP-hard问题

由于SRA问题的NP-hardness,我们不建议在实际场景中计算精确的最优解,因为它随着输入规模呈指数增加的执行时间。 因此,我们设计了一个近似贪心算法来解决run r中的SRA问题,如算法1所示。
动态质量评估的机制设计
A.参数设计
参数学习的目的是根据工人得分集的顺序确定工人参数。 由于模型具有潜在变量,因此可以使用期望最大化(EM)算法来解决。EM算法是用于在模型包含未观察到的数据时找到参数的最大似然估计的迭代方法。

B.质量推理
定理2:(一般形式的质量推理) 后验概率的递推方程是

定理3:(高斯形式的质量推理)
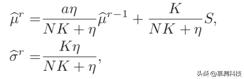
C.两次运行之间的MELODY设计
我们通过在MELODY中结合参数学习和质量推理,提出了两次连续运行之间工人质量的更新方法,如算法3所示。

在算法3中,我们首先根据定理3(第1-5行)中的更新规则更新每个工人的质量。 之后,如果此工作人员的θ未针对T次运行更新(T由平台设置),则运行算法2以重新估计工人的参数(第6-8行)。 请注意,较小的T将带来更高的模型精度,因为我们更频繁地重新估计θ,但同时会增加算法的时间开销。
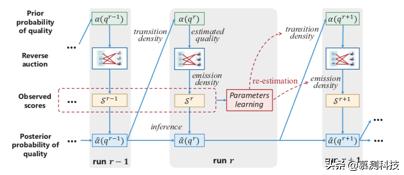
上图总结了MELODY的总体框架。 我们在上图中更加强调质量推理和参数学习,而上述任务分配和支付确定机制在第二行中被称为“反向拍卖”。
绩效评估
在本节中,我们将评估MELODY的竞争力和长期质量意识。
A.竞争力
为了有效地评估性能,我们针对以下两个基准机制实现了MELODY:
1)OPT-UB是SRA问题最优解的估计上界。 由于计算SRA问题的最优解是非常耗时,我们使用最优的上限而不是最优本身作为第一基准。
2)随机作为SRA问题的基线解决方案,以随机顺序选择任务。
我们使用表3中的数据来设置SAR问题,我们将预算(或工人数量)设置为固定值,并改变工人(或预算)的数量。
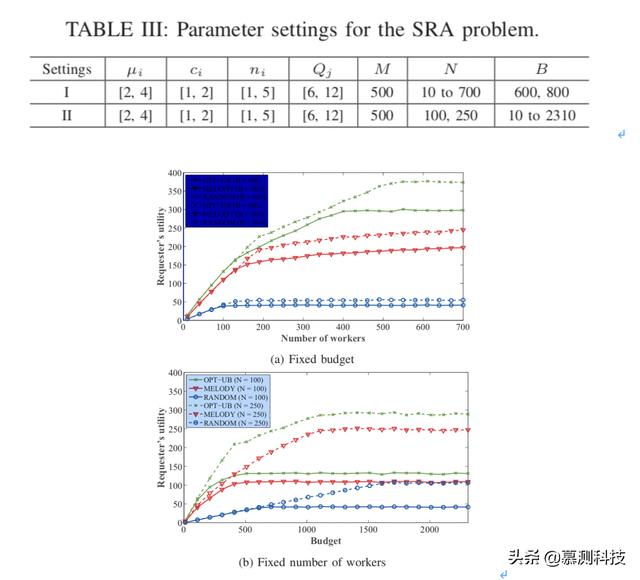
OPT-UB,MELODY和RANDOM的请求者的效用于上图。我们从上图观察,上图a(或b),该请求者的工人(或预算)的数量效用增加,直到达到饱和预算限额(或工人数量)。我们还可以从上图中了解到,MELODY接近最优并且比基线好得多。这一重要观察表明MELODY在现实中具有很高的竞争力。
B.长期质量意识
我们基于算法2和3实现了MELODY工人质量的更新方法,并将MELODY与以下三种基准方法进行了比较。
质量的平均估计误差和每次运行的请求者效用分别绘制在下图a和下图b中。 我们观察到,由于相同的初始设置,四种机制的性能在开始时大致相同,但是在长期内显著不同。 我们提出的MELODY在质量的平均估计误差和每次运行的请求者效用方面都优于其他三个。
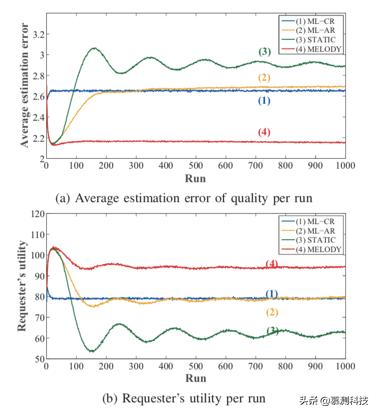
为了进一步定量评估MELODY,我们计算了STATIC,ML-CR,ML-AR和MELODY的所有运行的质量和请求者效用的平均估计误差。 根据上图所示的结果,MELODY达到平均请求者的效用为94.6,比其他三种机制分别高出46.6%,19.7%和18.2%。 同时,工人素质的估计误差分别降低了24.2%,18.5%和17.6%。 实验结果表明MELODY带来了显着的性能提升。
结论
在本文中,我们提出了一种真实的、长期的、具有质量意识的众包激励机制MELODY,设计了单次运行任务分配和支付方案的近似算法,提出了基于线性动态系统和EM算法的连续两次运行间工人长期质量的质量推理和参数学习框架。证明了MELODY具有很强的真实性和竞争力等理论保证。仿真结果表明,该方法的性能明显优于基线法和已有的工作。
致谢
本文由南京大学软件学院2019级硕士吉品翻译转述。















 5287
5287











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









