






这是一个基于CRF的中文依存句法分析器,内部CRF模型的特征函数采用 双数组Trie树(DoubleArrayTrie)储存,解码采用特化的维特比后向算法。相较于《最大熵依存句法分析器的实现》,分析速度翻了一倍,达到了1262.8655 sent/s开源项目本文代码已集成到HanLP中开源:http://www.hankcs.com/nlp/han

这是一个基于CRF的中文依存句法剖析器,内部CRF模子的特征函数接纳双数组Trie树(DoubleArrayTrie)储存,解码接纳特化的维特比后向算法。相较于《最大熵依存句法剖析器的实现》,剖析速率翻了一倍,达到了1262.8655 sent/s
开源项目
本文代码已集成到HanLP中开源:http://www.hankcs.com/nlp/hanlp.html
CRF简介
CRF是序列标注场景中常用的模子,比HMM能行使更多的特征,比MEMM更能抵制符号偏置的问题。在生产中经常使用的训练工具是CRF++,关于CRF++的使用以及模子花样请参阅《CRF++模子花样说明》。
CRF训练
语料库
与《最大熵依存句法剖析器的实现》相同,接纳清华大学语义依存网络语料的20000句作为训练集。
预处置
依存关系事实上由三个特征组成——起点、终点、关系名称。在本CRF模子中暂时忽略掉关系名称(在下文可以行使其它模子补全)。
凭据依存文法理论, 我们可以知道决议两个词之间的依存关系主要有二个因素: 偏向和距离。因此我们将种别标签界说为具有如下的形式:
[ + |- ] dPOS
其中, [ + | – ]示意偏向, + 示意支配词在句中的位置泛起在隶属词的后面, – 示意支配词泛起在隶属词的前面; POS示意支配词具有的词性种别; d示意距离。
好比原树库:
1很很dd_2水平
2有有vvyou_0焦点身分
3需要需要aa_2存现体
4对对pp_14介词依存
5惩治惩治vv_14限制
6贪污贪污vv_8限制
7行贿行贿nn_6毗邻依存
8犯罪犯罪vvn_5受事
9的的uude1_5“的”字依存
10一些一些mmq_14数目
11理论理论nn_14限制
12与与ccc_11毗邻依存
13实践实践vvn_11毗邻依存
14问题问题nn_16内容
15举行举行vvx_16谈论
16研究研究vvn_3限制

转换后:
很dd+1_v
有vvyou-1_ROOT
需要aa-1_v
对pp+3_n
惩治vv+3_n
贪污vv+1_v
行贿nn-1_v
犯罪vvn-2_v
的uude1-3_v
未##量mmq+2_n
理论nn+1_n
与ccc-1_n
实践vvn-1_n
问题nn+2_v
举行vvx+1_v
研究vvn-1_a
特征模板
# Unigram
U01:%x[0,0]
U02:%x[0,0]/%x[0,2]
U03:%x[-1,2]/%x[0,0]
U04:%x[-1,2]/%x[0,2]/%x[0,0]
U05:%x[0,0]/%x[1,2]
U06:%x[0,0]/%x[0,2]/%x[1,2]
U07:%x[-1,2]/%x[0,2]
U08:%x[-1,1]/%x[0,2]
U09:%x[0,2]/%x[1,2]
U10:%x[0,2]/%x[1,1]
U11:%x[-2,2]/%x[-1,2]/%x[0,2]/%x[1,2]
U12:%x[-1,2]/%x[0,2]/%x[1,2]/%x[2,2]
U13:%x[-2,2]/%x[-1,2]/%x[0,2]/%x[1,2]/%x[2,2]
U14:%x[-2,1]/%x[-1,2]/%x[0,2]
U15:%x[-1,2]/%x[0,2]/%x[1,2]
U16:%x[-1,1]/%x[0,2]/%x[1,1]
U17:%x[-1,2]/%x[1,2]
# Bigram
B
训练参数
crf_learn -f 3 -c 4.0 -p 3 template.txt train.txt model -t
我的试验条件(机械性能)有限,每迭代一次要花5分钟,最后只能设定最大迭代次数为100。经由痛苦的迭代,获得了一个效果异常有限的模子,其serr高达50%,暂时只做算法测试用。
解码
尺度的维特比算法假定所有标签都是正当的,但是在本CRF模子中,标签还受到句子的约束。好比最后一个词的标签不可能是+nPos,必须是负数,而且任何词的[+/-]nPos都得保证后面(或前面,当符号为负的时刻)有n个词语的标签是Pos。以是我覆写了CRF的维特比tag算法,代码如下:
@Override
public void tag(Table table)
{
int size = table.size();
double bestScore = 0;
int bestTag = 0;
int tagSize = id2tag.length;
LinkedList scoreList = computeScoreList(table, 0); // 0位置掷中的特征函数
for (int i = 0; i
{
for (int j = 0; j
{
if (!isLegal(j, 0, table)) continue;
double curScore = matrix[i][j] + computeScore(scoreList, j);
if (curScore > bestScore)
{
bestScore = curScore;
bestTag = j;
}
}
}
table.setLast(0, id2tag[bestTag]);
int preTag = bestTag;
// 0位置打分完毕,接下来打剩下的
for (int i = 1; i
{
scoreList = computeScoreList(table, i); // i位置掷中的特征函数
bestScore = Double.MIN_VALUE;
for (int j = 0; j
{
if (!isLegal(j, i, table)) continue;
double curScore = matrix[preTag][j] + computeScore(scoreList, j);
if (curScore > bestScore)
{
bestScore = curScore;
bestTag = j;
}
}
table.setLast(i, id2tag[bestTag]);
preTag = bestTag;
}
}
注重上面的
if (!isLegal(j, i, table)) continue;
保证了标签的正当性。
这一步的效果:
坚决aad+1_v
惩治vv-1_ROOT
贪污vv+2_n
行贿nn-1_v
等uudeng-1_v
经济nn+1_v
犯罪vvn-2_v
后续处置
有了依存的工具,还需要知道这条依存关系到底是哪种详细的名称。我从树库中统计了两个词的词与词性两两组合泛起概率,临时称其为2gram模子,用此模子接受依存边两头的词语,输出其最可能的关系名称。
最终效果
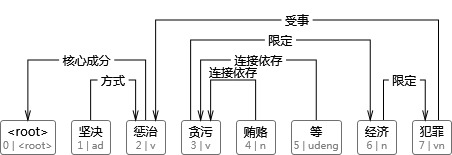
转换为CoNLL花样输出:
1坚决坚决ada_2方式__
2惩治惩治vv_0焦点身分__
3贪污贪污vv_6限制__
4行贿行贿nn_3毗邻依存__
5等等udengu_3毗邻依存__
6经济经济nn_7限制__
7犯罪犯罪vnv_2受事__
评测
在封锁测试集上效果随随便便:
UA: 71.13%LA: 66.51%DA: 66.07%sentences: 20000speed: 1077.6443 sent/s
Aho Corasick自动机结合DoubleArrayTrie极速多模式匹配
本文使用Double Array Trie实现了一个性能极高的Aho Corasick自动机,应用于分词可以取得1400万字每秒,约合27MB/s的分词速度。其中词典为150万词,构建耗时1801 ms。以前就在构想将AC自动机与双数组Trie树结合起来,考虑到持久化比较困难(goto和fail表是内存指针/引用),一直没下决心实现,今天终于成功了。AC自动
机器学习 吴
在测试集上则有待改善:
UA: 60.72%LA: 47.24%DA: 45.48%sentences: 2000speed: 890.4719 sent/s
2014年12月12日更新:
今天改善了特征模板,简朴地去掉了B特征,提高异常显著。
封锁测试集——
UA: 78.81%LA: 73.67%DA: 72.59%sentences: 20000speed: 1262.8655 sent/s
开发集——
UA: 67.66%LA: 52.53%DA: 50.16%sentences: 2000speed: 787.40155 sent/s
我上次关于“B特征似乎没有任何用处”的展望是准确的。
2014年12月14日更新
今天再次改善了特征模板,将前后5个词语的词和词性与其组合作为特征,训练了80个迭代,效果更好了。
封锁测试集——
UA: 91.61%LA: 85.68%DA: 84.94%sentences: 20000speed: 582.42816 sent/s
开发集——
UA: 71.22%LA: 55.02%DA: 52.69%sentences: 2000speed: 513.34705 sent/s
值得一提的是,由于条件有限,模子并没有训练到足够收敛。若是有足够的时间,应该可以获得加倍正确的模子。同时模子的体积也达到了466MB,价值很大。
思索
我以为不足之处有三:
机械性能受限,没有训练到足够收敛
特征模板没有设计好,B特征似乎没有任何用处
语料库自己有错误
另外,关于将线性CRF序列标注应用于句法剖析,我持否决意见。CRF的链式结构决议它的视野只有当前位置的前后n个单词组成的特征,若是依存节点正好落在这n个局限内还好明白,若是超出该局限,行使这个n个单词的特征推测它是不合理的。也就是说,我以为行使链式CRF展望长依存是不科学的。
我不清楚论文中标称的80+%的准确率是怎么盘算的,我保留意见。
Reference
 基于序列标注的中文依存句法剖析方式.pdf
基于序列标注的中文依存句法剖析方式.pdf
本站声明:此内容来源于码农场,若有侵权,请联系我们,我们将及时处置。















 146
146











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









