






XML(可扩展标记语言)是一种很流行的简单的基于文本的语言来用作应用程序之间的通信模式。它被认为是传输标准装置和存储数据。在数据交互还有配置问题方面会比较常用到,解析方式大概有以下几种,使用还要根据场景灵活运用:
XML的常用解析方式分大致为四种:1、DOM解析;2、SAX解析;3、JDOM解析;4、DOM4J解析。前两种属于基础方法,是官方提供的解析方式;后两种是在基础的方法上扩展出来的。
1.首先得先有一个XML文件:
创建 information.xml,路径:D:information.xml。针对此XML文件,进行四种方法的解析,文件内容如下:
<?xml version="1.0" encoding="UTF-8"?>
<persons>
<person id="1">
<name>xiaohuahua</name>
<age>16</age>
<call>100000000001</call>
<language>Chinese</language>
</person>
<person id="2" sex="man">
<name>xiaoxingxing</name>
<age>18</age>
<call>100000000000</call>
<language>Chinese</language>
</person>
</persons>2.DOM解析:
DOM解析原理:xml解析器一次性把整个xml文档加载进内存,然后在内存中构建一颗Document的对象树,通过Document对象,得到树上的节点对象,通过节点对象访问(操作)到xml文档的内容。代码如下:
代码开始前拿person1说明一下元素节点、属性节点和文本节点。元素节点:一般是拥有一对开闭合标签的元素整体,例如上图中的<age>...</age>这一部分都属于一个元素节点;属性节点:一般是元素节点的属性,比如上图中的“id”属性 也就是id="1"这一部分;文本节点:DOM中用于呈现文本的部分,如上图中的 “xiaohuahua”,一般被包含在元素节点的开闭合标签内部。
(ps:代码较多不好贴,直接上图片)
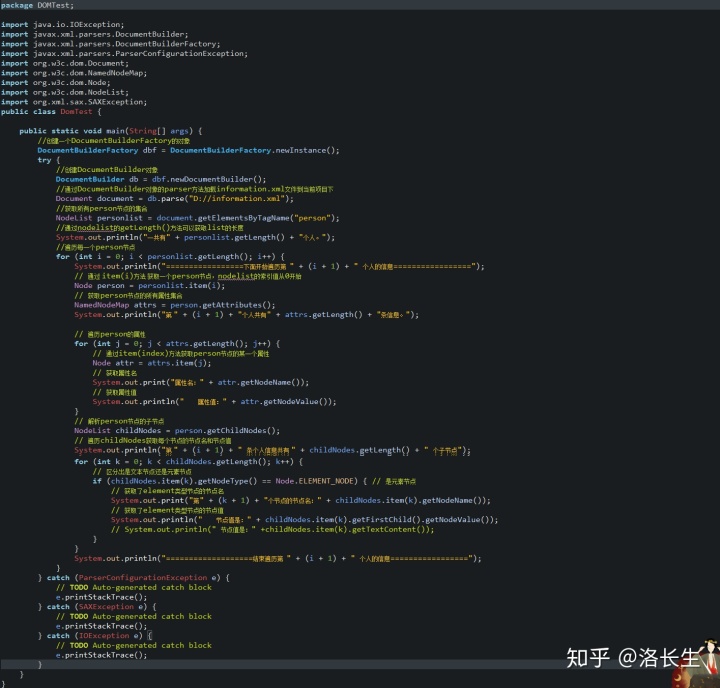
运行结果:
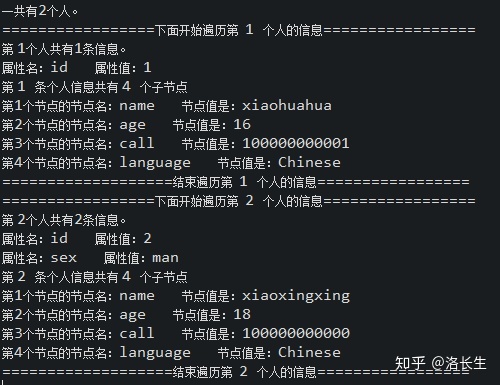
优点:
1、允许应用程序对数据和结构做出更改。
2、访问是双向的,可以在任何时候在树中上下导航,获取和操作任意部分的数据。
缺点:
1、通常需要加载整个XML文档来构造层次结构,消耗资源大。
2、如果XML文件比较大,容易影响解析性能且可能会造成内存溢出。
3.SAX解析:
SAX的工作原理简单地说就是对文档进行顺序扫描,当扫描到文档开始与结束、元素开始与结束、文档(document)结束等地方时通知事件处理函数,由事件处理函数做相应动作,然后继续同样的扫描,直至文档结束。
1.创建Person类:
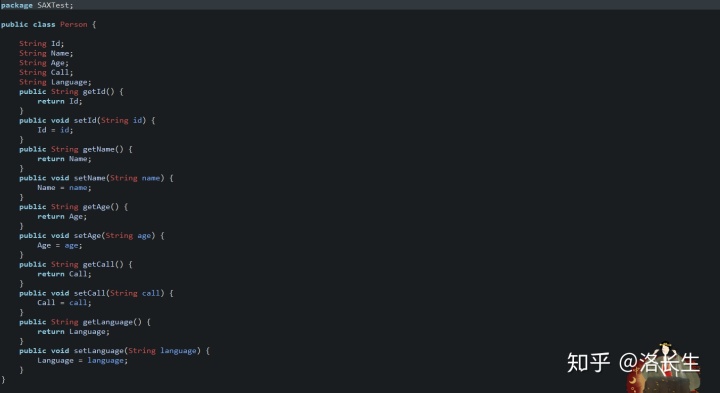
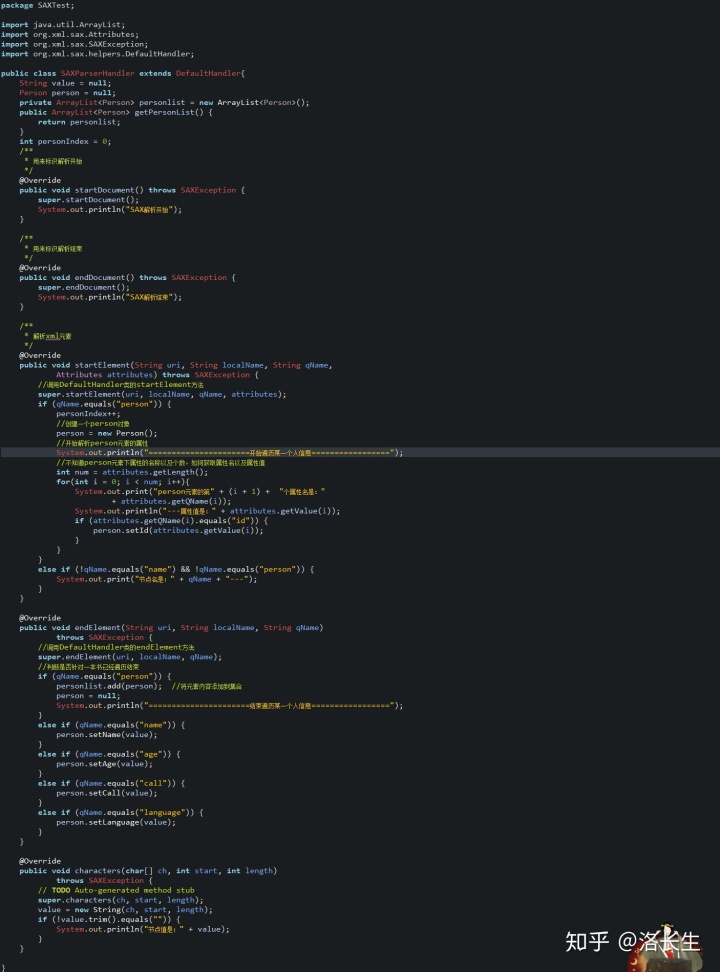
2.创建一个解析类继承DefaultHandler,并重写重要方法,会在后面介绍五个方法的作用:
1.startDocument();
2.startElement(String uri, String localName, String qName, Attributes attributes);
3.characters(char[] ch, int start, int length);
4.endElement(String uri, String localName, String qName);
5.endDocument()。
3.创建测试方法:
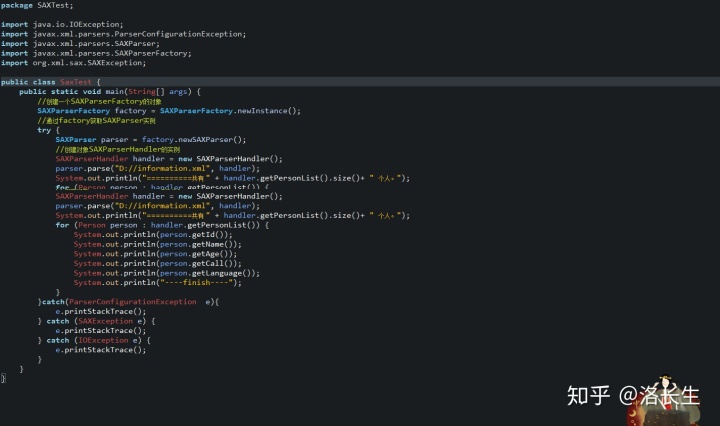
运行结果:
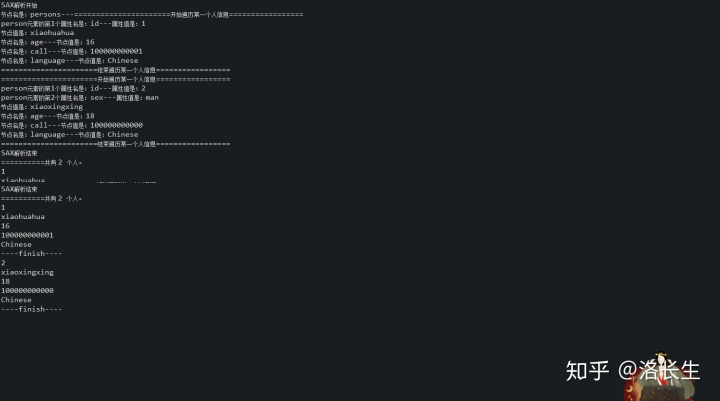
首先介绍一下DefaultHandler类:DefaultHandler是SAX2事件处理程序的默认基类。它继承了EntityResolver、DTDHandler、ContentHandler和ErrorHandler这四个接口。包含这四个接口的所有方法,所以我们在编写事件处理程序时,可以不用直接实现这四个接口,而继承该类,然后重写我们需要的方法。
SAX解析步骤:
1.创建一个SAXParserFactory对象SAXParserFactory factory=SAXParserFactory.newInstance();
2.获得解析器SAXParser parser=factory.newSAXParser();
3.调用解析方法解析xml,这里的第一个参数可以传递文件、流、字符串;第二个参数我们先定义一个用于实现解析类,如SAXParserHandler。
4.创建一个SAXParserHandler类来继承DefaultHandler并重写方法。即上面提到的五个必要方法,执行顺序按以下序号排列:
1.startDocument():开始处理文档;
2.startElement(String uri, String localName, String qName, Attributes attributes):处理元素的开始;
3.characters(char[] ch, int start, int length):用来读取节点内容;
4.endElement(String uri, String localName, String qName):元素处理结束;
5.endDocument():文档处理结束。
优点:
1、解析速度快,SAX解析器是对文档的解析过程是一种边解析边执行的过程;
2、内存消耗少,SAX解析器对文档的解析过程中,无需把整个文档都加载到内存中;
3、使用SAX解析器时,可以注册多个ContentHandler对象,并行接收事件。
缺点:
1、必须实现事件处理程序;
2、不能随机访问:SAX解析器对文档的解析是顺序进行的;
3、不能修改文档:使用SAX对文档进行解析,只能访问文档内容,无法做到向文档中添加节点,更不能删除和修改文档中的内容。
4.JDOM解析
用JDOM解析XML需要依赖包jdom.jar,需要下载后导入。JDOM只是被设计用来处理Java,它不是一个XML解析器但是它可以使用SAX,STAX或者DOM解析器用来构建一个JDOM文档。
1.person类和SAX解析用的是同一个,不再贴明;
2.创建处理以及测试类:
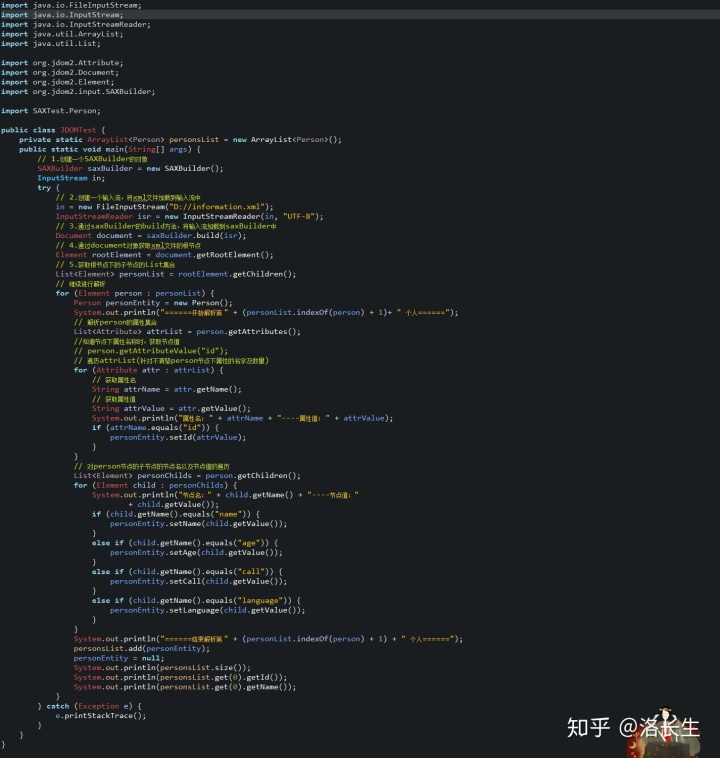
运行结果:
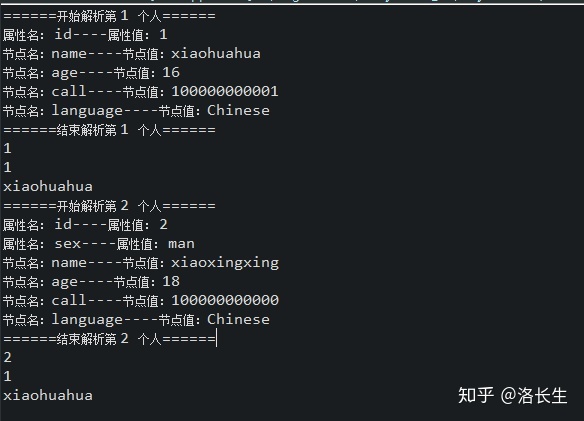
两位个人信息最后输出的都是xiaohuahua,因为我输出的就是第一位的信息,不要看走眼了。
优点:
1、使用具体类而不是接口,简化了DOM的API;
2、大量使用了Java集合类,方便了Java开发人员。
缺点:
1、没有较好的灵活性;
2、性能较差。
5.DOM4J解析
与利用DOM、SAX来解析xml相比,DOM4J 表现更优秀,具有性能优异、功能强大和极端易用使用的特点,只要懂得DOM基本概念,就可以通过dom4j的api文档来解析xml。dom4j是一套开源的api。实际项目中,往往选择dom4j来解析xml。同样,需要导入http://dom4j.com等。
1.创建处理、测试类:
运行结果:
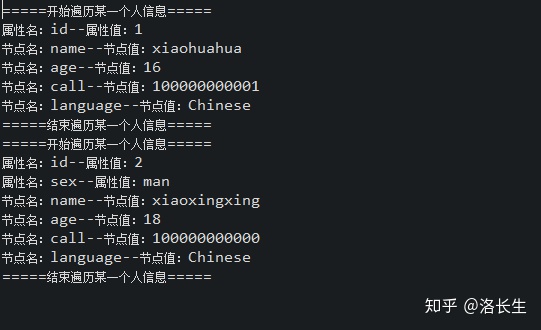
优点:
1、大量使用了Java集合类,方便Java开发人员,同时提供一些提高性能的替代方法;
2、有很好的性能;
3、支持XPath.(后续需要了解)
缺点:
1、大量使用了接口,API较为复杂。
总结一下:DOM4J性能最好、简单易用,采用Java集合框架,并完全支持DOM、SAX和JAXP,如果不考虑可移植性,那就采用DOM4J。溜了溜了。
联系我:
















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









