






前言
今天在微信公众号【早起Python】,看到有篇文章叫做【玩转数据处理120题】,最初来自【Pandas进阶修炼120题】,作者刘早起开始是用pandas实现的,后来又加入了中山大学博士陈熹的R语言版本。
但是这个R语言版本,代码比较陈旧和啰嗦,甚至是误解(比如R语言处理Excel文件不好之类,mutate与summarise混淆),根本没有体现出如今R语言在有了tidyverse之后,在数据处理上比python更加“简洁”和“优雅”。
所以,我打算利用R语言 tidyverse,也来玩转一下这个数据处理120题。同时也是为如今的R语言正名,不要停留在R语言不好用的老观念上。
本篇先来第1-20题。
题目1(创建数据框):将下面的字典创建为DataFrame
data = {"grammer": ["Python","C","Java","GO",np.nan,"SQL","PHP","Python"], "score":[1,2,np.nan,4,5,6,7,10]}
难度:★
代码及运行结果:
df = tibble(
grammer = c("Python","C","Java","GO", NA,"SQL","PHP","Python"),
score = c(1,2,NA,4,5,6,7,10)
)
df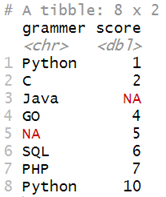
问题2(筛选行):提取含有字符串"Python"的行
难度:★
代码及运行结果:
df %>%
filter(grammer == "Python")
题目3(查看列名):输出df的所有列名
难度:★
代码及运行结果:
names(df)
题目4(修改列名):修改第2列列名为"popularity"
难度:★★
代码及运行结果:
df = df %>%
rename(popularity = score)
df
题目5(统计频数):统计grammer列中每种编程语言出现的次数
难度:★★
代码及运行结果:
df %>%
count(grammer) # 或者用 table(df$grammer)
题目6(缺失值处理):将空值用上下值的平均值填充
难度:★★★
代码及运行结果:
df = df %>%
mutate(popularity = zoo::na.approx(popularity))
df
注:dplyr包提供了fill()函数,可以用前值或后值插补缺失值。
题目7(筛选行):提取popularity列中值大于3的行
难度:★★
代码及运行结果:
df %>%
filter(popularity > 3)
题目8(数据去重):按grammer列进行去重
难度:★★
代码及运行结果:
df %>%
distinct(grammer, .keep_all = TRUE)
题目9(数据计算):计算popularity列平均值
难度:★★
代码及运行结果:
df %>%
summarise(popularity_avg = mean(popularity))
题目10(格式转换):将grammer列转换为序列
难度:★
代码及运行结果:
df$grammer
注:R从数据框中提取出来就是字符向量。
题目11(数据保存):将数据框保存为Excel
难度:★★
代码及运行结果:
writexl::write_xlsx(df, "filename.xlsx")题目12(数据查看):查看数据的行数列数
难度:★
代码及运行结果:
dim(df)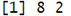
题目13(筛选行):提取popularity列值大于3小于7的行
难度:★★
代码及运行结果:
df %>%
filter(popularity > 3 & popularity < 7)
题目14(调整列位置):交互两列的位置
难度:★★
代码及运行结果:
df %>%
select(popularity, grammer)
注:可配合everything()放置“其余列”,更强大的调整列位置的函数是dplyr1.0将提供的relacate().
题目15(筛选行):提取popularity列最大值所在的行
难度:★★
代码及运行结果:
df %>%
filter(popularity == max(popularity))
# 或者用df %>% top_n(1, popularity)
题目16(查看数据):查看最后几行数据
难度:★
代码及运行结果:
tail(df) # 默认是最后6行注:此外,head()查看前几行,dplyr包还提供了sample_n()和sample_frac()随机查看n行或某比例的行。

题目17(修改数据):删除最后一行数据
难度:★★
代码及运行结果:
df %>%
slice(-n())
题目18(修改数据):添加一行数据:"Perl", 6
难度:★★
代码及运行结果:
newrow = tibble(grammer="Perl", popularity=6)
df %>%
bind_rows(newrow)
题目19(数据整理):对数据按popularity列值从到大到小排序
难度:★★
代码及运行结果:
df %>%
arrange(desc(popularity))
注:不套一层desc(), 是默认从小到大排序。
题目20(字符统计):统计grammer列每个字符串的长度
难度:★★
代码及运行结果:
df %>%
mutate(strlen = str_length(grammer))
参考文献
遥遥无期:玩转数据处理120题|Pandas版本zhuanlan.zhihu.com
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









