







1.定义
Kafka中的每个partition都由一系列有序的、不可变的消息组成,这些消息被连续的追加到partition中。partition中的每个消息都有一个连续的序号,用于partition唯一标识一条消息。
Offset记录着下一条将要发送给Consumer的消息的序号。
流处理系统常见的三种语义:
最多一次
每个记录要么处理一次,要么根本不处理
至少一次
这比最多一次强,因为它确保不会丢失任何数据。但是可能有重复的
有且仅有一次
每条记录将被精确处理一次,没有数据会丢失,也没有数据会被多次处理The semantics of streaming systems are often captured in terms of how many times each record can be processed by the system. There are three types of guarantees that a system can provide under all possible operating conditions (despite failures, etc.)
At most once: Each record will be either processed once or not processed at all.
At least once: Each record will be processed one or more times. This is stronger than at-most once as it ensure that no data will be lost. But there may be duplicates.
Exactly once: Each record will be processed exactly once - no data will be lost and no data will be processed multiple times. This is obviously the strongest guarantee of the three.
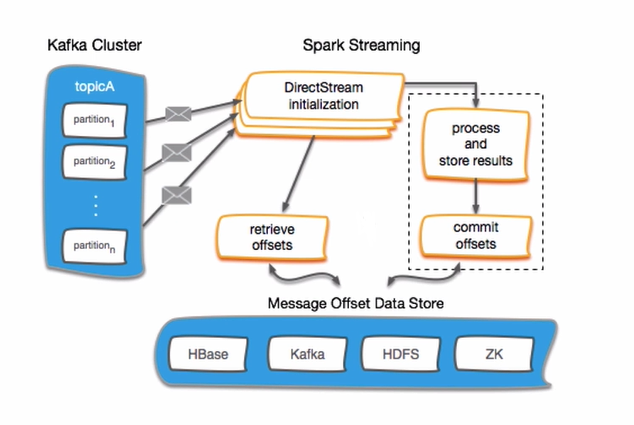
2.Kafka offset Management with Spark Streaming
Offset首先建议存放到Zookeeper中,Zookeeper相比于HBASE等来说更为轻量级,且是做HA(高可用性集群,High Available)的,offset更安全。
对于offset管理常见的两步操作:
保存offsets
获取offsets
3.环境准备
启动一个Kafka生产者,测试使用topic:tp_kafka:
./kafka-console-producer.sh --broker-list hadoop000:9092 --topic tp_kafka
启动一个Kafka消费者:
./kafka-console-consumer.sh --zookeeper hadoop000:2181 --topic tp_kafka
在IDEA中生产数据:
package com.taipark.spark;
import kafka.javaapi.producer.Producer;
import kafka.producer.KeyedMessage;
import kafka.producer.ProducerConfig;
import java.util.Properties;
import java.util.UUID;
public class KafkaApp {
public static void main(String[] args) {
Strin
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 674
674











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









