





摘要:语义分割是自动驾驶场景理解中的关键步骤。尽管深度学习已显著提高了分割精度,但由于当前的高质量模型架构复杂且依赖于多尺度输入,因此效率低下。因此,很难将它们应用于实时或实际应用。另一方面,实时性较好的方法仍无法在交通信号灯等小物体上产生令人满意的结果,这对自动驾驶来说,对安全性有很大的威胁。本文从两个方面提高了实时语义分割的性能和数据。具体来说,本文提出了一种由 Neep Deep Network(NDNet)创建的实时分割模型,并通过将其他小物体插入训练图像中来构建合成数据集。该方法在 1024×2048 输入上仅 8.4G 浮点运算(FLOP)即可在 Cityscapes 测试集上实现 65.7%的平均相交度(mIoU)。此外,通过在合成数据集上对现有的 PSPNet 和 DeepLabV3 模型进行重新训练,本文在小物体上的平均 mIoU 提高了 2%。
1. 主要贡献
在本文中,本文旨在进一步提高实时语义分割的效率,同时确保对小物体的高精度分割。本文从方法论和数据角度都解决了这个具有挑战性的问题(见图 1)。从方法论的角度来看,本文通过堆叠两个深度可分离的卷积(每个卷积具有 1×1 的卷积)以首先缩小然后恢复特征尺寸来开发瓶颈结构。瓶颈结构在不增加参数数量的情况下增加了网络的深度。利用此特性,本文使用提出的瓶颈结构设计 NDNet 进行实时特征提取。从数据的角度出发,受合成物体检测数据集的最新成功以及许多街道图像没有小物体的启发,本文建议增加通过在原始图像中插入其他小物体来训练数据。本文的主要贡献概述如下:
1) 本文提出了 NDNet45 这一实时网络,该网络使用基于卷积的可分离瓶颈结构。然后,本文将 NDNet45 修改为具有学习分数融合的改进的全卷积网络 8(FCN8)结构,并在 8.4G FLOP 的 Cityscapes 测试集上实现了 65.7%的平均相交联盟(mIoU)准确性,在效率上明显优于最新的实时性好的方法。
2) 本文为增强街道场景的小物体,开发了剪切和粘贴策略。如图 1 所示,本文首先从原始的 Cityscapes(OC)数据集中剪切了许多小物体,然后通过在原始训练图像中插入其他小物体来生成合成的 Cityscapes(SC)数据集。
3) 本文的研究显示,使用本文的 SC 数据集进行训练可以显着改善小物体的分割,同时对于实时模型,大物体的分割性能几乎保持不变。特别是,通过使用 SC 数据集训练 NDNet45-FCN8,本文在小物体上的 mIoU 改善了 2.2%。使用本文的 SC 数据集进行训练,对于现有最先进的方法,即金字塔场景解析网络(PSPNet)和 DeepLabV3,本文还可以在小物体上获得平均 2%的 mIoU 改善。
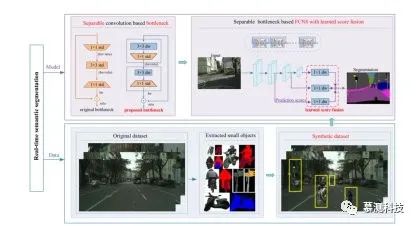
图 1:关于本文的模型和数据驱动的实时语义分割的概述
2. 实时分割架构
尽管深度可分离卷积大大降低了深度学习的计算成本,但考虑到标准卷积的巨大基数,仍有很大的空间可以进一步提高效率。在本节中,本文描述如何将可分解卷积合并到瓶颈结构中以提高深度学习的效率。
A. 实时特征提取

本文基于残差层设计了一个实时特征提取网络。根据功能分辨率,本文将提议的网络分为五个部分。前两个块通过 3×3 卷积层和最大池化层简单堆叠,以快速降低输入分辨率。其余三个块是通过堆叠许多剩余层构成的。表 1 列出了本文网络的详细架构,其中缩写 std,dw,pw 和 conv 分别表示标准,深度,逐点和卷积。本文将其称为骨干网络 NDNet45,因为它采用窄而深的结构并具有 45 个卷积层。
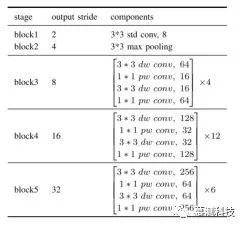
表 1:NDNet45 的结构
B. 实时分割网络
本文的实时分割网络的概述如图 3 所示。通过对最终特征图进行密集的预测,本文的 NDNet45 可以轻松地转换为 FCN32 结构进行语义分割。但是,FCN32 无法捕获足够的空间细节以恢复物体之间的边界。因此,本文将 NDNet45 调整为 FCN8 结构以进行语义分割。
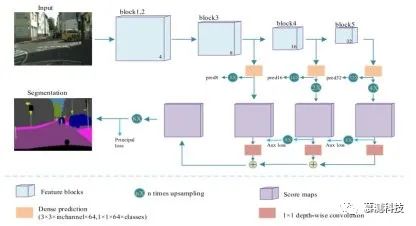
图 3:基于 NDNet 的 FCN8 的体系结构

其中 U(x,i)表示速率为 i 的上采样。
但是,基于重要的观察结果直接对从不同阶段获得的预测分数求和是次优的:不同阶段的特征对于预测不同类别可能是最佳的。特别是,下级的输出适用于可以被较小的接收场覆盖的小型物体。相反,对于不能通过局部特征很好地区分的大型物体类,较高的级输出更好的表示。换句话说,最好将 FCN8 的三个预测分支之一作为特定类的主要分支。因此,本文建议对 FCN8 的三个预测执行加权和。因此,可以将上述方程式转换为以下方程式:
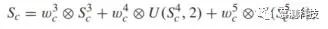

C. 深度监督
为了使 FCN8 的三级预测尽可能准确,本文将深度监督纳入训练损失函数的设计中。本文添加了辅助损耗以监督第 4 阶段和第 5 阶段的预测。本文将辅助损耗乘以权重因子 α,并将其设置为与 PSPNet 相似的 0.4。因此,损失函数为
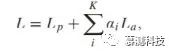 (1)
(1)

3. 增强小物体
本节首先介绍有关街道场景的重要观察结果,这激发了本文对小物体增强的想法。然后,本文描述如何向现有的名为 Cityscapes 的数据集中添加更多小物体。
A. 动机
因为扩充数据集不会增加计算量,而且之前也有研究表示,扩充更多的数据,效果也不一定比改进网络来的少。该观点激发了本文提出的剪切粘贴小物体增强的提议。首先,街道场景数据集的图像可以包含该数据集的所有语义类别,这些语义类别与一般的语义分割数据集不同,本文可以将街道场景的物体添加到街道场景数据集的任何图像中,而无需考虑场景类型的先验。其次,许多街道场景图像包含大范围的非物体类,例如道路和人行道(见图 4)。由于空白区域是物体通常出现的位置,因此直观地将更多小物体粘贴在这些区域上以执行数据扩增。对于此粘贴过程,本文需要从同一数据集中收集许多小物体实例。
B. 小物件的集合
作者定义的小物件:电线杆,交通信号灯,交通标志,骑手,摩托车和自行车。
驾驶场景的重要属性:本文根据驾驶场景的以下三个重要属性提取小物件。
驾驶场景是以自我为中心的,即,物体离摄像机越近,它出现的越大。因此,本文将物体到相机的距离分为三个级别:far,medium_far 和 near。
左侧和右侧物体之间存在差异,尤其是在给定左侧和右侧驱动国家的情况下。因此,本文进一步将小物体分为左物体和右物体。
交通信号灯和交通标志通常放置在电线杆上。
C. 提取小物件的流程
以 pole_traffic 为例,介绍小物体提取流程。如图 4 所示,小物件提取流程可分为三个阶段:
1)poletraffic 的分割:由于训练集中的每个图像都与像素级标签图像相关联,因此通过处理,可以很容易地实现 poletraffic 分割 pole_traffic 的像素为前景像素,所有其他像素为背景;
2)实例分割:可以通过从二进制 poletraffic 分割结果中找到标签连接的组件来区分 poletraffic 的不同实例;
3)实例分类:根据实例的位置将提取的实例分类为上述各种子集。

图 4:小物体提取的流程和合成图像的示例。
D. 小物件的放置
本节介绍如何在 2975 个城市景观的训练图像中插入其他小物体。
先验上下文:本文考虑了在道路行驶场景中存在的两个重要的先验条件,以实现本文在放置小物体时的目标:
1)经常在人行道上找到 pole_traffic。
2)骑摩托车的人通常在马路上,而没有骑摩托车的人通常在人行道上
物体放置:首先,本文根据上述两个上下文先验从人行道或道路上随机选择一个位置来放置小物体。本文观察到这种随机机制很容易导致小物体重叠。尽管在 2D 图像中遮挡是自然的,但是放置的小物体之间的重叠会产生伪影(请参见图 5 中的 SC2),因为这些小物体具有各种姿势,形状和方向。因此,本文反复选择位置以确保有足够的空间放置物体。根据选择的位置(例如,远或近,左或右),从本文的小物体数据集的相应子集中随机采样放置的小物体。由于某些原始图像中可能已经存在许多小物体实例,因此本文将 8 和 5 分别设置为每个合成图像的 poletraffic 和 motorcyclebicycle 实例的最小数量。
4. 实验步骤
A. 实验装置
训练方法:本文直接从零开始在 Cityscapes 上训练了本文的模型,而没有在 ImageNet 上预先训练本文的主干 NDNet45。本文对 NDNet45-FCN8-LF 进行了总共 10 万次迭代训练,批处理大小为 12×1024×1024。本文将基本学习率设置为 0.1,并在 35K,60K 和 80K 迭代后将其除以 10。
优化器和损失函数:本文使用标准的随机梯度下降(SGD)算法(动量为 0.9)训练了所有模型。损失函数由(1)和(2)定义。权重衰减参数设置为 0.0005。标准数据扩充:按照常规做法,本文在训练过程中采用了随机水平镜和[0.75,1,1.25,1.5,1.75,2]中的随机比例。
评估协议:本文使用 mIoU 比较准确性,并使用 FLOP,FPS 的数量比较不同模型的效率。特定类别的 IoU 由下式计算:
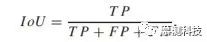
其中 TP,FP 和 FN 分别代表“真正”,“假正”和“假负”像素的数量。测试集上报告的所有结果都是从在线评估服务器上获得的,而 val 集上的结果是通过应用 Cityscapes 作者提供的代码来计算的。
实验环境:本文在配备 Intel Xeon E5-1630(8 核,3.7 GHz)CPU,Titan X(12G)GPU 和 32G RAM 的计算机上进行了所有实验。本文使用 Pytorch 深度学习库训练了模型。
B. NDNet 上的实验
有效性验证:通过将其与流行的 ResNet 中效率最高的网络 ResNet18 进行比较,本文展示了骨干网络 NDNet45 的有效性。为了实现这一目标,本文将其转换为 FCN32 分段架构,并使用 OC 对其进行了培训。表二表明,与 ResNet18 相比,本文的 NDNet45 的 FLOP 减少了 36 倍以上,而 ResNet18 的分辨率是在 1024×2048 分辨率的图像上进行评估的。此外,请注意,本文的网络参数减少了 31 倍以上。为了进一步验证模型的有效性,本文还比较了 NDNet45 和 MobileNetV2。特别是,本文修改了 MobileNetV2 的宽度和深度,以使其共享与 NDNet45 类似的 FLOP。本文已经发布了免费提供的截短的 MobileNetV21 模型。如表二所示,与 MobileNetV2 相比,NDNet45 具有更少的参数和更好的 mIoU,并且具有相似的计算成本。
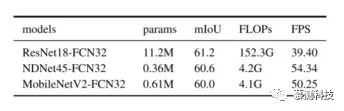
表 2:NDNET45,RESNET18 和截断的 MOBILENETV2 的比较
关于学习融合的消融研究:本文在不使用学习分数融合的情况下实施了基本的 NDNet45-FCN8,并以此为基线。在 8.4G FLOP 的 Cityscapes 验证数据集上,本文的基准达到了 64.0%的 mIoU。接下来,本文将学习的分数融合应用于基线。但是,学习型融合(LF)并不能改善基线的性能,但会产生较差的结果。这主要是因为联合学习融合权重和分割模型可能导致次优融合权重。因此,本文向密集的预测层添加了辅助损耗。这本质上具有使融合和分割的学习脱钩的效果,并且有望大大提高 NDNet45-FCN8-LF 的性能。由于块 4 和 5 的输出步幅分别为 16 和 32,因此本文将附加到这两个块的辅助损耗表示为 auloss16 和 auloss32。表 III 显示,使用 auloss16,NDNet45-FCN8-LF 的性能从 63.2%提高到 64.3%,添加 auloss32 之后,性能进一步提高到 64.6%。但是,将 auloss16 添加到基线会使结果恶化,并且同时添加 auloss16 和 auloss32 只会带来很小的收益。本文将 FCN8 的三个预测分支分别称为 pred8,pred16 和 pred32。为了分析辅助损失如何影响本文模型的结果,本文直接从三个预测分支(参见图 3)进行了细分,然后分别评估了它们的性能。从表 III 中可以看出,对于基本的 FCN8 模型,在添加 auloss16 之后,pred16 取代了 pred32 作为主要的预测分支(具有最佳的 mIoU)。特别是,仅添加 auloss16 显着改善了 pred16 的性能(从 29.7%降至 46.4%),同时使 pred32 的性能降低了近 10 个百分点。这是合理的,因为大部分损失来自 pred16。因此,将 auloss16 添加到基线(在 pred32 起主要作用的位置)会产生较差的结果,这是由于 pred16 的较小接收场导致的上下文丢失。相反,本文学习到的融合仍然可以通过加权融合期间更高的预测来确保 pred32 的稳定性能。
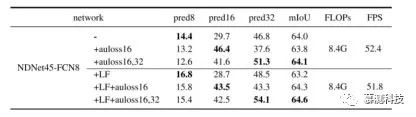
表 3:有无辅助性损失的融合术的消融实验
通用性验证:本文将本文的模型与 Camvid 数据集上的四个实时模型 SegNet,ENet,LinkNet 和 ESPNet 进行了比较,以证明 NDNetFCN8-LF 的通用性。Camvid 是最早了解街景的数据集之一。它具有 11 个用于语义分割的类,以及 367、101 和 233 个图像,分别用于训练,验证和测试。原始图像的分辨率为 960×720。本文采用与这些比较方法类似的方法,对图像进行了 2 倍下采样,以进行公平比较。请注意,ESPNet 的性能是由作者在其发布的代码中报告的。本文以批处理大小 32×360×480 的模型训练了 30K 步的模型。学习率设置为 0.1,然后以 7K,15K 和 20K 步除以 10。所有其他设置与第 V-A 节中提到的设置相同。结果列于表 4,其中使用 SegNet 作者提供的 code3 计算每个类别和 mIoU 的准确性。可以看出,本文的方法优于所有比较方法。与 ENet 相比,本文的模型在六个类别(建筑物,树木,汽车,道路,人行道和骑自行车的人)上获得了更好的 mIoU,并且在 mIoU 上提高了 6.2%。与 SegNet 相比,本文在标志牌,行人,汽车,道路,人行道,自行车手和 mIoU 上取得了更好的结果。图 5 显示了本文的模型与 SegNet 之间的定性比较。可以看出,ENet,SegNet 和本文的方法在小物体上的表现较差,这是本文提出的小物体增强的动机。但是,如表 IV 所示,当将建议的小物体(标志,杆,行人和自行车)应用到 Camvid 时,本文的模型仅获得了较小的改进。这主要是因为许多 Camvid 训练图像包含一个或多个相同姿势的不同物体。结果,在小物体提取阶段重复提取了许多物体,这大大降低了小物体数据集的多样性,从而降低了数据扩增的性能。考虑到 Camvid 的训练图像数量少,这种退化可以进一步扩大。因此,接下来本文在 Cityscapes 数据集上验证了小物体增强的有效性。
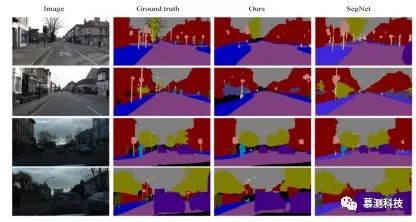
图 5:本文的模型与 Camvid 上的 SegNet 之间的定性比较
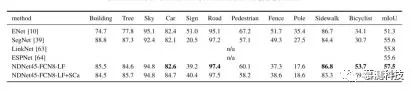
表 4:CAMVID 和合成 CAMVID(SCA)数据集的实验
C. 关于合成 Cityscapes 数据集上的实验
为了验证本文的 SC 数据集的有效性,本文首先在 OC 上训练了 NDNet45-FCN8-LF,然后在三个 SC 数据集上进行了训练:SC1,SC2 和 SC3。结果列于表 5。最后两列显示整体性能和小物体的性能。以下列出了三个重要的观察结果:
1)通过将训练集从 OC 切换到本文的 SC1,NDNet45-FCN8-LF 的整体分割精度(mIoU)从 64.6%提高到 66.4%,小物体的性能从 50.4%提高到 52.6%。定性结果如图 7 所示。定性和定量结果均验证了本文 SC 的有效性。
2)尽管通过将训练集从 OC 更改为 SC2,本文仍然在小物体上获得了较大的性能提升(2.5%),但总体性能提升很小(0.3%)。这主要是因为过度粘贴的小物体会降低其他物体(例如公共汽车和火车)的相对比例。
3)在 SC3 上的培训在 SC1 上显示了相似的结果,再次证明了本文的数据扩增策略的有效性。
结合本文在 NDNet45-FCN8-LF 上进行的实验,可以得出结论,通过使用较少的粘贴小物体,本文可以在小物体的性能和总体性能之间取得更好的平衡。该实验表明,本文的小物体增强不仅适用于实时分割方法,还适用于高质量的分割方法。

表 5:NDNET45-FCN8-LF 在不同训练集上的性能
D. 效率分析
如表 6 所示,在所有比较方法中,本文的方法的 FLOP 最少。在高分辨率(1024×2048)图像上,本文的方法的 FLOP 分别是 ENet,ERFNet 和 IcNet 的 4.14、25.57 和 7.35 倍。
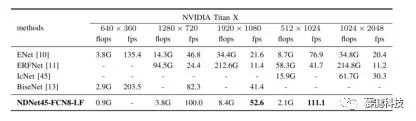
表 6:本文的方法与最新方法之间的效率比较
E. 与最先进方法的比较
最后,本文在 Cityscapes 测试集中评估了本文的方法,以将其与高质量和实时方法进行比较。表 7 显示了比较结果。除以 640×360 分辨率报告 FLOP 的高质量方法外,所有 FLOP 的计算均以表第二栏中列出的分辨率为准。
本文的方法在准确性和效率上都优于早期的基于 VGG 的分割方法。尽管最先进的方法可以实现 80%或更高的分割精度,但由于效率低,它们不适合实时应用。此外,最新方法的分割精度还受益于其他训练数据。由于实际应用通常基于计算资源有限的嵌入式系统,因此,当适应嵌入式系统时,Titan X GPU 上当前实现的大多数推理速度将急剧下降。因此,效率仍然是基于实时深度学习的分割的主要因素。与实时方法 ENet,ShuffleSeg 和 ESPNetV2 相比,本文的方法比 mIoU 分别提高了 3.3、3.3 和 6.9 个百分点,FLOP 分别减少了 4.1 倍,2.1 倍和 1.7 倍。本文的方法在准确性和效率上均优于 CGNet。尽管 ERFNet(68.0%mIoU),BiSeNet(68.4%mIoU)和 IcNet(69.5%mIoU)的准确度比本文的(65.7%mIoU)更好,但本文的方法所需的 FLOP 却比这三种减少了 6.9 倍,1.8 倍和 7.3 倍。此外,本文的综合数据集可用于进一步改善这些方法的性能。本文在图 6 中显示了本文的方法与最新方法之间的定性比较。可以看出,本文的模型可以通过这两种高质量方法获得可比的性能。
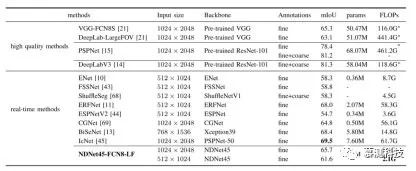
表 7:CITYSCAPES 测试集的比较
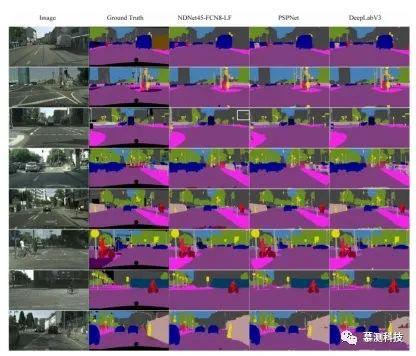
图 6:NDNet45-FCN8-LF 与高质量方法之间的定性比较
5. 总结
本文提出了一种基于深度方向可分离卷积的轻量级残差架构。本文使用拟议的轻量残差层提出了一个实时语义分割模型 NDNet45-FCN8-LF。本文的细分模型在带有 8.4G FLOP 的 Cityscapes 验证集上实现了 64.6%mIoU。为了提高对小物体的分割性能,本文提出了一种用于小物体扩增的剪切粘贴策略。本文将此策略应用于 Cityscapes 并生成了一个综合数据集。通过使用合成 Cityscapes 进行训练,本文模型的整体性能和小物体上的性能分别提高了 1.8%和 2.2%mIoU。此外,本文的实验表明,合成数据集可用于提高诸如 PSPNet 和 DeepLabV3 之类的高质量语义分割方法的性能。最终,本文通过 8.4G FLOP 在 Cityscapes 测试仪上实现了 65.7%的 mIoU,其准确性或效率均超过了现有的最新技术水平。
致谢
本论文由 iSE 实验室 2021 级硕士生倪泽栋转述。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









