






当你像我一样遇到了极其让人头疼的表格数据整理任务
作者本人最近需要合并并整理一堆小表格,如果用一个字来形容这些数据的话,那就必须是“乱”。
他们是有多乱呢?
- 两个需要合并的表格中的行名(列名)常常不一样,一个表格中对于同一个东西的描述也会用两个词。比如说一个地方出现了列名“苹果”,另外一个地方就变成“苹果树”了。坑爹啊,我还要一个一个的去对照这些表格里面的名字。
- 记录数据的人还把一个列名中的单位和统计量分成两个单元格子,导致我还需要写excel公式把他们合并到一起。为什么这些人做数据的时候,就不能直接写“作物产量(吨)”,而非要把他们分到两列单元格中呢?
- 而且当列名中有层次关系的时候,都是用的“一”,‘1’,甚至“#”和空格来表示层次结构的啊。真的服了,这些人都是excel爱迪生吧?这么说你可能不懂,下面图片中是一个例子:
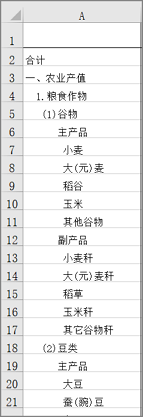
- 行名和列名中不仅乱用空格,还能有换行符啊。这些人真的是手眼通天啊,“alt+enter”进行单元格内编辑换行这么冷门的技能都掌握了,为什么不把表格做规范一点啊?
正因为它们是如此的小而乱,使得我完全不能用python脚本遍历一个目录中的所有表格,并对表格进行全自动化预处理(我甚至连他们的文件名和sheet名都一口气背不下来)。
那么这个时候你就需要借助xlwing实现最快速读写表格数据了
xlwing是什么:
它除了能够像pandas一样在python环境中读写excel文件,还能够在windows平台上,给excel添加python宏功能。有了它,我们就能够在Excel的单元格的公式输入中,将我们的python函数当作普通的excel内置函数嵌入我们的公式,从而实现python与excel合而为一后便捷而强大的即时编辑功能。
说明:关于xlwing的安装和配置以及基本用法可以参考本专栏之前的文章。
一句话概括使用过程
先在excel的某个单元格写下一个我们的公式read_df(xxx)。其中的xxx代表着单元格区域的表示。如下图:
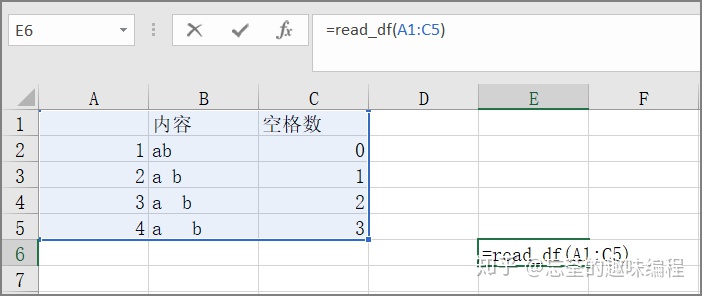
写完上述公式之后按下回车,就能在指定的pkl文件中记录下这个dataframe。我们只需要在python中读取这个pkl并在交互性命令行中处理这个表格,最后使用dataframe的to_clipboard()方法来把整理好的数据写入粘贴板,之后回到excel的某个单元粘贴就 ok了。
如何实现上述效果
1.首先需要在xlwing工程中的python文件中实现读取excel选定区域功能的函数:
import 然后在pycharm启动该文件的debug。
2,在excel的某个单元格写下一个我们的公式read_df(xxx)。其中的xxx代表着单元格区域的表示。然后按下【Ctrl+回车】执行公式,自动将该区域作为一个表格读入pkl文件。
3,在python中读取这个pkl文件并进行我们需要的数据预处理操作。
df 4, 使用dataframe的to_clipboard()方法来把整理好的数据写入粘贴板,之后回到excel的某个单元进行粘贴。
重复以上过程就能超快速地进行excel和python中数据的交换啦~
参考
除了用到的各种工具软件的官方文档。我还主要参考了这篇博客。文章中介绍了很多读写使用python读写excel的方法,我个人实践总结后就有了这篇文章。















 420
420

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









