






问题描述
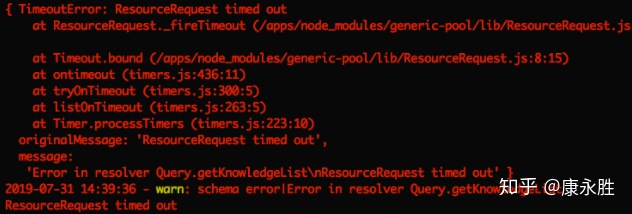
线上服务不定时出现“ResourceRequest timed out”错误,导致部分用户无法正常使用业务洗系统,每次重新启动服务之后问题消失,若干小时之后又会出现同样的问题。服务器错误日志如下图所示:
问题排查过程
第一步,尝试线上复现问题,最终失败,因为一重启服务问题就消失,无法在线上稳定复现,所以尝试在本地复现问题。
第二步,通过查看线上错误日志,初步估计是连接池问题,所以阅读Sequelize的数据库连接池管理组建generic-pool的源码,发现当上层应用从资源池中请求资源(数据库连接),且资源池管理程序不能在规定的时间内分配一个资源(数据库连接)的话,就会产生“ResourceRequest timed out”错误。
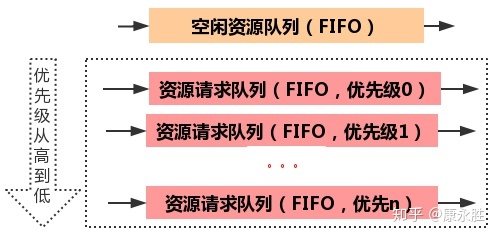
generic-pool的资源池管理原理如下,连接池中有两类队列:“空闲资源队列”和“资源请求队列”,资源请求队列又根据不同的优先级分成多个队列,当出现资源竞争的时候,会将资源优先分配给优先级高(数值小)的队列,队列内部采用FIFO策略,如下图所示:
第三步:猜测问题,可能是线上数据库查询操作频繁,数据库连接池中的连接数量较少(当时为最多10个连接),导致部分请求在等待分配数据库连接的时候发生超时。
定量验证猜测:
设 queryTime 表示平均每个sql查询的耗时,单位 毫秒
设 connNum 表示连接池中的数据库连接个数
设 sqlCapacityRate 表示客户端感受到的数据库查询吞吐速率,单位 次/s
设 sqlFlowRate 表示业务需要执行sql的速率,单位 次/s
设 acquire 表示一条sql查询在获取连接资源之前的最长等待时间,单位 秒
设 t 表示当sqlFlowRate 大于 sqlCapacityRate 时,连接资源请求超时的系统最短运行时间,单位 秒
则:
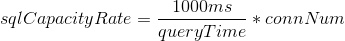

如果: queryTime = 200ms(从发起查询到最终获得数据释放连接资源的时间),connNum = 10(线上的连接池数量),则 sqlCapacityRate = 50次/秒(每一秒可以执行50个sql),sqlFlowRate = 51次/秒(正好超出sqlCapacityRate,会引起请求堆积),acquire = 10s(sequelize的默认值)
那么:t = 500s < 10min,也就是说,系统持续在这个负载下运行10分钟就会开始出现超时异常。
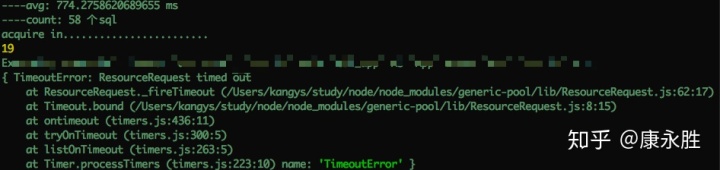
第四步:在本地复现问题,以下Node.js代码可以稳定复现出问题:
const 某一次问题复现的记录,执行了58个sql就产生了资源分配等待超时的现象:
解决问题方式与思路
- 将客户端连接池的连接数量上限调整的大一些(线上从10调整到了20)。
- 将客户端连接池的数量下限调整的大一些,当服务空闲时依然保留一定的连接,应对突发流量(向上从1调整到了10)。
- 尽可能利用缓存,减少对数据库的查询(这是个业务和架构持续优化的过程)。
- 重视慢sql,重构所有的慢sql。一个慢sql除了消耗数据库服务器的资源外,也一直占用着客户端的连接。
- 使用完一个数据库连接后,尽快释放给管理池。















 856
856











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









