





如果一个HTML网页中有表格,怎样爬取下来?
Pandas的read_html可以很方便的解析URL地址或者HTML代码中的表格,直接转换成dataframe,用于后续的处理、分析、导出。
比如有这么一个案例,我自己经常使用网易有道词典查英文单词,经常将新单词加入到单词本,日积月累单词就越来越多,我想把这些单词都导出到excel,怎样可以集中复习甚至打印出来看。
可是网易有道词典没这个导出全部单词本的功能。
幸好,我在网易有道有道的PC版,发现了这样的单词本网页:

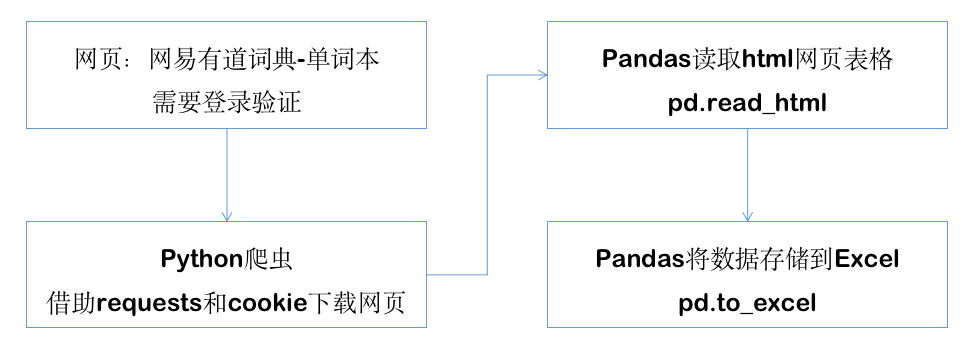
使用这样的技术组合,我可以很简单的爬取整个网页,并实现表格解析,输出到Excel文件:
Python爬虫,使用requests下载网页,其中的cookies参数能让我绕过登录验证;
Pandas的read_html能解析出来网页中的表格,然后使用to_excel能将结果保存成excel文件
流程是这样的:
而最终保存的excel,就是我要的所有单词列表:

Python爬虫+Pandas数据解析处理的绝佳搭档,请看视频演示:
本视频是我系列视频的一集,视频全集请在爱奇艺搜索“Python使用Pandas入门数据分析”查看:

喜欢本文的朋友,可以关注公众号,观看更多Python领域的技术视频:
















 1015
1015











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









