






之前用python写爬虫,都是自己用requests库请求,beautifulsoup(pyquery、lxml等)解析。没有用过高大上的框架。早就听说过Scrapy,一直想研究一下。下面记录一下我学习使用Scrapy的系列代码及笔记。
安装
Scrapy的安装很简单,官方文档也有详细的说明 http://scrapy-chs.readthedocs.io/zh_CN/0.24/intro/install.html 。这里不详细说明了。
创建工程
我是用的是pycharm开发,打开pycharm,然后在下面的“Terminal”中输入命令“scrapy startproject freebuf”。这句话是在你的工作空间中创建一个叫“freebuf”的scrapy工程。如下图:
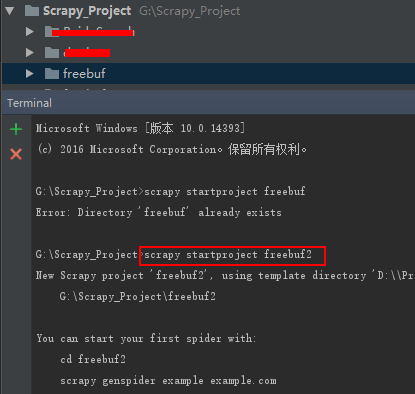
上图中,因为我的工作空间中已经存在“freebuf”所以第一次创建失败,这里我创建的名字为"freebuf2",创建成功。freebuf2的目录及说明如下:

编写爬虫
freebuf2Spider.py
选中“spiders”文件夹,右键“NEW”->"Pyth
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3292
3292











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









