






VBA 实践(1)——通过word vba 辅助修改大量pdf数据
项目说明:
有约1000页pdf的文件的数据需要修改。Pdf含文字层,可通过acrobat pro等编辑功能修改。
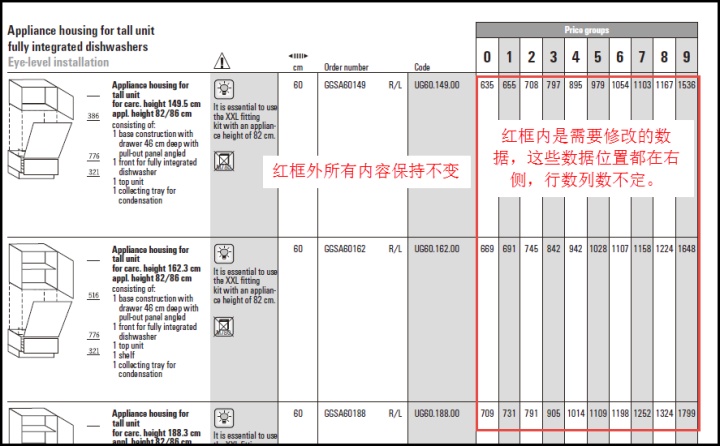
修改要求为:将所有数据放大1.6倍,并替换原数据,字体字号位置等应该尽量保持与原来一致。要求修改的数据分布在每个页面的右侧,行数列数不定,除了要修改的部分外,其他地方需要保持原样。数据有的是整数、有的含一位小数,有的含两位小数,修改后的数据要求保留一样的小数位数。数据如下图所示,红框内是要求修改的数据。
项目方案:
Pdf格式是一种便携式支持跨平台的,着重于保持版面效果的格式,不是一种便于修改的格式,它的文字编辑功能较弱,更没有提供数学运算的功能。它的修改是基于板块的,而不是文字。
在pdf文件里一个一个地修改,耗时会非常长,且容易出错。不但计算容易出错,而且格式位置也容易出错,且难以调整。
根据自身能力及情况,制定这样的方案。
第一步,把pdf文件中的需要修改的数据提取出来,放到word中,其他不需要修改的地方不动。
第二步,在word中对数据进行修改,并调整格式,导出为pdf文件
第三步,以页为单位,对原pdf的数据进行手工替换。
第一步:如何快速地提取需要修改的数据?
Pdf是含有文字层的,可以直接导出为.docx、.xls等文档。可以尝试利用acrobat pro直接导出为.docx,但是只能全部导出,不能选择部分数据导出。导出效果如下图所示。
这是使用acrobat pro 9转换出来的word文档,总体效果较差,出现了较多的分栏符、分节符、制表符等标志符,文档结构复杂难改。①处本来是有图像的,但丢失了;②处是有表格线及灰色相间的条纹的,但也丢失了,而且数据不是用表格来组织的。
这样的文档需要修改成符合要求的文档,工作量是非常大的,主要的困难体现在两方面:一需要补充丢失的图像、表格线,重新排版;二需要排除其他内容的干扰,才能准确地对数据进行更改。
如果转换为excel文档,更改数据方面会方便一点,但排版方面会更麻烦。直接转换的方法困难重重。

还有另一个方法——使用Abbyy finereader进行识别转换。
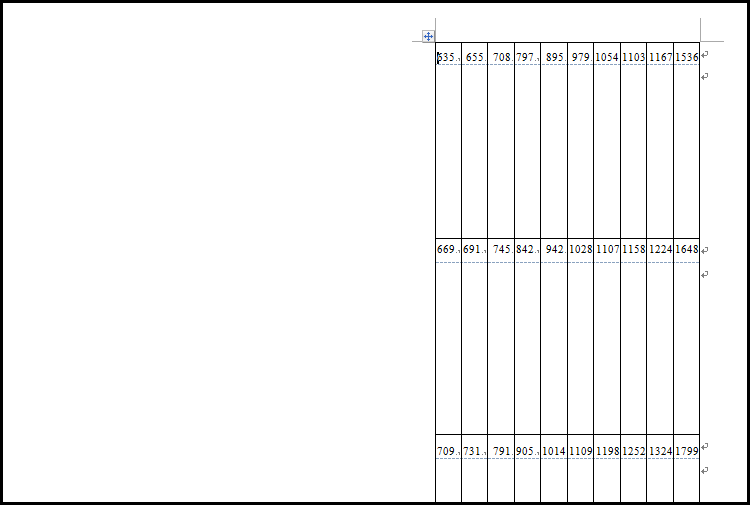
Abbyy finereader可以对pdf文档进行识别,最重要的是通过布置识别区域可以只对页面的某部分进行识别,避免引入其他需要保持原样的部分。识别并导出的word文档数据如下图所示。
因为需要更改的区域在页面中的位置是固定的,所以识别区域可以进行批量设置,大大提高了效率。数字识别正确率非常高,几乎是100%。数据是以表格的形式组织的,这非常有利于后续的数据自动化更改。表格的宽度与每列的宽度与原pdf是一致的,减少了后面格式排版的工作量。
到现在,已经可以快速地提取需要的数据了。接下来就是批量更改数据,并进行排版。
第二步:修改数据,调整格式,生成pdf
批量修改数据,当然是使用vba写个小程序方便啦。
在修改数据方面,显然在excel里面修改会更为方便,但是排版格式并不好调整。想到vba在word和excel里面都是可以使用的,而word是擅长排版的,所以在word里面处理数据可以兼具批量更改数据和格式排版的便利。
批量更改数据的vba代码如下:
Sub 放大数据并修改格式()
Dim c, x, ws
Dim mystr As String
Const fangd1 = 1.6 '声明一个常量
x = 0
Application.ScreenUpdating = False '关闭屏幕刷新
'外循环体(每一个表格循环)
For Each ws In ActiveDocument.Tables
'内循环体(表格内每一个单元格循环)
For Each c In ws.Range.Cells
mystr = Left(c.Range.Text, Len(c.Range.Text) - 2) '去除单元格的隐含字符
'数值形式的判断,首先判断两位小数,然后判断一位小数,剩下的为整数。
If mystr Like "*.##" Then
c.Range.Text = Format(Round(Val(mystr) * fangd1, 2), "#0.00")
ElseIf mystr Like "*.#" Then
c.Range.Text = Format(Round(Val(mystr) * fangd1, 2), "#0.0")
ElseIf mystr <> "" Then
c.Range.Text = Round(Val(mystr) * fangd1, 0)
ElseIf mystr = "" Then
c.Range.Text = "-"
End If
Next c
x = x + 1
Next ws
Application.ScreenUpdating = True '开启屏幕刷新
MsgBox "共修改了" & x & "个表"
End Sub代码在编写的过程中,遇到了判断条件不起作用的问题。在判断时直接使用了c.Range.Text Like "*.##"进行判断,而没有注意到word表格中每个单元格末尾其实都有两个隐含的字符,导致判断条件不起作用。后来得到了知友TuskAi的帮助,顺利地解决了问题。他还提示我使用Format函数对数据形式进行限定,以防止末尾小数0被忽略,而使小数位数不对。在此对他表示感谢!
还有,如果Format函数的参数写为"#.00"时,那么小于的1的小数个位数上的0会被忽略,比如0.12会变成.12。所以参数要写成"#0.00"。
调整数据格式
调整数据格式也可以使用vba代码。首先需要到原pdf中获取相关参数,比如字体、字号、行高等。格式修改的代码都可以通过录制宏的方式得到,Vba代码如下。
ws.Select
'修改字体格式
With Selection.Font
.NameFarEast = ""
.NameAscii = "U001Con"
.NameOther = "U001Con"
.Name = ""
.Size = 9
End With
'修改段落格式
With Selection.ParagraphFormat
.LeftIndent = CentimetersToPoints(0)
.RightIndent = CentimetersToPoints(0)
.SpaceBefore = 0
.SpaceBeforeAuto = False
.SpaceAfter = 0
.SpaceAfterAuto = False
.LineSpacingRule = wdLineSpaceSingle
.Alignment = wdAlignParagraphCenter
.FirstLineIndent = CentimetersToPoints(0)
.OutlineLevel = wdOutlineLevelBodyText
.CharacterUnitLeftIndent = 0
.CharacterUnitRightIndent = 0
.CharacterUnitFirstLineIndent = 0
.LineUnitBefore = 0
.LineUnitAfter = 0
.WordWrap = True
End With
'修改表格格式
Selection.Rows.HeightRule = wdRowHeightExactly
Selection.Rows.Height = CentimetersToPoints(0.454)
Selection.Cells.VerticalAlignment = wdCellAlignVerticalCenter
Selection.Shading.Texture = wdTextureNone
Selection.Shading.ForegroundPatternColor = wdColorAutomatic
Selection.Shading.BackgroundPatternColor = wdColorAutomatic
'均布列
Selection.Cells.DistributeWidth
'边框修改
Selection.Borders(wdBorderTop).LineStyle = wdLineStyleNone
Selection.Borders(wdBorderLeft).LineStyle = wdLineStyleNone
Selection.Borders(wdBorderBottom).LineStyle = wdLineStyleNone
Selection.Borders(wdBorderRight).LineStyle = wdLineStyleNone
Selection.Borders(wdBorderHorizontal).LineStyle = wdLineStyleNone
Selection.Borders(wdBorderVertical).LineStyle = wdLineStyleNone
Selection.Borders(wdBorderDiagonalDown).LineStyle = wdLineStyleNone
Selection.Borders(wdBorderDiagonalUp).LineStyle = wdLineStyleNone
With Options
.DefaultBorderLineStyle = wdLineStyleSingle
.DefaultBorderLineWidth = wdLineWidth050pt
.DefaultBorderColor = wdColorAutomatic
End With
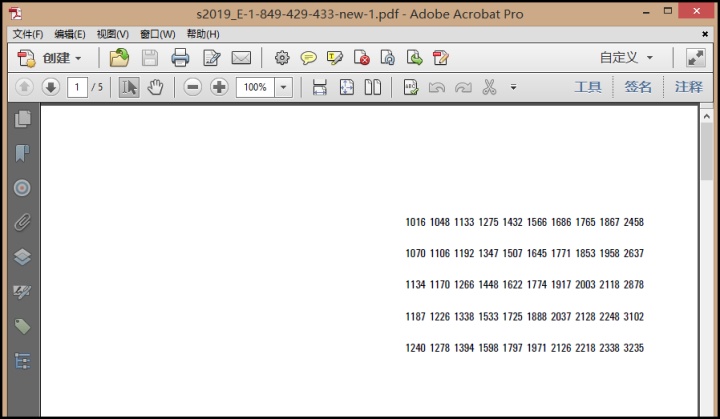
Next ws数据处理完后,导出pdf。效果如下图所示。字体、字号、列宽、行高都可以和原pdf文档吻合。
第三步,以页为单位,对原pdf的数据进行手工替换。
接下来的任务就是把转换出来的修改好的数据替换原pdf中的数据。没有找到高效替换的方法,只能以页为单位,手工复制粘贴,然后调整位置,过程如下图所示。
这一步是机械重复的、非常耗时的。
不知道有没有什么方法可以提高这一过程的效率。

将近1000页的pdf文档,最终用时7天完成修改。时间很大一部分花在了第三步。如果没有第二步使用vba代码提高效率,恐怕时间还要翻倍,甚至更长。
学好vba还是很有用的!















 5980
5980

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









