







前情提要:通俗地说决策树算法(一)基础概念介绍
一. 概述
上一节,我们介绍了决策树的一些基本概念,包括树的基本知识以及信息熵的相关内容,那么这次,我们就通过一个例子,来具体展示决策树的工作原理,以及信息熵在其中承担的角色。
有一点得先说一下,决策树在优化过程中,有3个经典的算法,分别是ID3,C4.5,和CART。后面的算法都是基于前面算法的一些不足进行改进的,我们这次就先讲ID3算法,后面会再说说它的不足与改进。
二. 一个例子
众所周知,早上要不要赖床是一个很深刻的问题。它取决于多个变量,下面就让我们看看小明的赖床习惯吧。
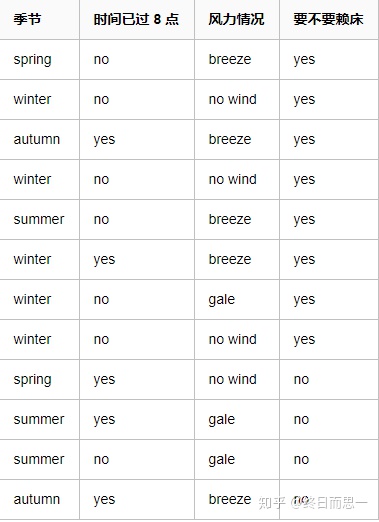
OK,我们随机抽了一年中14天小明的赖床情况。现在我们可以根据这些数据来构建一颗决策树。
可以发现,数据中有三个属性会影响到最终的结果,分别是,季节,时间是否过8点,风力情况。
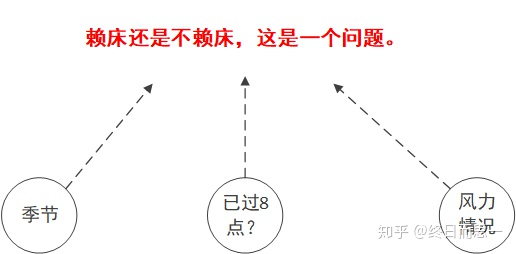
要构建一颗决策树,首先我们要找到它的根,按照上一节所说,我们需要计算每一个属性的信息熵。
在计算每一个属性的信息熵之前,我们需要先根据历史数据,计算没有任何属性影响下的赖床信息熵。从数据我们可以知道,14天中,有赖床为8天,不赖床为6天。则
p(赖床) = 8 / 12.
p(不赖床) = 6 / 12.信息熵为
H(赖床) = -(p(赖床) * log(p(赖床)) + p(不赖床) * log(p(不赖床))) = 0.89接下来就可以来计算每个属性的信息熵了&#
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 459
459











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









