






urllib库主要有4个模块。
1、urllib.request:打开和读取 URL
2、urllib.error:包含 urllib.request 抛出的异常
3、urllib.parse:用于解析 URL
4、urllib.robotparser:用于解析 robots.txt 文件
1、urllib.request:打开和读取 URL
(1)urlopen()方法
语法:
urllib.request.urlopen(url,data=None,[timeout,]*,cafile=None,capath=None,cadefault=False,context=None)
#()里网址要用单引号''百度为例('https://www.baidu.com/')
参数:
url:目标资源在网路中的位置。可以是一个表示URL的字符串(如:http://www.pythontab.com/);也可以是一个urllib.request对象,详细介绍请跳转;
data:data用来指明发往服务器请求中的额外的参数信息(如:在线翻译,在线答题等提交的内容),data默认是None,此时以GET方式发送请求;当用户给出data参数的时候,改为POST方式发送请求;
timeout:设置网站的访问超时时间;
cafile、capath、cadefault:用于实现可信任的CA证书的HTTP请求。(基本上很少用)
context参数:实现SSL加密传输。(基本上很少用)
#调用方法1(失败-会报错误)
import urllib
urllib.request.urlopen()
#调用方法2
from urllib import request
request.urlopen()
#调用方法3
import urllib.request
urllib.request.urlopen()
#相等的写法:把urllib.request.urlopen()简写成r或者任意不与(Python保留字符)冲突的字母
with urllib.request.urlopen() as r:
r = urllib.request.urlopen()
#打印内容加编码方式
r = urllib.request.urlopen()
print(r.read(数字).decode('utf-8'))#使用read()方法
print(r.status)#使用status属性
通过输出结果可以发现它是一个HTTPResposne类型的对象,它主要包含以下方法和属性
HTTPResposne类型的对象方法:
read() , readline() ,readlines() , fileno() , close() :对HTTPResponse类型数据进行操作;
info():返回HTTPMessage对象,表示远程服务器返回的头信息;
getcode():返回Http状态码。如果是http请求,200请求成功完成;404网址未找到;
geturl():返回请求的url;
HTTPResposne类型的对象属性:
status,msg,version,reason,debuglevel,closed
(2)Request()
urlopen()方法中没有请求头参数,使用request()来包装请求,再通过urlopen()获取页面。
为什么要加入请求头信息?简而言之,在部分网站,没有请求头信息不让你浏览内容。
语法:
urllib.request.Request(url, data=None, headers={}, origin_req_host=None, unverifiable=Flase, method=None)
参数:
url:必传参数,用于请求URL;
data:可选参数,必须传bytes(字节流)类型的。如果是字典,先用urllib.parse模块里的urlencode()编码;
headers:请求头,字典类型,
origin_req_host:请求方的host名称或者IP地址;
unverifiable:表示这个请求是否是无法验证的,默认是Flase,意思就是说用户没有足够权限来选择接收这个请求的结果;
method:字符串,用来指示请求使用的方法,比如GET、POST和PUT等;
from urllib import parse
from urllib import request
url = 'https://www.baidu.com/'
data = bytes(urllib.parse.urlencode({'hello': 'word'}), encoding='utf8')
headers = {
填入请求头内容
注意格式:'User-Agent':'Mozilla/5.0
}
r1 = request.Request(url, headers=headers, data=data)
r= request.urlopen(r1)
#r1中包含请求头信息,使用request.Request()包装完成
如何找到请求头信息?在Request Headers 里面。注意格式。
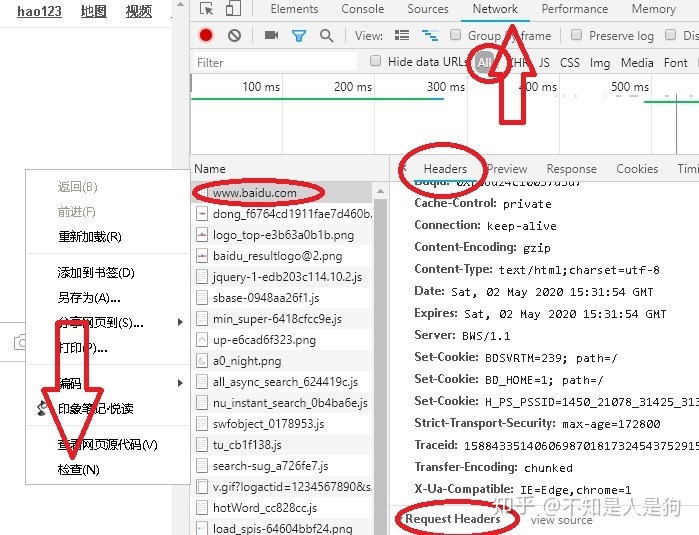
(3)高级用法
我不会。以后补充。
2、urllib.error:包含 urllib.request 抛出的异常
(1)urllib.error.URLError
处理程序在遇到问题时会引发此异常(或其派生的异常)。 它是 OSError 的一个子类。
属性:reason
此错误的原因。 它可以是一个消息字符串或另一个异常实例。
from urllib import request,error
try:
respone = request.urlopen('wwww')
except error.URLError as e:
print(e.reason)#属性:reason 的应用(2)urllib.error.HTTPError
虽然是一个异常(URLError 的一个子类),HTTPError 也可以作为一个非异常的文件类返回值(与urlopen() 返所回的对象相同)。 这适用于处理特殊 HTTP 错误例如作为认证请求的时候。
属性1:code
一个 HTTP 状态码
属性2:reason
这通常是一个解释本次错误原因的字符串。
属性3:headers
导致 HTTPError 的特定 HTTP 请求的 HTTP 响应头。
from urllib import request,error
try:
respone = request.urlopen('wwww')
except error.HTTPError as e:
print(e.reason,e.code,e.headers)#属性123的应用因为 URLError 是 HTTPError 的父类,所以可以先选择捕获子类的错误,再去捕获父类的错误,所 以上述代码更好的写法如下:
from urllib import request,error
try:
respone = request.urlopen('wwww')
except error.HTTPError as e:
print(e.reason,e.code,e.headers)
except error.URLError as e:
print(e.reason)
else:
print('什么都好')3、urllib.parse:用于解析 URL
1. urlparse()
用法:
urllib.parse.urlparse(urlstring,scheme='',allow_fragments=True)
将URL解析为六个组件,返回一个6项命名元组。每个元组项目都是一个字符串,可能是空的。组件不会被分解成较小的部分(例如,网络位置是单个字符串),并且%转义不会被展开。上面所示的分隔符不是结果的一部分,除了路径组件,如果存在,则保留该组件。
#通俗的说:将网址分为6个部分。分别是 scheme、 netloc、 path、 params 、 query 和 fragment。
#这与URL的一般结构相对应:scheme://netloc/path;parameters?query#fragment。
参数:
urlstring:这是必填项,即待解析的 URL。
scheme='':它是默认的协议(比如 http 或 https 等), 假如这个链接没有带协议信息,会将这个作为默认的协议。
allow_fragments::即是否忽略fragment,如果它被设置为False,fragment部分就会被忽略, 它会被解析为 path、 parameters 或者 query 的一部分,而 fragment 部分为空。
scheme 参数只有在url中不包含scheme信息时才生效,如果url中有 scheme 信息, 就会返回解析出的 scheme。
返回结果 ParseResult 实际上是一个元组,我们可以用索引顺序来获取,也可以用属性名获取。
from urllib.parse import urlparse
o = urlparse('http://www.cwi.nl:80/%7Eguido/Python.html')
print(o)
ParseResult(scheme='http', netloc='www.cwi.nl:80', path='/%7Eguido/Python.html', params='', query='', fragment='')
print(type(o))
<class 'urllib.parse.ParseResult'>
print(o.scheme,o[0],o.netloc,o[1])#我们可以用索引顺序来获取,也可以用属性名获取。
2. urlunparse() :反向的urlparse()
它接受的参数是一个可迭代对象, 但是它的长度必须是 6, 否则会抛出参数数量不足或者过多的问题。
from urllib.parse import urlunparse
data = ['htp','wwww.baidu.com','index.html','user','a=6','comment']
print(urlunparse(data))3. urlsplit()
这个方法和 urlparse()方法非常相似, 只不过它不再单独解析 params 这一部分,只返回 5 个结果。 上面例子中的 params 会合并到 path 中。
from urllib.parse import urlsplit
r = urlsplit('http://www.baidu.com/index.html;user?id=S#comment')
print(r)
SplitResult(scheme='http', netloc='www.baidu.com', path='/index.html;user', query='id=S', fragment='comment')
4. urlunsplit() :反向的 urlsplit()
与 urlunparse()类似,它也是将链接各个部分组合成完整链接的方法,传人的参数也是一个可迭 代对象,例如列表、 元组等,唯一的区别是长度必须为 5。
from urllib.parse import urlunsplit
data = ['htp','wwww.baidu.com','index.html','a=6','comment']
print(urlunsplit(data))
htp://wwww.baidu.com/index.html?a=6#comment5. urljoin()作用:生成链接
我们可以提供一个 base_url(基础链接 ) 作为第一个参数,将新的链接作为第二个参数,该方法会分析 base_url 的 scheme、 netloc 和 path 这 3 个内容并对新链接缺失的部分进行补充,最后返回结果。
缺代码实例,很繁琐,懒得打。base_url 提供了三项内容 scheme、 netloc 和 path。 如果这 3 项在新的链接里不存在, 就予以补充;如果新的链接存在,就使用新的链接的部分。 而 base_url 中的 params 、 query 和 fragment 是不起作用的。
6. urlencode()
它在构造 GET 请求参数的时候非常有用。
from urllib.parse import urlencode
params = {
'name':'germey',#注意这个后面有个逗号
'age': 22
}
base_url = 'http://www.baidu.com?'
url = base_url + urlencode(params)
print(url)
http://www.baidu.com?name=germey&age=227. parse_qs()
反序列化。 转回为字典类型。
from urllib.parse import parse_qs
query= 'name=germey&age=22'
print(parse_qs(query))
{'name': ['germey'], 'age': ['22']}
8. parse_qsl()
反序列化。 转回为元组类型。
from urllib.parse import parse_qsl
query= 'name=germey&age=22'
print(parse_qsl(query))
[('name', 'germey'), ('age', '22')]9. quote()
将内容转化为 URL编码的格式。 URL 中带有中文参数时,有时可能会导致乱码的问题,此时用这个方法可以将文字符转化为 URL编码
from urllib.parse import quote
keyword = '壁纸'
url ='https://www.baidu.com/s?wd=' + quote(keyword)
print(url)
https://www.baidu.com/s?wd=%E5%A3%81%E7%BA%B810. unquote()
将URL编码转化为文字。反向quote()
from urllib.parse import unquote
url = 'https://www.baidu.com/s?wd=%E5%A3%81%E7%BA%B8'
print(unquote(url))
https://www.baidu.com/s?wd=壁纸4、urllib.robotparser:用于解析 robots.txt 文件
个人感觉Robots协议用处不大
法律方面可能有用吧。














 1046
1046











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









